Introduction
Apache Spark™ Structured Streaming is a popular open-source stream processing platform that provides scalability and fault tolerance, built on top of the Spark SQL engine. Most incremental and streaming workloads on the Databricks Lakehouse Platform are powered by Structured Streaming, including Delta Live Tables and Auto Loader. We have seen exponential growth in Structured Streaming usage and adoption for a diverse set of use cases across all industries over the past few years. Over 14 million Structured Streaming jobs run per week on Databricks, with that number growing at a rate of more than 2x per year.
Most Structured Streaming workloads can be divided into two broad categories: analytical and operational workloads. Operational workloads run critical parts of a business in real-time. Unlike analytical processing, operational processing emphasizes timely transformations and actions on the data. Operational processing architecture enables organizations to quickly process incoming data, make operational decisions, and trigger immediate actions based on the real-time insights derived from the data.
For such operational workloads, consistent low latency is a key requirement. In this blog, we will focus on the performance improvements Databricks has implemented as part of Project Lightspeed that will help achieve this requirement for stateful pipelines using Structured Streaming.
Our performance evaluation indicates that these enhancements can improve the stateful pipeline latency by up to 3–4x for workloads with a throughput of 100k+ events/sec running on Databricks Runtime 13.3 LTS onward. These refinements open the doors for a larger variety of workloads with very tight latency SLAs.
This blog is in two parts – this blog, Part 1, delves into the performance improvements and gains and Part 2 provides a comprehensive deep dive and advanced insights of how we achieved those performance improvements.
Note that this blog post assumes the reader has a basic understanding of Apache Spark Structured Streaming.
Background
Stream processing can be broadly classified into stateless and stateful categories:
- Stateless pipelines usually require each micro-batch to be processed independently without remembering any context between micro-batches. Examples include streaming ETL pipelines that transform data on a per-record basis (e.g., filtering, branching, mapping, or iterating).
- Stateful pipelines often involve aggregating information across records that appear in multiple micro-batches (e.g., computing an average over a time window). To complete such operations, these pipelines need to remember data that they have seen across micro-batches, and this state needs to be resilient across pipeline restarts.
Stateful streaming pipelines are used mostly for real-time use cases such as product and content recommendations, fraud detection, service health monitoring, etc.
What Are State and State Management?
State in the context of Apache Spark queries is the intermediate persistent context maintained between micro-batches of a streaming pipeline as a collection of keyed state stores. The state store is a versioned key-value store providing both read and write operations. In Structured Streaming, we use the state store provider abstraction to implement the stateful operations. There are two built-in state store provider implementations:
- The HDFS-backed state store provider stores all the state data in the executors’ JVM memory and is backed by files stored persistently in an HDFS-compatible filesystem. All updates to the store are done in sets transactionally, and each set of updates increments the store’s version. These versions can be used to re-execute the updates on the correct version of the store and regenerate the store version if needed. Since all updates are stored in memory, this provider can periodically run into out-of-memory issues and garbage collection pauses.
- The RocksDB state store provider maintains state within RocksDB instances, one per Spark partition on each executor node. In this case, the state is also periodically backed up to a distributed filesystem and can be used for loading a specific state version.
Databricks recommends using the RocksDB state store provider for production workloads as, over time, it is common for the state size to grow to exceed millions of keys. Using this provider avoids the risks of running into JVM heap-related memory issues or slowness due to garbage collection commonly associated with the HDFS state store provider.
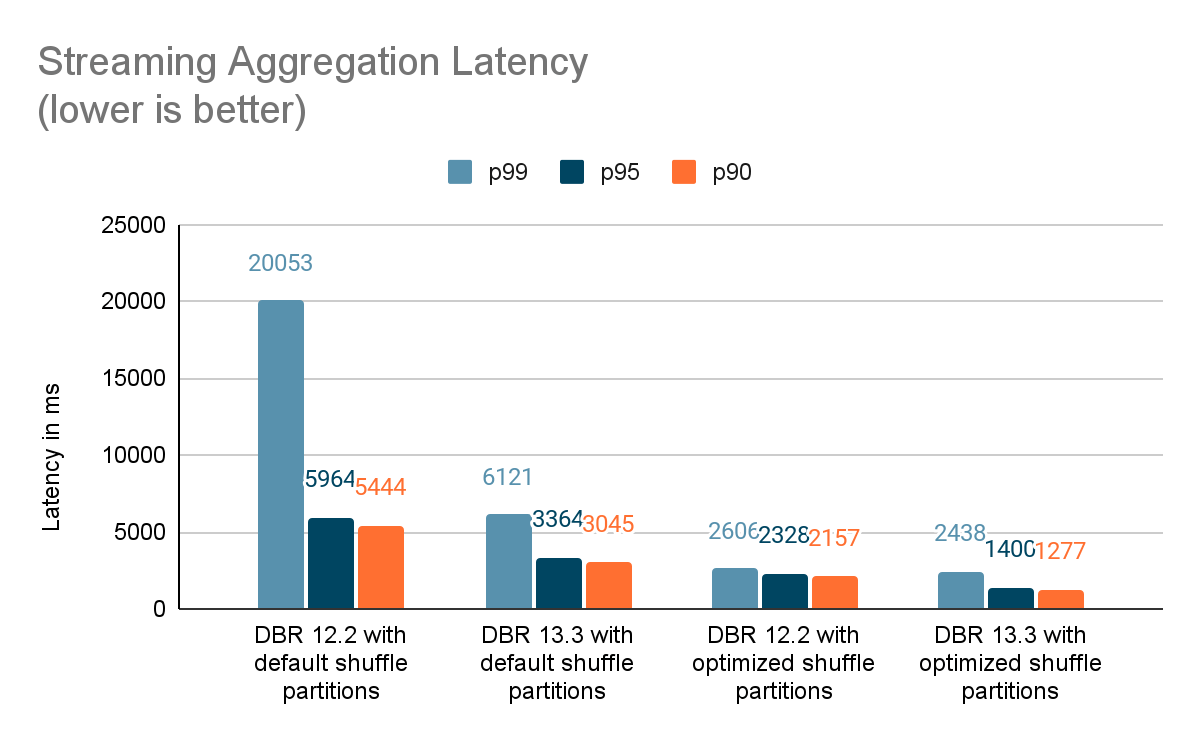
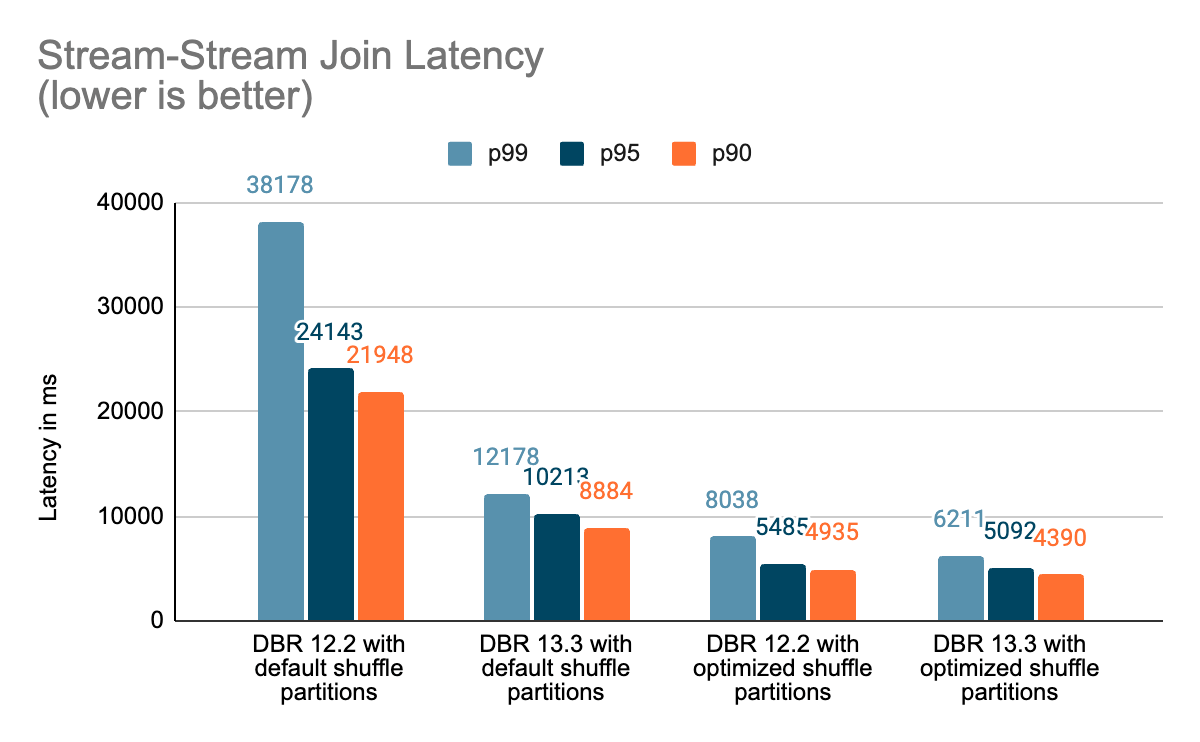
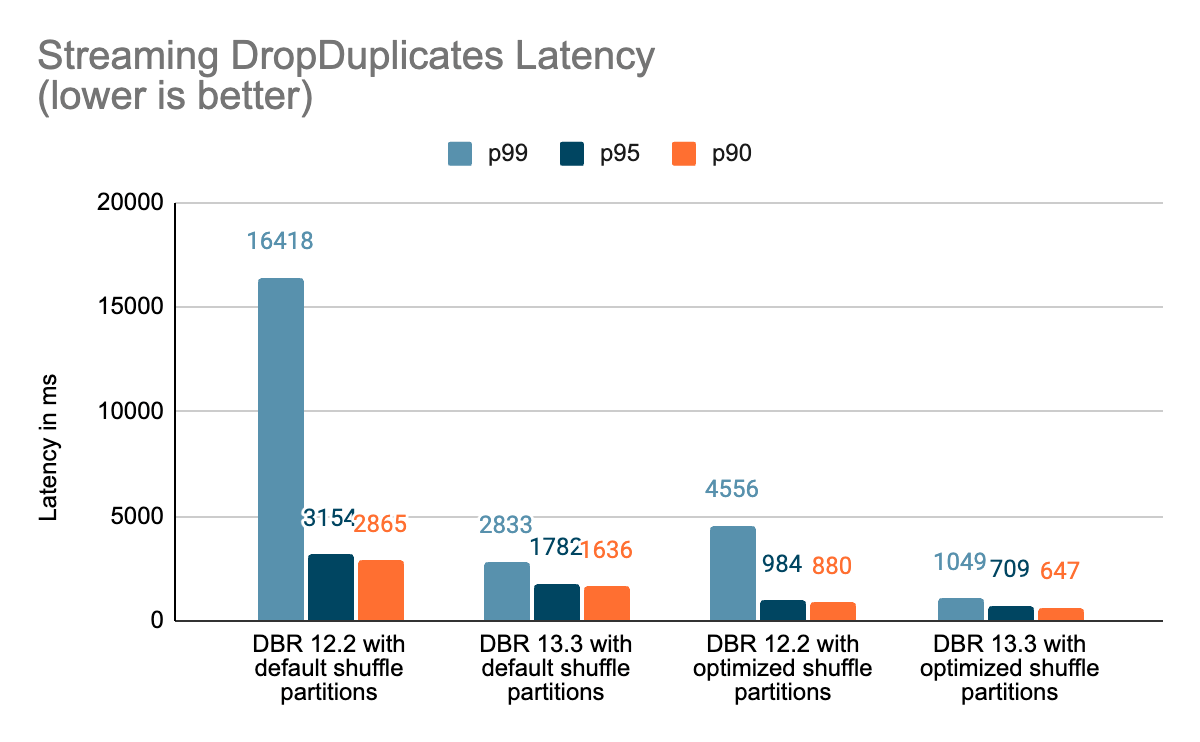
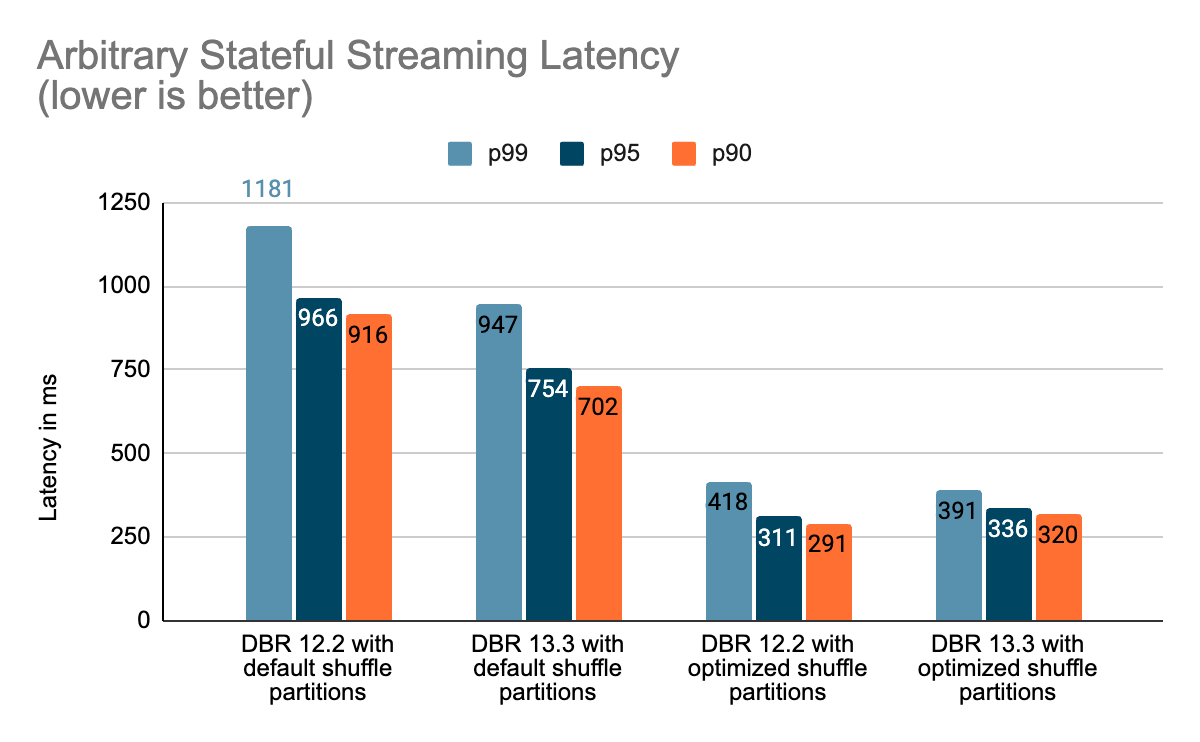
Benchmarks
We created a set of benchmarks to understand better the performance of stateful streaming pipelines and the effects of our improvements. We generated data from a source at a constant throughput for testing purposes. The generated records contained information about when the records were created. For all stateful streaming benchmarks, we tracked end-to-end latency on a per-record basis. On the sink side, we used the Apache DataSketches library to collect the difference between the time each record was written to the sink and the timestamp generated by the source. This data was used to calculate the latency in milliseconds.
For the Kafka benchmark, we set aside some cluster nodes for running Kafka and generating the data for feeding to Kafka. We calculated the latency of a record only after the record had been successfully published to Kafka (on the sink). All the tests were run with RocksDB as the state store provider for stateful streaming queries.
All tests below ran on i3.2xlarge instances in AWS with 8 cores and 61 GB RAM. Tests ran with one driver and five worker nodes, using DBR 12.2 (without the improvements) as the base image and DBR 13.3 LTS (which includes all the improvements) as the test image.
Conclusion
In this blog, we provided a high-level overview of the benchmark we’ve performed to showcase the performance improvements mentioned in the Project Lightspeed update blog. As the benchmarks show, the performance improvements we have added unlock a lot of speed and value for customers running stateful pipelines using Spark Structured Streaming on Databricks. The added performance improvements to stateful pipelines deserve their own time for a more in-depth discussion, which you can look forward to in the next blog post “A Deep Dive Into the Latest Performance Improvements of Stateful Pipelines in Apache Spark Structured Streaming”.
Availability
All the features mentioned above are available from the DBR 13.3 LTS release.