
In a tech-driven field, staying updated isn’t an option—it’s essential. At Grab, we’re committed to providing top-notch technology services. However, keeping pace can be demanding. At one point in time, our GitLab instance was trailing by roughly 14 months of releases. This blog post recounts our experience updating and formulating a consistent upgrade routine.
Recognising the need to upgrade
Our team, while skilled, was still learning GitLab’s complexities. Regular stability issues left us little time for necessary upgrades. Understanding the importance of upgrades for our operations to get latest patches for important security fixes and vulnerabilities, we started preparing for GitLab updates while managing system stability. This meant a quick learning and careful approach to updates.
The following image illustrates the version discrepancy between our self-hosted GitLab instance and the official most recent release of GitLab as of July 2022. GitLab follows a set release schedule, issuing one minor update monthly and rolling out a major upgrade annually.
Addressing fears and concerns
We were concerned about potential downtime, data integrity, and the threat of encountering unforeseen issues. GitLab is critical for the daily activities of Grab engineers. It serves a critical user base of thousands of engineers actively using it, hosting multiple mono repositories with code bases ranging in size from 1GB to a sizable 15GB. When taking into account all its artefacts, the overall imprint of a monorepo can extend to an impressive 39TB.
Our self-hosted GitLab firmly intertwines with multiple critical components. We’ve aligned our systems with GitLab’s official reference architecture for 5,000 users. We use Terraform to configure complete infrastructure with immutable Amazon Machine Images (AMIs) built using Packer and Ansible. Our efficient GitLab setup is designed for reliable performance to serve our wide user base. However, any fault leading to outages can disrupt our engineers, resulting in a loss of productivity for hundreds of teams.
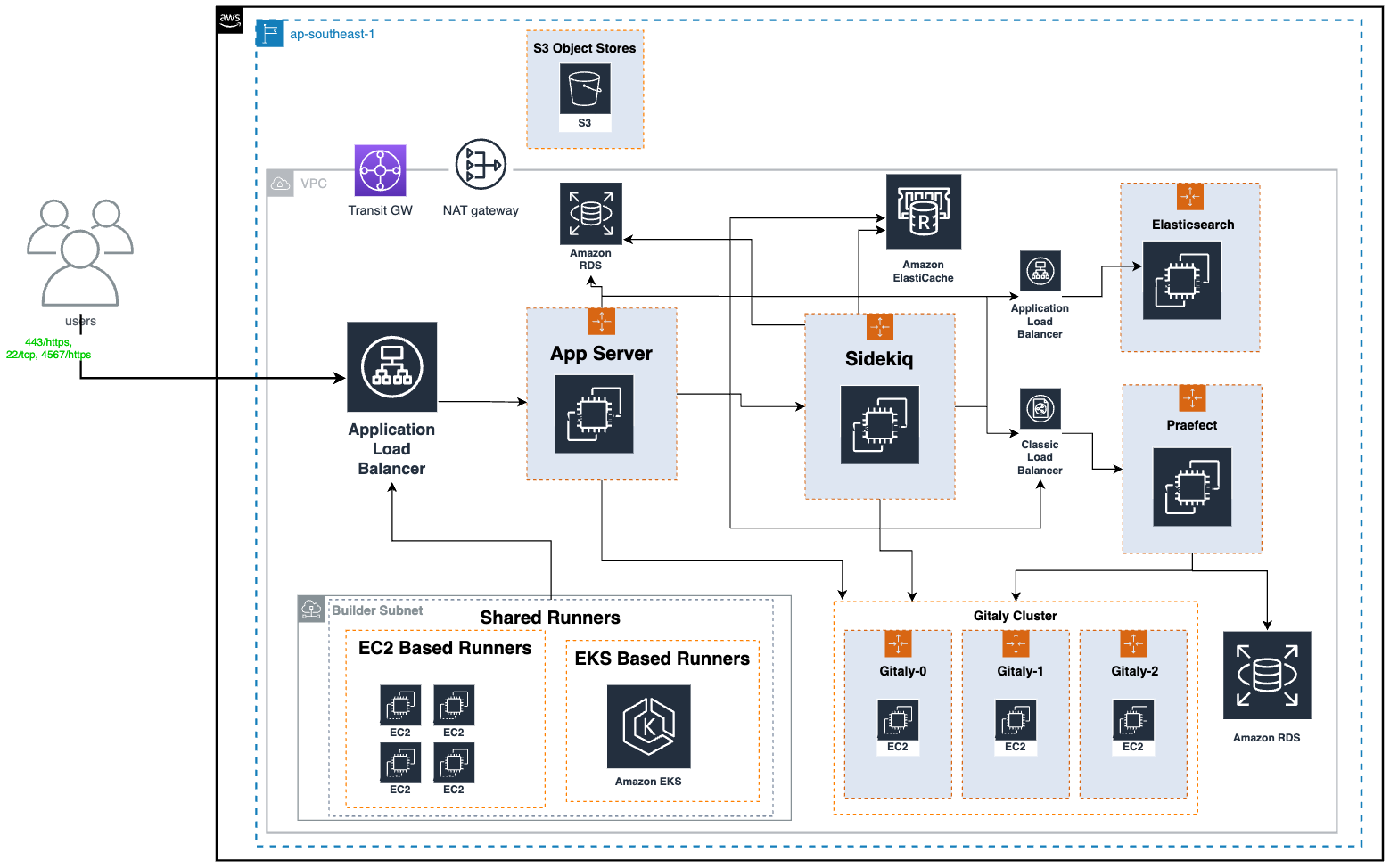
The above is the top level architecture diagram of our GitLab infrastructure. Here are the major components of the GitLab architecture and their functions:
- Gitaly: Handles low-level Git operations for GitLab, such as interacting directly with the code repository present on disk. It’s important to mention that these code repositories are also stored on the same Gitaly nodes, using the attached Amazon Elastic Block Store (Amazon EBS) disks.
- Praefect: Praefect in GitLab acts as a manager, coordinating Gitaly nodes to maintain data consistency and high availability.
- Sidekiq: The background processing framework for GitLab written in Ruby. It handles asynchronous tasks in GitLab, ensuring smooth operation without blocking the main application.
- App Server: The core web application server that serves the GitLab user interface and interacts with other components.
The importance of preparation
Recognising the complexity of our task, we prioritised careful planning for a successful upgrade. We studied GitLab’s documentation, shared insights within the team, and planned to prevent data losses.
To minimise disruptions from major upgrades or database migrations, we scheduled these during weekends. We also developed a checklist and a systematic approach for each upgrade, which include the following:
- Diligently go through the release notes for each version of GitLab that falls within the scope of our upgrade.
- Read through all dependencies like RDS, Redis, and Elasticsearch to ensure version compatibility.
- Create documentation outlining new features, any deprecated elements, and changes that could potentially impact our operations.
- Generate immutable AMIs for various components reflecting the new version of GitLab.
- Revisit and validate all the backup plans.
- Refresh staging environment with production data for accurate, realistic testing and performance checks, and validation of migration scripts under conditions similar to the actual setup.
- Upgrade the staging environment.
- Conduct extensive testing, incorporating both automated and manual functional testing, as well as load testing.
- Conduct rollback tests on the staging environment to the previous version to confirm the rollback procedure’s reliability.
- Inform all impacted stakeholders, and provide a defined timeline for upcoming upgrades.
We systematically follow GitLab’s official documentation for each upgrade, ensuring compatibility across software versions and reviewing specific instructions and changes, including any deprecations or removals.
The first upgrade
Equipped with knowledge, backup plans, and a robust support system, we embarked on our first GitLab upgrade two years ago. We carefully followed our checklist, handling each important part systematically. GitLab comprises both stateful (Gitaly) and stateless (Praefect, Sidekiq, and App Server) components, all managed through auto-scaling groups. We use a ‘create before destroy’ strategy for deploying stateless components and an ‘in-place node rotation’ method via Terraform for stateful ones.
We deployed key parts like Gitaly, Praefect, Sidekiq, App Servers, Network File System (NFS) server, and Elasticsearch in a specific sequence. Starting with Gitaly, followed by Praefect, then Sidekiq and App Servers, and finally NFS and Elasticsearch. Our thorough testing showed this order to be the most dependable and safe.
However, the journey was full of challenges. For instance, we encountered issues such as the Gitaly cluster falling out of sync for monorepo and the Praefect server failing to distribute the load effectively. Praefect assigns a primary Gitaly node for each repository to host it. All write operations are sent to the repository’s primary node, while read requests are spread across all synced nodes in the Gitaly cluster. If the Gitaly nodes aren’t synced, Praefect will redirect all write and read operations to the repository’s primary node.
Gitaly is a stateful application, we upgraded each Gitaly node with the latest AMI using an in-place node rotation strategy. In older versions of GitLab (up to v14.0), if a Gitaly node is unhealthy, Praefect would immediately update the primary node for the repository to any healthy Gitaly node. After the rolling upgrade for a 3-node Gitaly cluster, repositories were mainly concentrated on only one Gitaly node.
In our situation, a very busy monorepo was assigned to a Gitaly node that was also the main node for many other repositories. When real traffic began after deployment, the Gitaly node had trouble syncing the monorepo with the other nodes in the cluster.
Because the Gitaly node was out of sync, Praefect started sending all changes and access requests for monorepo to this struggling Gitaly node. This increased the load on the Gitaly server, causing it to fail. We found this to be the main issue and decided to manually move our monorepo to a Gitaly node that was less crowded. We also added a step to validate primary node distribution to our deployment checklist.
This immediate failover behaviour changed in GitLab version 14.1. Now, a primary is only elected lazily when a write request arrives for any repository. However, since we enabled maintenance mode before the Gitaly deployment, we didn’t receive any write requests. As a result, we did not see a shift in the primary node of the monorepo with new GitLab versions.
Regular upgrades: Our new normal
Embracing the practice of consistent upgrades dramatically transformed the way we operate. We initiated frequent upgrades and implemented measures to reduce the actual deployment time.
- Perform all major testing in one day before deployment.
- Prepare a detailed checklist to follow during the deployment activity.
- Reduce the minimum number of App Server and Sidekiq Servers required just after we start the deployment.
- Upgrade components like App Server and Sidekiq in parallel.
- Automate smoke testing to examine all major workflows after deployment.
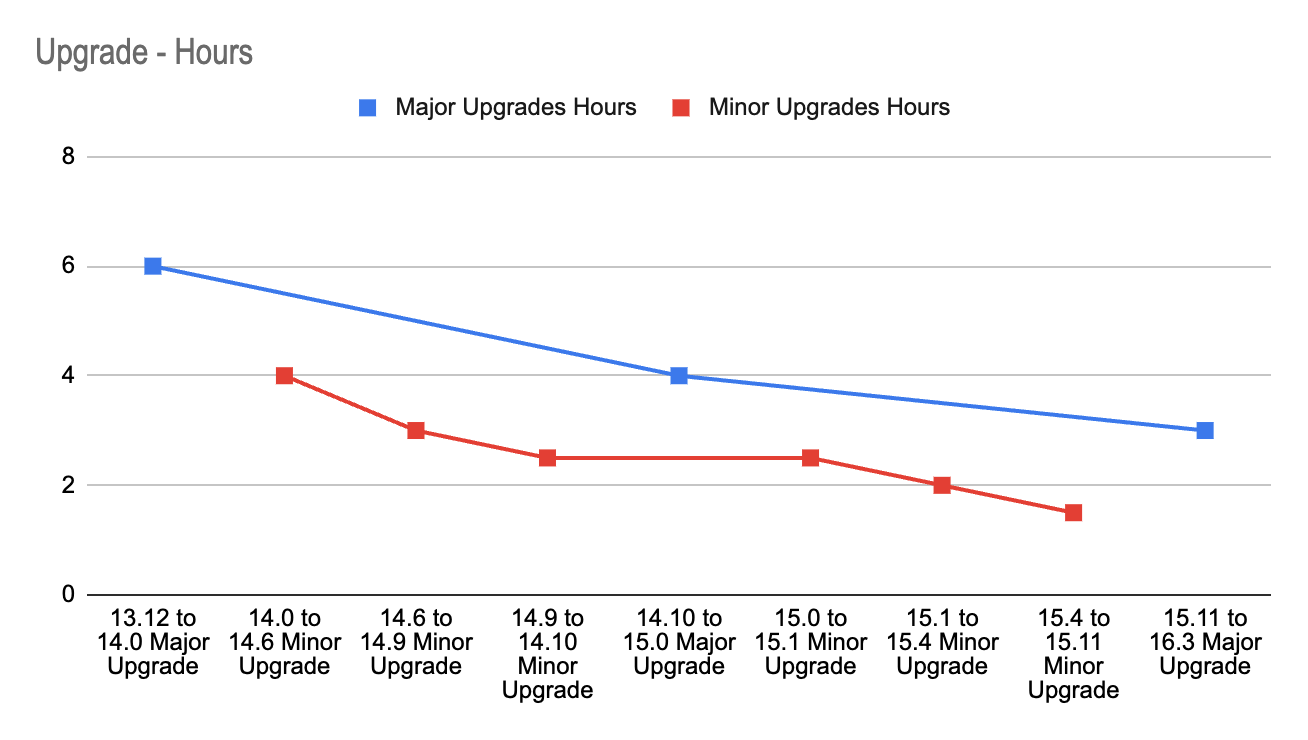
Leveraging the lessons learned and the experience gained with each upgrade, we successfully cut the time spent on the entire operation by 50%. The image-3 shows how we reduced our deployment time for major upgrades from 6 hours to 3 hours and our deployment time for minor upgrades from 4 to 1.5 hours.
Each upgrade enriched our comprehensive knowledge base, equipping us with insights into the possible behaviours of each component under varying circumstances. Our growing experience and enhanced knowledge helped us achieve successful upgrades with less downtime with each deployment.
Rather than moving up one minor version at a time, we learned about the feasibility of skipping versions. We began using the GitLab Upgrade Path. This method allowed us to skip several versions, closing the distance to the latest version with fewer deployments. This approach enabled us to catch up on 24 months’ worth of upgrades in just 11 months, even though we started 14 months behind.
Overcoming challenges
Our journey was not without hurdles. We faced challenges in maintaining system stability during upgrades, navigating unexpected changes in functionality post upgrades, and ensuring data integrity.
However, these challenges served as an opportunity for our team to innovate and create robust workarounds. Here are a few highlights:
Unexpected project distribution: During upgrades and Gitaly server restarts, we observed unexpected migration of the monorepo to a crowded Gitaly server, resulting in higher rate limiting. We manually updated primary nodes for the monorepo and made this validation as a part of our deployment checklist.
NFS deprecation: We migrated all required data to S3 buckets and deprecated NFS to become more resilient and independent of Availability Zone (AZ).
Handling unexpected Continuous Integration (CI) operations: A sudden surge in CI operations sometimes resulted in rate limiting and interrupted more essential Git operations for developers. This is because GitLab uses different RPC calls and their concurrency for SSH and HTTP operations. We encouraged using HTTPS links for GitLab CI and automation script and SSH links for regular Git operations.
Right-sizing resources: We countered resource limitations by right-sizing our infrastructure, ensuring each component had optimal resources to function efficiently.
Performance testing: We conducted performance testing of our GitLab using the GitLab Performance Tool (GPT). In addition, we used our custom scripts to load test Grab specific use cases and mono repositories.
Limiting maintenance windows: Each deployment required a maintenance window or downtime. To minimise this, we structured our deployment processes more efficiently, reducing potential downtime and ensuring uninterrupted service for users.
Dependency on GitLab.com image registry: We introduced measures to host necessary images internally, which increased our resilience and allowed us to cut ties with external dependencies.
The results
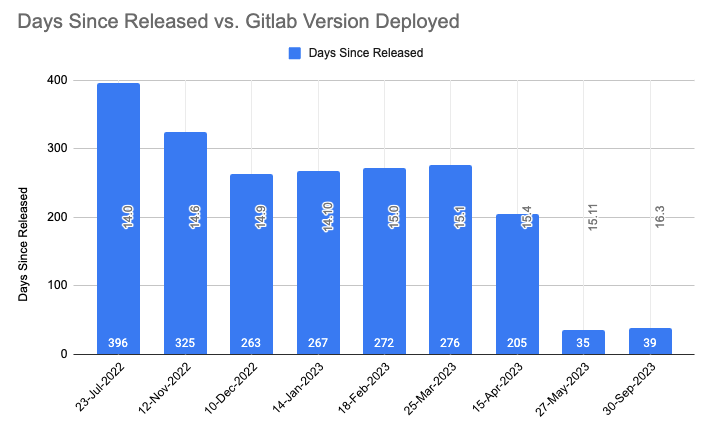
Through careful planning, we’ve improved our upgrade process, ensuring system stability and timely updates. We’ve also reduced the delay in aligning with official GitLab releases. The image below displays how the time delay between release date and deployment has been reduced with each upgrade. It sharply brought down from 396 days (around 14 months) to 35 days.
At the time of this article, we’re just two minor versions behind the latest GitLab release, with a strong focus on security and resilience. We are also seeing a reduced number of reported issues after each upgrade.
Our refined process has allowed us to perform regular updates without any service disruptions. We aim to leverage these learnings to automate our upgrade deployments, painting a positive picture for our future updates, marked by efficiency and stability.
Looking ahead
Our dedication extends beyond staying current with the most recent GitLab versions. With stabilised deployment, we are now focusing on:
- Automated upgrades: Our efforts extend towards bringing in more automation to enhance efficiency. We’re already employing zero-downtime automated upgrades for patch versions involving no database migrations, utilising GitLab pipelines. Looking forward, we plan to automate minor version deployments as well, ensuring minimal human intervention during the upgrade process.
- Automated runner onboarding for service teams: We’ve developed a ‘Runner as a Service’ solution for our service teams. Service teams can create their dedicated runners by providing minimal details, while we manage these runners centrally. This setup allows the service team to stay focused on development, ensuring smooth operations.
- Improved communication and data safety: We’re regularly communicating new features and potential issues to our service teams. We also ensure targeted solutions for any disruptions. Additionally, we’re focusing on developing automated data validation via our data restoration process.
- Focus on development: With stabilised updates, we’ve created an environment where our development teams can focus more on crafting new features and supporting ongoing work, rather than handling upgrade issues.
Key takeaways
The upgrade process taught us the importance of adaptability, thorough preparation, effective communication, and continuous learning. Our ‘No Version Left Behind’ motto underscores the critical role of regular tech updates in boosting productivity, refining processes, and strengthening security. These insights will guide us as we navigate ongoing technological advancements.
Below are the key areas in which we improved:
Enhanced testing procedures: We’ve fine-tuned our testing strategies, using both automated and manual testing for GitLab, and regularly conducting performance tests before upgrades.
Approvals: We’ve designed approval workflows that allow us to obtain necessary clearances or approvals before each upgrade efficiently, further ensuring the smooth execution of our processes.
Improved communication: We’ve improved stakeholder communication, regularly sharing updates and detailed documents about new features, deprecated items, and significant changes with each upgrade.
Streamlined planning: We’ve improved our upgrade planning, strictly following our checklist and rotating the role of Upgrade Ownership among team members.
Optimised activity time: We’ve significantly reduced the time for production upgrade activity through advanced planning, automation, and eliminating unnecessary steps.
Efficient issue management: We’ve improved our ability to handle potential GitLab upgrade issues, with minimal to no issues occurring. We’re prepared to handle any incidents that could cause an outage.
Knowledge base creation and automation: We’ve created a GitLab knowledge base and continuously enhanced it with rich content, making it even more invaluable for training new team members and for reference during unexpected situations. We’ve also automated routine tasks to improve efficiency and reduce manual errors.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!


