eBay’s NuData [1] database platform is built from the ground up to be a cloud-native, distributed, highly scalable and performant. We not only adopted state-of-the-art technologies to overcome the technical challenges that come with building a database platform at this scale, but we also invested heavily in operationalizing it, with capabilities of self-serving, monitoring and alerting and auto remediation. Our database platform has been in production for the past four years, handling critical eBay data used for customer items, orders and payments. We have petabytes of data spanning across several different data centers.
In this article, we introduce how we solved the technical challenge of managing indexes for a distributed database by building a Global Secondary Index (GSI) that is extremely fast and consistent. In particular, our GSI system provides full-fledged features as below.
- High scalability: Our horizontally scalable architecture does not limit the volumes of indexes.
- Fault tolerance: To provide high availability, we manage replicas in local and geographically remote locations leveraging our organic solution. (NuRaft [2])
- High performance: In addition to performance advantage from having replicas, we leverage our organic storage engine solution (Jungle [5]) to optimize storage performance.
- Flexible resource management: Taking the advantages of horizontal scalable architecture is not free. We carefully operationalized flexible resource management to efficiently support dynamically changing users’ requirements.
- Self served GSI schema design tool for easy deployment: GSI design needs collaborative work with our users and NuData team. We have designed and used a tool to expedite this process.
We start with a use case example to highlight why GSI is needed.
Use Case: Searching Through Multiple Shards
Let’s use a “Listing Draft” service as an example. When an eBay seller starts preparing an item listing and cannot finish it right away, they can store that incomplete listing as a draft to finish it later.
Figure 1 Listing Draft service example
With this example, let’s say that a seller has multiple drafts and wants to search drafts with a specific range of start price (e.g. $6-$10). For our convenience, we call a draft a document and a seller a user hereafter. Then, our problem can be stated as searching documents falling within a range of start price for a user.
Even though this search problem sounds simple, it can be complex considering how our database stores documents. Our database has a high volume of documents and needs to search a specific set of documents in a reasonable latency. Such a storage requirement naturally requires us to split a whole set of documents to partitions, which we call a shard. Figure 2 shows such an example where each shard has a portion of all documents. Note that the same user’s documents (colored by orange) will most likely be across many different shards. This is because we store documents in the shards based on the listing ID’s hash. So, for the same user based on the listing ID, the document for the listing can be any one of the available shards.
We do not use the user ID for finding the shard to store the document, as we have what we call Power Sellers that can update multiple listings in a single request. This can overwhelm a shard if the sharding is based on the user ID. With that in mind, if a user wants to find documents whose start price ranges from $6 to $7, a query needs to visit all shards to search target documents. However, searching through all documents in all shards would induce an unacceptable latency to the user.
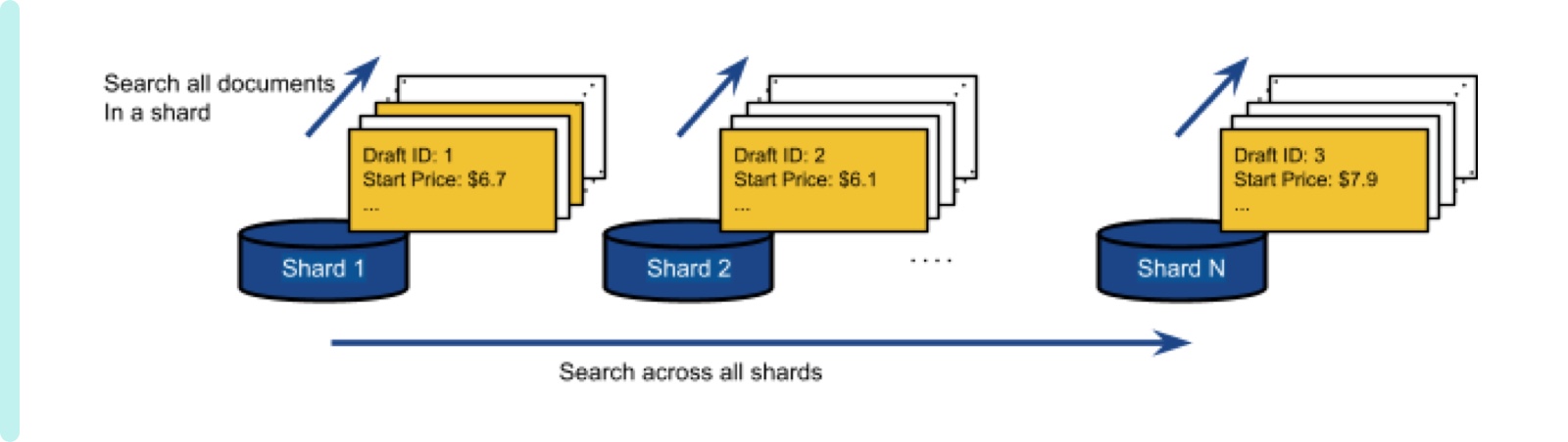
Figure 2 Exhaustive search for all data in all shards
Traditional Approach: Local Secondary Index (LSI)
A traditional remedy to improve query latency is to build an index where index entries are sorted by a specific field to quickly look up an entry. Simply applying this concept to our multi-shard environment, we can build each index for each shard as illustrated in Figure 3. An index in a shard is called Local Secondary Index (LSI). In this example, since index entries are sorted by (User ID, Start Price), we leverage a fast search algorithm to quickly find specific user’s entry and also entries within a range of start price.
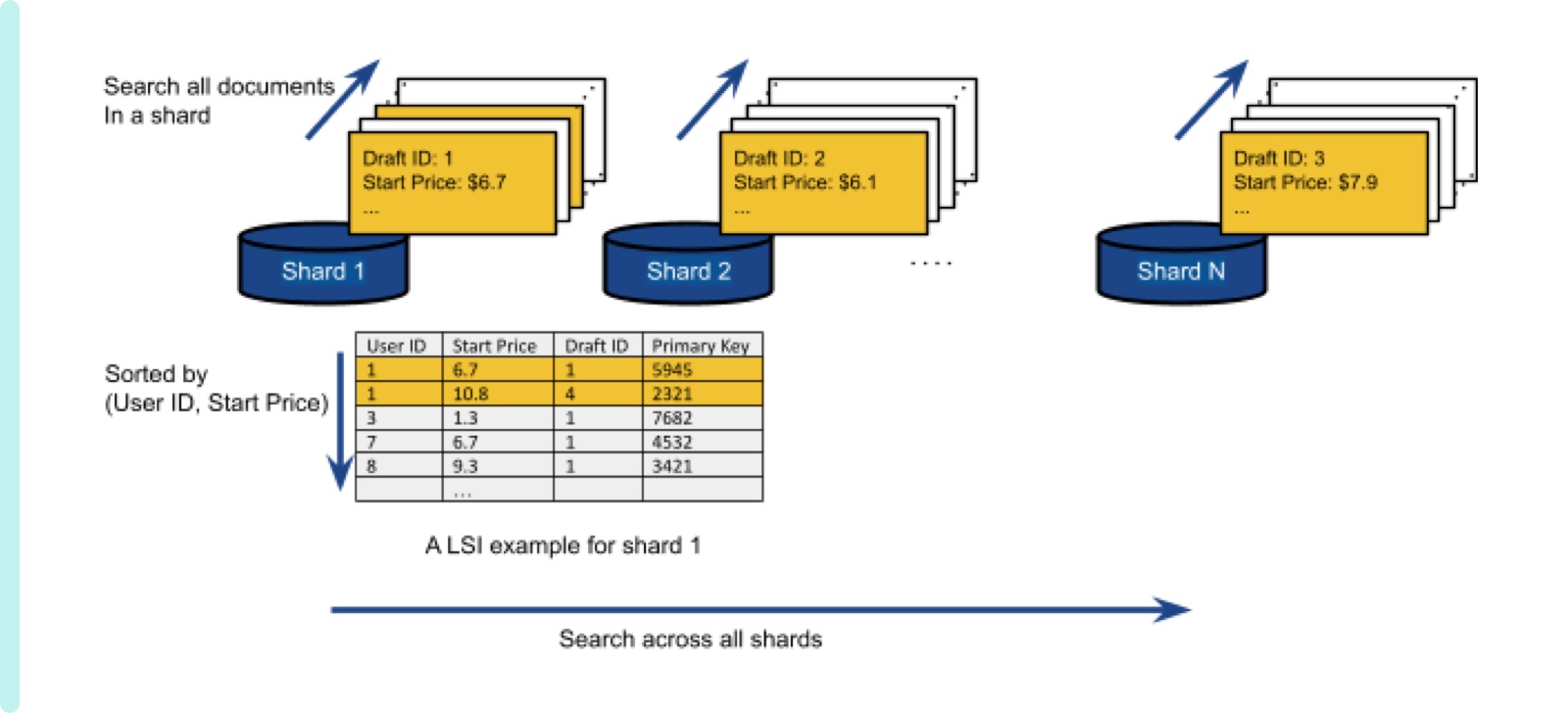
Figure 3 search with LSI: LSI improves search in a shard. But it still requires to visit all shards
LSI helps reduce search latency in a given shard. But a query still needs to search through all the shards. Surely, parallel rather than sequential invocations of search for shards would reduce an end-to-end latency required to visit all shards. Even with such optimization, this solution still requires handling extra processing after visiting all shards depending on a query type. For example, if a query requires documents to be sorted (e.g. sort by), a central entity needs to collect all relevant documents from all shards and sort them. If the number of documents of a user is small, this kind of extra processing might be done at little cost. However, we still need a guaranteed way to perform a query with a specific response time SLA.
Our Approach: Global Secondary Indexes (GSI)
The idea behind our approach to address the above mentioned points comes from a simple but insightful question: What if we can have a more comprehensive index that’s completely separate from the listing data rather than combining local secondary index data that is residing on a huge number of shards along with listing data?
Figure 4 shows a conceptual view of such an ideal index called Global Secondary Index (GSI). Similarly to a previous LSI example, this GSI example also has sorted entries by (user ID, start price). A difference is that with GSI, if we find a user’s entries (orange rows in the above example) then, we are assured that it covers all documents in a system. After that, we don’t need to try to see other pieces further. This might sound too ideal since the logic about splitting a whole set of original documents to partitions would apply here in the same way. That is a fair concern even though the size of an index entry is smaller than the size of an original document. We will address it in the next section.
Before diving into such details, we want to clarify a bit more what kind of benefits GSI provides in which scenarios. Note that scanning GSI does not require visiting data shards. After scanning GSI, further action may or may not be required depending on a query type. For example, if a query wants to get a quantity for a given (user ID, start price), then it can directly retrieve quantity values from GSI. However, if a query needs to get other fields (e.g. created date), then we need to fetch an original data by the Primary Key (Listing ID). Please note that this fetching original data doesn’t cost a search latency as much as in LSI case since this is not visiting all the data shards but fetching it from a specific shard indicated by the Primary Key. If the number of fields that a query wants to get is not that many, we can create another GSI having such fields. Then, we can eliminate the necessity of visiting data shards completely.
Even though this GSI idea itself is not new, only a few companies provide GSI service and at the scale we operate. We are building our unique GSI system to support use cases from eBay applications which requires new features in GSI to be developed. In the next sections, we present technical challenges and our solutions in more detail and also ongoing work items.
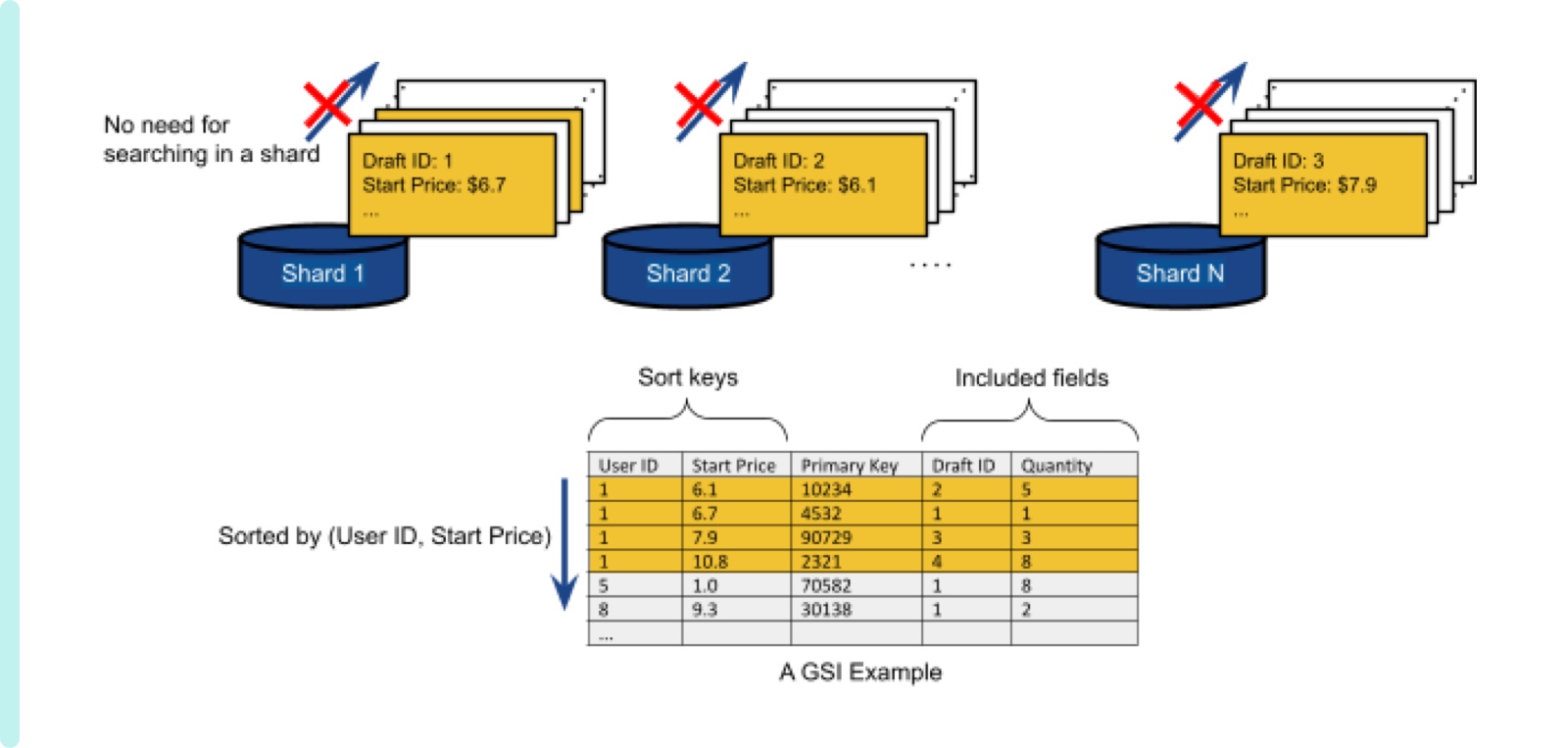
Figure 4 Conceptual representation of GSI
Challenges and Solutions
In this section, we present how we build our GSI system by explaining what the main challenges are and how we tackle each challenge. We start with scalability since it incurs in all subsequent challenges.
Large scale GSI: As we mentioned before, a main requirement for our database is to store a high volume of documents. Since fields in a GSI entry are a small subset of fields in an original document, storage requirements for a single set of GSI would be smaller than for the original documents. However, usually a single GSI cannot cover all possible use cases. For example, while the GSI example in Figure 4 helps find documents with a specific start price for a user, it is not that useful for finding documents created for a specific date for all users. It is not because the created date field is not in included fields but because the structure of sort keys doesn’t support such a type of query. Hence, there needs to be multiple GSIs for a given set of original documents. Working with customers, we have found that some production applications need more storage for GSI than storage for original documents. This fact naturally leads us to having a separate multi-shard environment for GSI.
Figure 5 shows how we accommodate multiple GSIs having the same sharding key in a multi-shard architecture. A GSI has a set of sort keys as in Figure 4. Given a set of sort keys of a GSI, we carefully choose fields which can be used for a sharding key. A sharding key indicates which GSI shard should be used for an index entry. Index entries sharing the same sharding key from different GSIes will be in the same GSI shard. This sharding architecture needs a careful design of the GSI to get the best benefit with performance of lookup. We elaborate on this in the next subsection.

Figure 5 Scalable multi-shard architecture with multiple GSIes
Need for a careful GSI design: Figure 6 shows impacts of how to determine a sharding key. In the figure, the colored boxes divide a whole GSI space. The same color indicates a set of entries with the same sharding key. The upper spectrum represents a case where the total size of entries with the same sharding key is less than the total storage size so that we can visit only one shard given a sharding key. In contrast, the lower spectrum represents a case where entries with the same sharding key cannot be in a single shard due to the large total sizes of entries. This kind of a GSI design limits the benefit of GSI explained in Figure 4. Note that such benefit comes from visiting only one shard in the system.
Hence, it’s clear that designing GSI in a proper way is important. A basic guideline is that we have to choose fields with high cardinality as a sharding key. Based on our interactions with customers, this design process needs expertise from customers and the NuData team. Customers know well the structure of their documents and type of queries. The NuData team knows storage requirements and how queries would work in the system. To help both parties’ effective communication, we developed a schema to define a GSI. The basic operation principle here is that the NuData team helps educate customers so that customers can register their own GSI by defining and deploying a schema by themselves. In this way, we have been able to handle many customers’ requests efficiently.
 Figure 6 Proper GSI design: The same color indicates entries with the same sharding key
Figure 6 Proper GSI design: The same color indicates entries with the same sharding key
Faulty environment: Our design aims for high availability even with a faulty deployment environment where a local fault such as a server outage as well as natural disasters can happen. Our basic approach to address this is to replicate documents to other servers in local and other geographical zones so that a local or larger outage may not disrupt a service, which may be continuously served by other servers.
Our core component for replication is NuRaft [2] which was open sourced by eBay. NuRaft is based on a consensus protocol (Raft [3]) which supports leader election, membership management, log replication and more. NuRaft added a significant set of new features needed for operating Raft protocol in production. Figure 7 shows how we leverage NuRaft for our system. Among other member nodes, only one node is allowed to be a leader node and it gets write/update requests. Through a consensus protocol explained in an original paper [3], all other followers get new or updated documents. A leader node may be chosen again either automatically when an existing leader node fails or manually when there is an operational need. NuRaft is not only used at eBay but also is available for our technology community. ClickHouse has recently announced that the team is building a replacement for ZooKeeper on top of NuRaft [4].
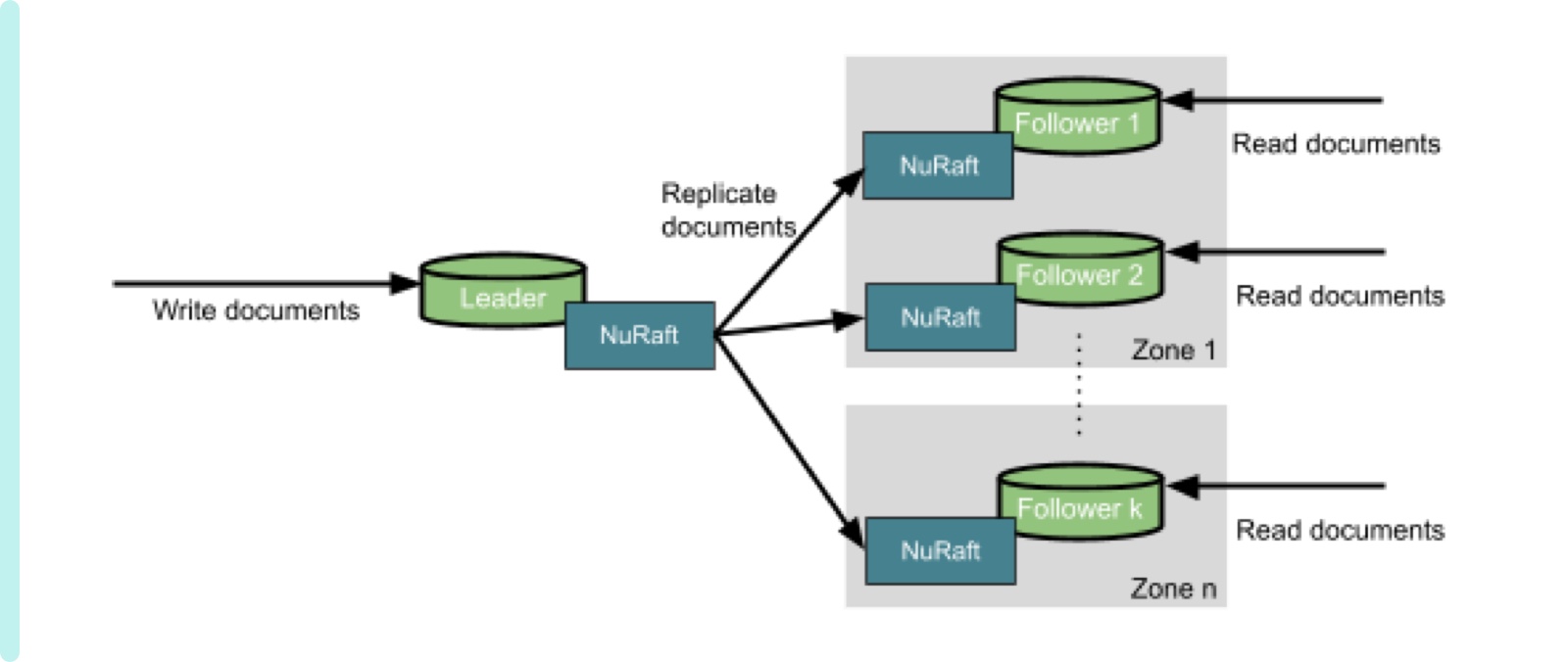
Figure 7 Replication: A leader node replicates write and update requests and follower nodes can support read requests.
Need for a performant storage engine: Choosing a good storage engine is important, since it is responsible for directly storing and retrieving documents to/from disks. Especially, for our system, two main requirements include efficient search based on key and sequence number. Search by key is needed to find a GSI entry given a key. Search by a sequence number is needed to support log replication and snapshot in NuRaft. Jungle [5], another eBay’s open source project, is our choice of storage engine to support both requirements. Jungle is used to store GSI entries and also logs replicated throughout replicas.
Dynamically changing requirement: Through collaborations with customers, we have learned an important lesson: Customers’ requirements are highly likely to change. In our horizontally scalable architecture, we can handle such changing requirements by adding or removing shards/replicas. Currently, we only support increasing capacity by splitting a shard into two shards so that more documents can be stored and more requests can be supported. We are developing a finer way to increase and decrease capacity to efficiently manage system resources.
End-to-End Architecture
Figure 8 shows the overall architecture of our GSI system putting together components that we have explained, plus extra components needed to provide a complete service. Customer applications send read/write requests to a service node which interplays such requests to a data shard. This service node is also fault tolerant so that a faulty component doesn’t disrupt the service. A service node communicates with a GSI shard as well as a data shard. However, as a first step in a lifecycle of a new document, a write request with a new document is given to a data shard by a service node. If this new document is covered by a schema defined and deployed by a customer, then an extractor creates a relevant GSI and sends it to a proper GSI shard. A relevant GSI shard is determined by a sharding key that can be obtained by the way a schema defines. The schema also impacts proxies handling requests. If a query in a read request includes fields covered by a schema, the query is forwarded to a relevant GSI shard instead of a data shard. Then, GSI can quickly serve such a covered query as explained before.
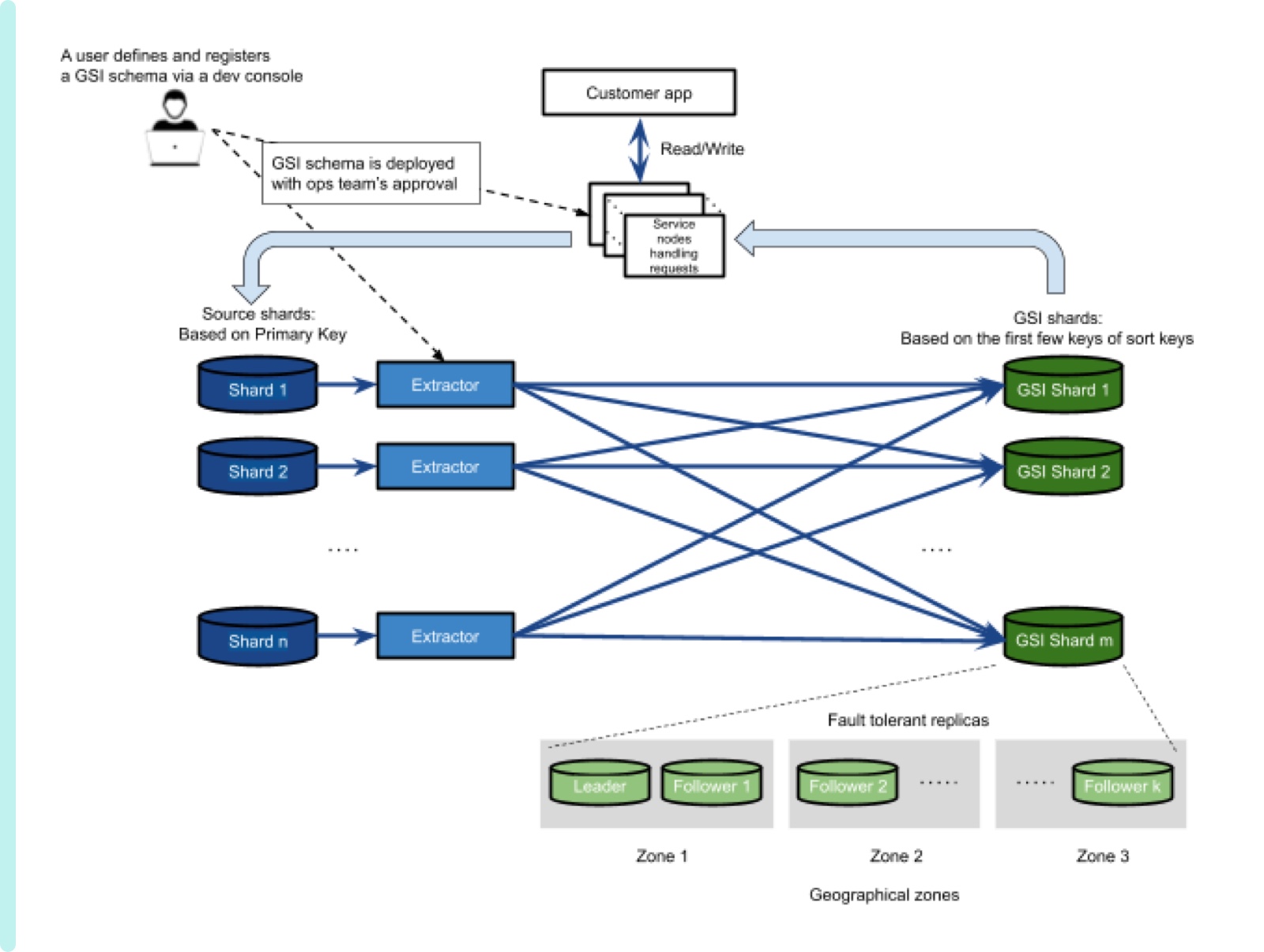
Figure 8 End-to-end GSI system architecture
What’s Next
We keep enhancing our GSI platform to have more features as requested by our customers. Above mentioned incremental management of system capacity is one feature that we are working on to efficiently manage our system resources. Another important feature under development that will be available in early 2022 is synchronous and unique GSI. The current GSI we mentioned in this article is updated in an eventually consistent manner.
References
[1] NuData (https://www.ebayinc.com/stories/news/ebay-builds-own-servers-intends-to-open-source/)
[2] NuRaft (Tech blog: https://tech.ebayinc.com/engineering/nuraft-a-lightweight-c-raft-core/,
GitHub: https://github.com/eBay/NuRaft)
[3] Raft (https://raft.github.io/raft.pdf)
[4] ClickHouse August (virtual) meetup (https://www.youtube.com/watch?v=IfgtdU1Mrm0)
[5] Jungle (Presentation: https://www.usenix.org/conference/hotstorage19/presentation/ahn,
GitHub: https://github.com/eBay/Jungle)