
The pace of innovation is faster than ever before, and through our AI work at eBay, we believe we’ve unlocked three major tracks to developer productivity: utilizing a commercial offering, fine-tuning an existing Large Language Model (LLM), and leveraging an internal network. Each of these tracks requires additional resources to integrate, but it’s not a matter of ranking them “good, better, or best.” Each can be used separately or in any combination, and bring their own benefits and drawbacks. Using all three of these options, we created an exercise with results we believe can be of interest and use to the wider developer community.
As a note: there is no reliable single metric to measure developer productivity given its complexity. Instead, as suggested by studies, we use both quantitative and qualitative metrics. The former includes tools like Git, DORA and Flow, and measuring code quality and performance. The latter is measured with targeted developer surveys.
Track 1: Existing Offerings
Many companies and products have popped up in recent years to take advantage of advances in AI. These are sometimes standalone commercial products, and sometimes tools built on existing open source LLMs, like Llama or Gemma.
We expanded our use of GitHub Copilot, a commercial offering, to all of our developers last year. Our test for this track involved a, well, pilot for Copilot, comprising 300 developers – half using Copilot, and half forming a control group with similar assignments and abilities but without Copilot, in an A/B test experiment conducted in the summer of 2023. We chose Copilot because of its popularity in the developer world, and because eBay already has our codebase on GitHub; we’re familiar with the way their products work.
What worked? Our results were very positive. Following a two-week ramp-up period, developer surveys showed that the developers using Copilot saw an increase in perceived productivity, along with a 27% code acceptance rate (as reported through Copilot telemetry). We also found good levels of accuracy: the generated documents were 70% accurate, and the generated code was at 60%. Additionally, for the experimental Copilot group, we saw a 17% decrease in pull request (PR) creation to merge time, and a 12% decrease in Lead Time for Change – an indirect benefit of efficient coding. The code quality measure through Sonar remained the same for both groups.
Copilot was able to provide features including converting comments to code, suggesting the next line of code, generating tests, and auto-filling repetitive code – all time-saving measures. But it also had drawbacks.
What didn’t work so well? Copilot has a limit to its prompt size – essentially, how much data it can process. LLMs are improving the context size with each iteration, and for some uses this won’t be a problem at all. For a company of eBay’s size, though, certain tasks are simply not possible. We’ve got millions of lines of code, and some activities require the knowledge of the entire eBay codebase.
Track 2: Post-Trained and Fine-Tuned LLMs
Existing open source LLMs can sometimes reach an upper limit of productivity; after all, there’s only so much we can learn from a model that doesn’t incorporate our internal data. So, a second track is to post-train and fine-tune open source LLMs using our organization’s own pre-processed data.
We used Code Llama 13B as our base LLM for this exercise, though that can be easily swapped for another if the need arises. To see how well a post-trained and fine-tuned existing LLM could work, we created what we call eBayCoder: Code Llama that’s trained on eBay’s codebase and associated documentation.
What worked? We found that eBayCoder was able to make some tasks that were previously labor- and time-intensive much easier. For example, software upkeep is critical in all technology organizations. Like other companies at scale, eBay has its own foundational libraries and frameworks built on top of open source software for servers, message queues, batch jobs, iOS, and Android. These systems should be periodically upgraded to improve developer ergonomics and address security vulnerabilities (e.g. upgrading to the latest Spring or Spring Boot). The effort varies from zero to huge, depending on the current version of the application stack. With the existing migration tools at eBay, we still spend significant engineering resources on software upkeep. This is one area where we believe a fine-tuned LLM can have a very large impact already in the short term.
With a codebase as large and varied as eBay’s, we also sometimes run into the problem that an existing commercial LLM offering would only have access to data and code that’s immediately relevant to that question, usually the surrounding files, the current repository, and a few dependent libraries. It may not be aware of a different internal service or a non-dependent library maintained by other groups that offer the same functionality currently being authored. This often leads to large amounts of code duplication. But a fine-tuned LLM can access as much context as we want, potentially reducing the amount of code duplication.

Track 3: An Internal Knowledge Base
A significant amount of productive time for any developer is spent in investigation. Some examples of those questions we encounter here at eBay: “Which API should I call to add an item to the cart?” “Where do I find the analytics dashboard for new buyers?” “How do I create a pipeline to deploy my application to production?”
At a large company, there is plenty of documentation, but it isn’t necessarily easy to access. Internal information is distributed across primary sources including enterprise GitHub Markdowns, Google Docs, Jira, Slack, and Wikis. Trying to find the answers to seemingly simple questions can sometimes require multiple meetings, dead ends, and red herrings – all of which adds up to reduced productivity and increased annoyance.
So we created an internal GPT that ingests certain data from relevant primary sources. You know how every team and every company has one employee who’s been there a long time and who you go to when you have a question and you aren’t even sure who to ask? That’s what we made. We want our most knowledgeable and experienced developers to focus on innovation.
What worked? At a high level, we used an Retrieval Augmented Generation (RAG) – a system that creates an embedding vector for each piece of content, which is then stored in a vector database. We were able to make this an automated, recurring task.
When someone enters a query, the system creates an embedding vector, and then uses a similarity mechanism (such as cosine similarity) to compare the query vector against all the known aforementioned content embedding vectors. This step finds the content and links most similar to the person’s query.
Now, with the query and context in hand, we call our private instance of commercial and open source LLMs with a question of the form: Answer the question as truthfully as possible using the provided context, and if the answer is not contained within the text below, say “I don’t know.”
We’re already seeing usage of our internal GPT rise each day, and have significant feedback from folks indicating that they appreciate its efficiency and relevance. To measure its effectiveness more precisely, we’re tracking how long it takes to complete everyday tasks, and also tracking the number of support and meeting requests. We’re excited to share our findings when our sample size is large enough, but early results are promising.
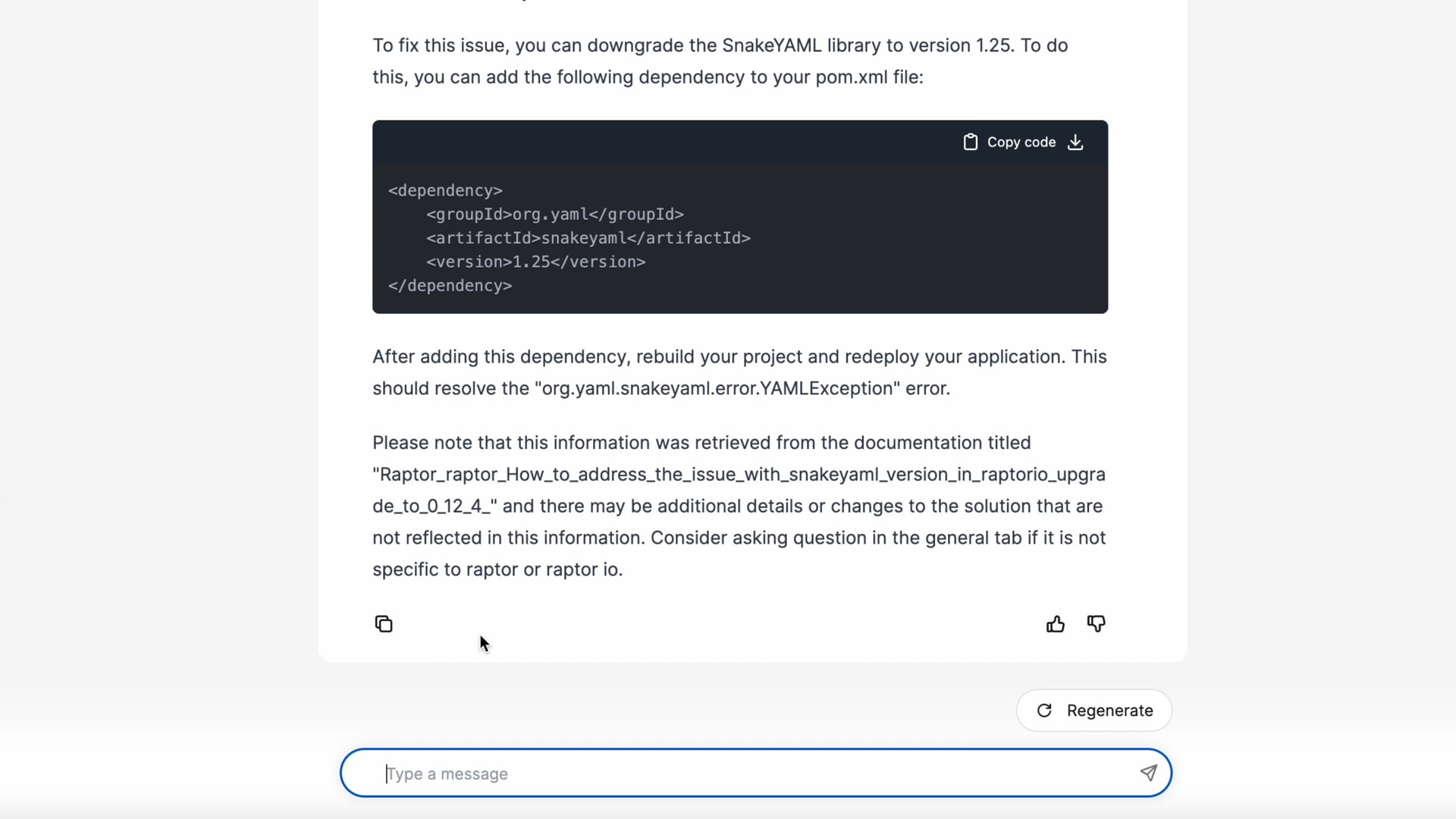
eBay’s internal GPT at work.
What didn’t work so well? Like with any automated chat system, sometimes these GPTs can deliver nonsensical answers. This can be frustrating or unhelpful at times, but can be improved with consistent effort. At eBay, we depend on our employees to give feedback through the user interface, which is then incorporated into the system itself. This technique – Reinforcement Learning from Human Feedback, or RLHF – can make the GPT better over time.
Conclusion
These three tracks form the backbone for generative AI developer productivity, and they keep a clear view of what they are and how they benefit each project. The way we develop software is changing. More importantly, the gains we realize from generative AI have a cumulative effect on daily work. The boost in developer productivity is at the beginning of an exponential curve, which we often underestimate, as the trouble with exponential growth is that the curve feels flat in the beginning.
As with any transformative technology, AI buzz can be deafening, and we are committed to cutting through the noise to address developer productivity needs efficiently.


