Introduction
eBay is committed to providing a seamless and enjoyable buying experience for its customers. One area that we’re continuously looking to improve is the quality of our listings, particularly with regards to images and text. In the past, the presence of low-quality images could lead to inaccurate product representation and, in a worst-case scenario, disappointed buyers. Additionally, text and image embeddings derived respectively from listing titles and images were stored in separate spaces, making it challenging to create a unified and accurate recommendation system. eBay’s deep learning models were not able to process both types of information efficiently.
To address these challenges, we’ve created a new system for contextual recommendation by integrating different modalities and custom-built modules, including image-text mismatch detection and triplet loss with TransH, into the recall module. Our approach enables eBay’s recommendation system to deliver highly accurate recommendations and drives about a 15% percent increase in buyer engagement.
Information Retrieval: Recall Module in eBay’s Recommendation System
The recall module is a crucial component of the eBay recommendation system. Its primary function is to retrieve from various perspectives a set of items that are most relevant to the main listing on the View Item Page. The recall module is the first step in the recommendation process, and it plays a critical role in making sure that the items are the most appropriate, relevant and high-quality to our users.
In the past, the recall module within the recommendation system primarily depended on information from a single modality, such as the item title and item image. While this approach proved useful for retrieving relevant results, it had its limitations. The unimodal method lacked signals from other modalities, which made it difficult to provide accurate recommendations for more complex scenarios, such as distinguishing between a toy car and a real car.
By integrating multimodal information from items, we have developed a high-performance recall module that significantly improves the recommendation system’s accuracy for more complex scenarios. This innovative approach ensures a more relevant and personalized user experience. As illustrated in Figure 1, relying solely on the text modality for retrieving relevant listings may result in the inclusion of items within the recommendation system that are not as relevant or have low quality. This occurs because the similarity of their titles to the hero item on the page is high, but this disregards cover image relevance and quality.
Figure1: Using only text modality to recall may result in low quality listings.
Multimodal Item Embedding Solution
To solve these problems, we recently launched a new Multimodal Item Embedding solution that can now effectively combine information from different modalities to obtain rich feature information. This integration allows the team to better understand listings on eBay and create a more accurate and efficient recall set for the recommendation system. Additionally, by detecting mismatches between the image and title of a listing, the team can provide an opportunity to filter out low-quality results.
Our Multimodal Item Embedding solution uses pretrained embeddings from the Search team (Text embedding with BERT as the base model) and Computer Vision team (Image embedding with Resnet-50 as the base model) teams. It includes a Siamese two-tower model trained on the Machine Learning training platform to predict the co-click probability of two items. The model uses triplet loss with TransH to ensure that text and image embeddings are projected into the same embedding space. The title-image mismatch detection module uses mismatch embeddings to predict the probability of clicks on an item with mismatched pictures and titles.
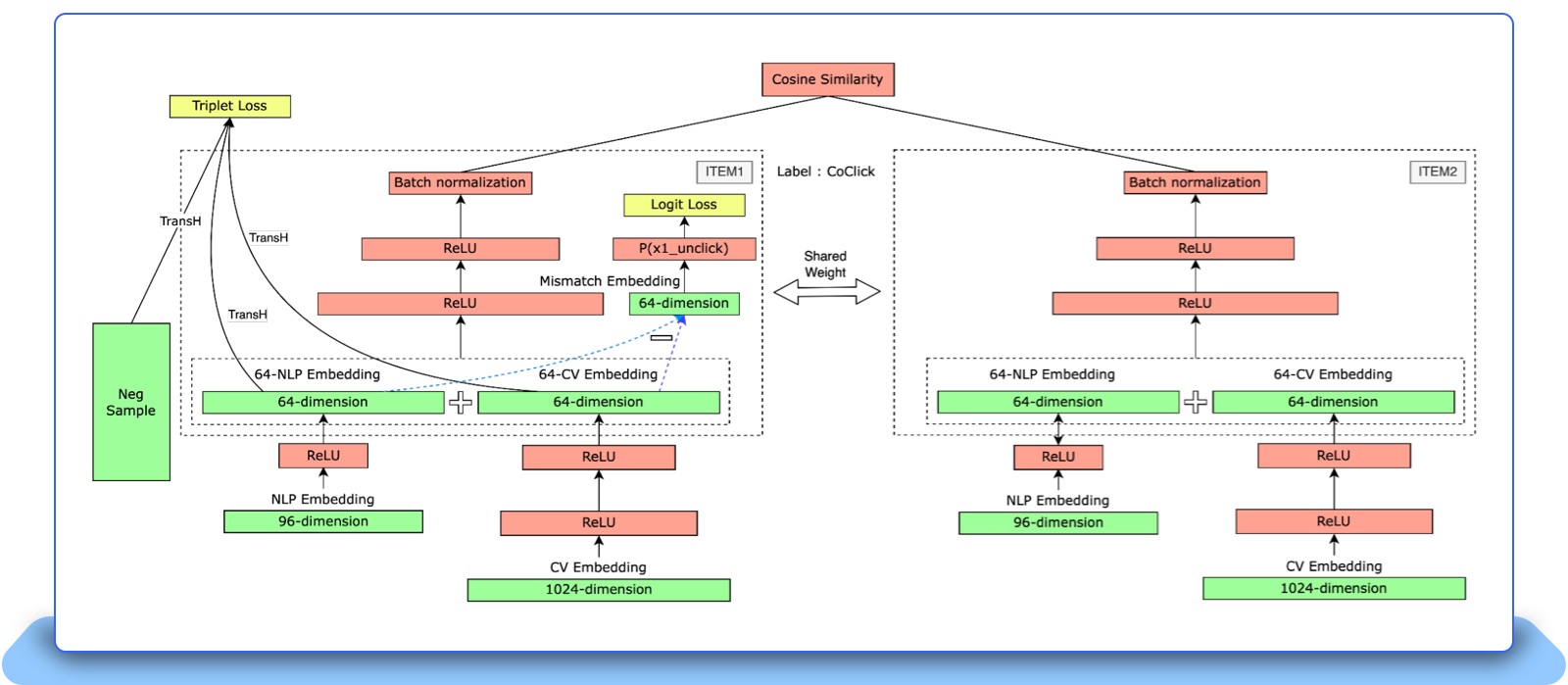
Figure 2: Overall model structure of the Siamese two-tower model.
In the example below, the “Embedding Distance” in the last column is a unified score that reflects the similarity to the seed item from both the item title and cover image perspectives. The new unified score is more accurate than the “Title Similarity” score, which relies only on title texts.
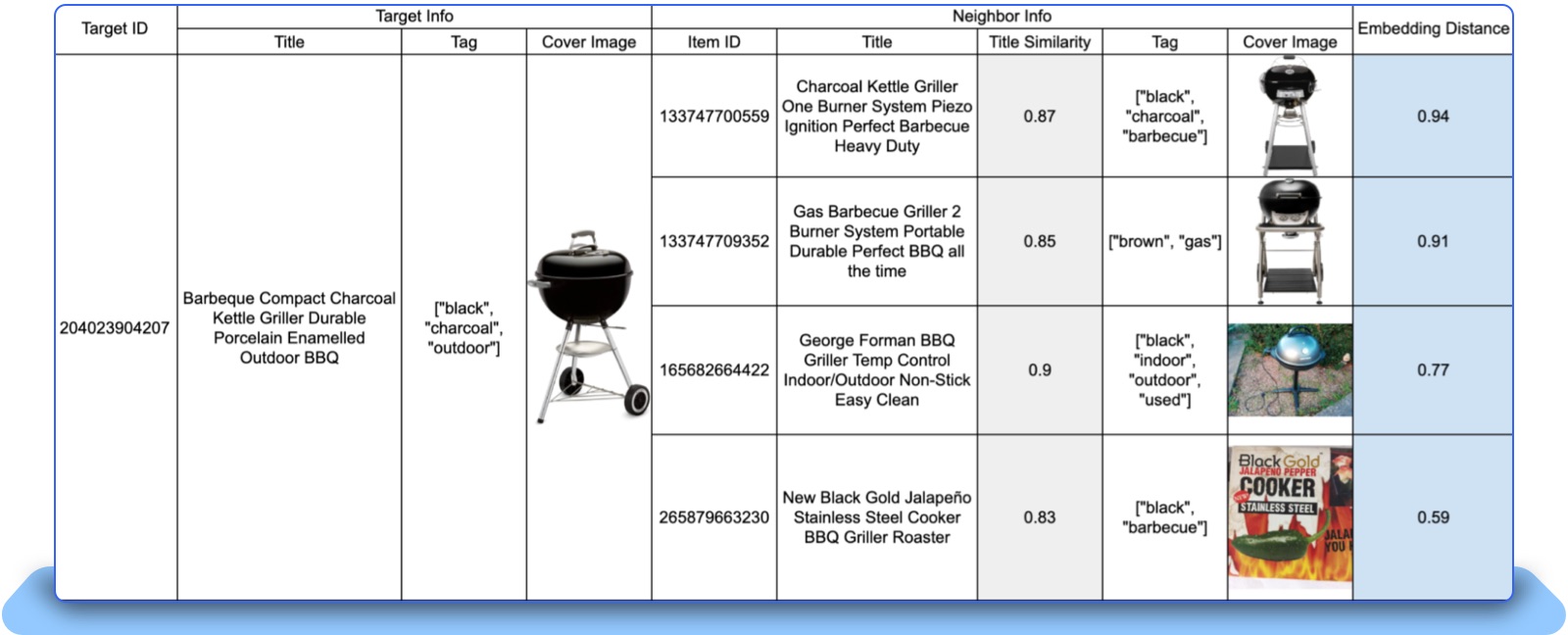
Figure 3: Illustration comparing the Multimodal Item Embedding solution with a Text-Only Modality approach.
Siamese Two-Tower Model
A Siamese two-tower model is a neural network architecture that uses two identical subnetworks (or towers) to process two different inputs and is commonly used for tasks that involve comparing or matching two inputs, such as similarity analysis, duplicate detection, and recommendation systems. In the case of the Multimodal Item Embedding solution, each tower represents a listing, and the inputs to each tower are the concatenated pre-trained image and text embeddings for that listing.
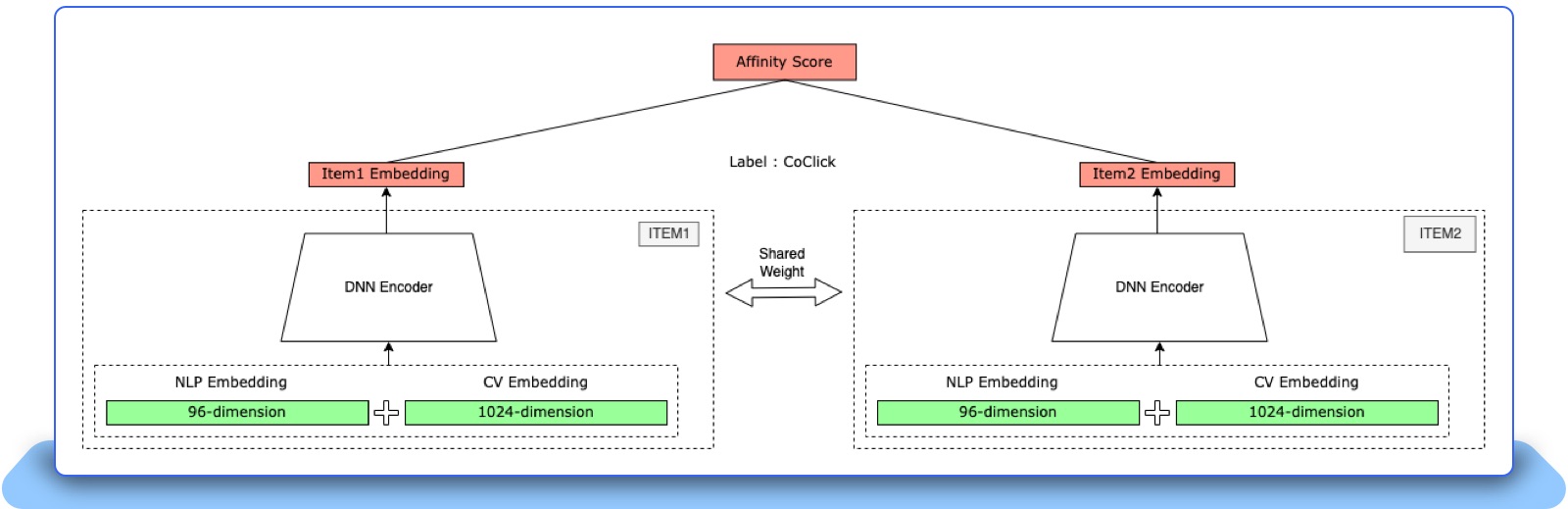
Figure 4: Architecture of our two-tower models with pre-trained embedding as input
The key benefit of using a Siamese two-tower model is that it allows the model to learn a similarity function between the two different listings based on their image and text embeddings in an end-to-end manner without relying on handcrafted features or intermediate representations. This makes the model more flexible and adaptable to different types of input data. By calculating the affinity score between the two item embeddings, we can predict whether they are likely to be co-clicked or not. Moreover, the shared weights in the two towers can help prevent overfitting as they constrain the model to learn representations that are useful for both inputs.
Triplet Loss with TransH
In the Multimodal Item Embedding solution, one of the challenges was ensuring that both the image and text embeddings for each listing were distributed in the same embedding space so that they could be easily integrated together. To address this challenge, the team used a technique called triplet loss.
Triplet loss is a type of loss function commonly used in deep learning to train models for tasks such as image recognition, face verification, and more. The idea behind triplet loss is to learn an embedding function that maps input data points to a common embedding space, where they can be compared using a distance metric like Euclidean distance. The triplet loss function is designed to ensure that the distance between similar listings (e.g., co-clicked listings) is minimized, while the distance between dissimilar listings is maximized.
Triplet loss:
In addition to triplet loss, the team also borrowed the TransH idea from knowledge graphs to project listings onto a hyperplane. TransH is a model in the knowledge graph embedding realm that represents entities and relations as vectors in a continuous space. TransH projects entities and relations onto a hyperplane before computing the inner product to capture complex interactions between them. The team adapted this idea to project the DNN-encoded image and text embeddings for each listing onto a hyperplane, ensuring that the two embeddings represented the same listing.
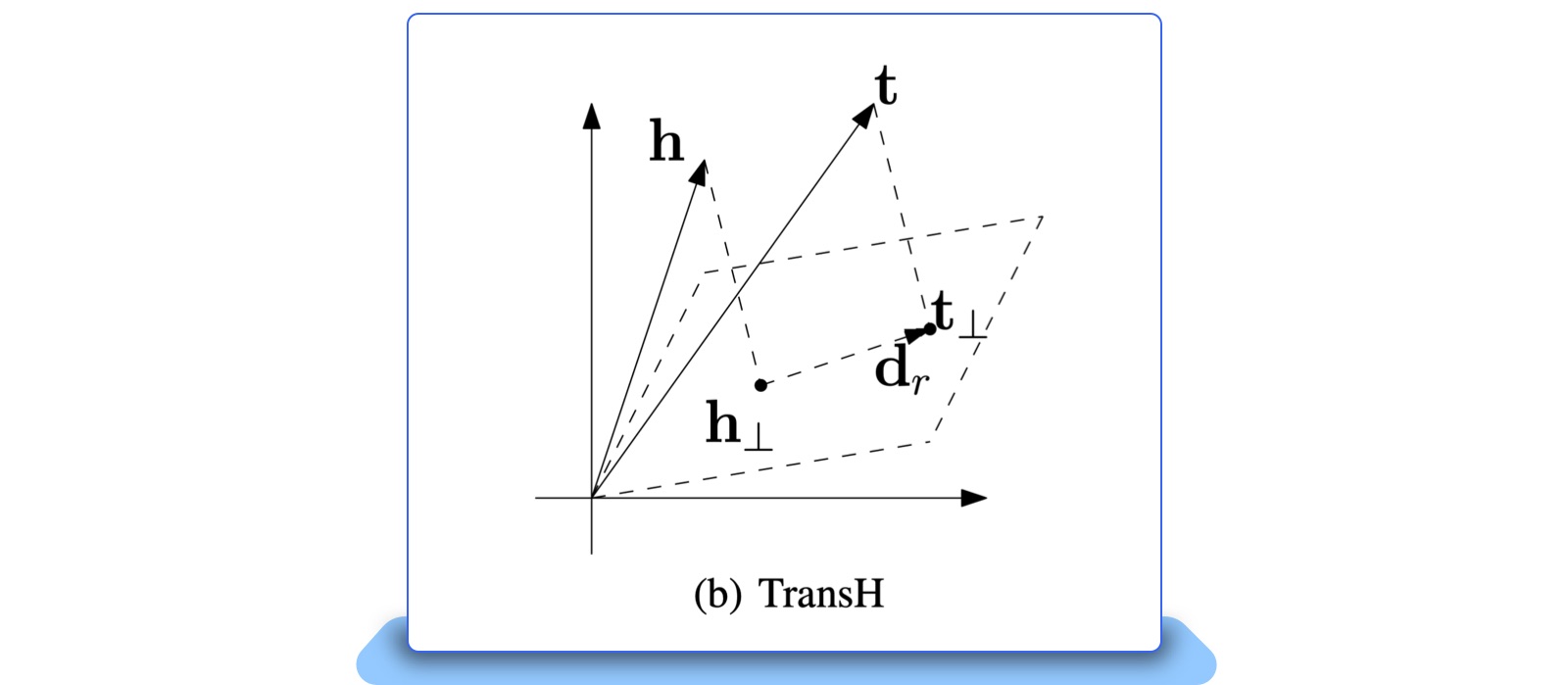
Figure 5: Hyperplane explanation of TransH
By using triplet loss with TransH, the team was able to effectively combine information from different modalities and obtain rich feature information for each listing. Combining the triplet loss and TransH techniques, the loss of the two-tower model turns out to be:
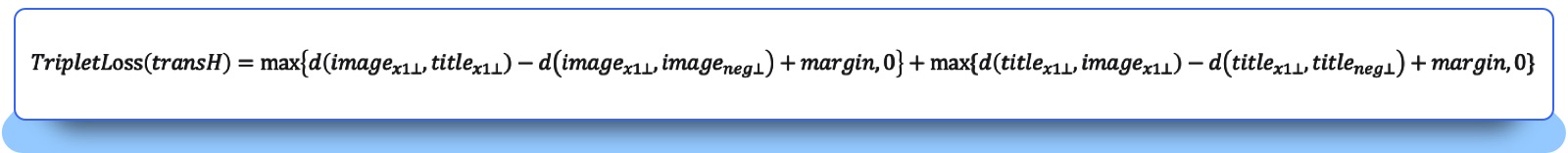
Offline training comparison: triplet loss with different projection methods

Table 1: Offline training metrics for TransH/E Strategy
Mismatch Detection Module
As an online marketplace, eBay accommodates a vast array of pre-loved items listed by individual sellers. However, the image quality, and thus the accurate representation, of these images can sometimes vary.

Figure 6: An instance of mismatched product titles and cover images for the search term “Sony headphone”
Upon identifying this problem, we applied a sophisticated module to address it. Detailed data analysis revealed that products exhibiting discrepancies between images and descriptions yielded lower click-through and purchase rates. Users typically avoided items displaying such inconsistencies. Aiming to address this issue, we used the discrepancy between the image embedding and title embedding mapped in the TransH hyperplane as the model input. Our predictive target was set to the probability of an item not receiving a click, which represents the extent of incongruity between the image and title and how it influences the potential for the item to be clicked on.
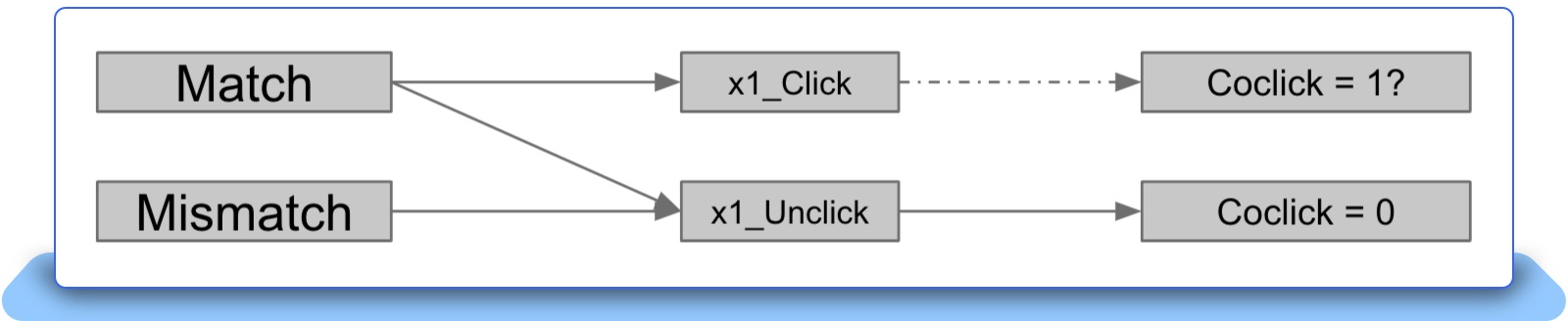
Figure 7: Illustration of mismatch module’s prediction target

Figure 8: Depiction of the mismatch module’s results, where a higher mismatch score indicates the occurrence of a mismatch scenario
After adding the loss for image-text mismatch, we conducted a case analysis on the results after the model training was completed. From the results, we found that the model’s prediction accuracy for image-text mismatch of the products was well-aligned with reality, indicating that our image-text mismatch module is effective.
Below are the offline experimental results of the multimodal approach. After adding the embedding space triplet loss and image-text mismatch loss to the model, both factors had a positive influence on the model’s metric performance.
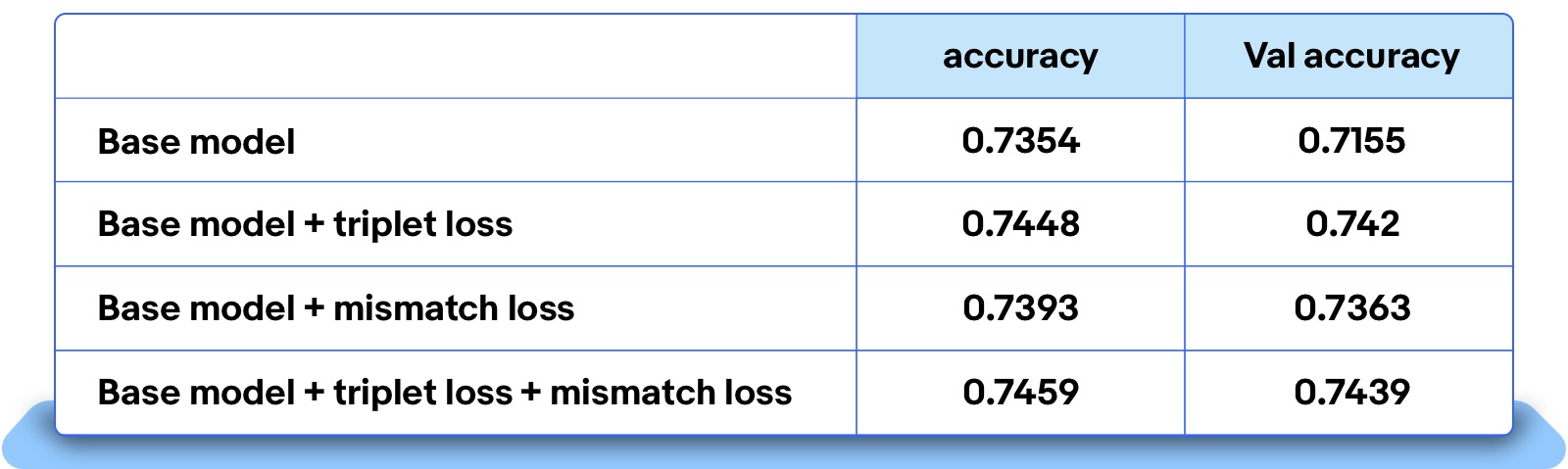
Table 2: Offline training metrics for mismatch module plus triplet loss
Online Experiment Results
Multimodal embedding-based recall has been deployed on several eBay pages where our recommendations are shown, such as the listing page, add-to-cart page, order detail page, and watch page. A/B tests have shown a significant improvement in key business metrics:up to a 15.9% increase in CTR (Click Through Rate) and a 31.5% increase in PTR (Purchase Through Rate). Starting in February 2023, our Multimodal recall has been deployed online and is serving site traffic in eBay’s website and app.
The A/B test results validate that integrating multimodal techniques to retrieve information from different dimensions of listings in our recommendation recall module drives better conversion and buyer engagement. From data analysis, we found that Multimodal embedding is able to recall more items than relying on a single modality alone and can detect mismatches between text descriptions and cover images.

Figure 9: Side by side comparison of Multimodal and single modality solutions. *Coverage is higher than any modality alone with the usage of default embeddings.
Summary
In this blog post, we’ve discussed how eBay has advanced its listing recommendations with a Multimodal Item Embedding solution. Our approach integrates various modalities of eBay listings, which benefits the buyer experience and the relevance of suggested listings. We delved into the issues of low-quality images and the disconnect between image and text embeddings, and how these influenced the development of our solution. The approach is an example of how eBay is committed to continually improving the buying experience by leveraging advanced technologies and data-driven insights.
In the next step, we will initiate the development of the NRT pipeline, focusing on integrating user-specific information and the LLM prompt module to enhance personalization and relevance of multimodal item embedding in recommendations.