Editor’s note: In December 2021, we made the source code available to the community at github.com/ebay/block-aggregator under Apache License 2.0.
In a real-time data injection pipeline for analytical processing, efficient and fast data loading to a columnar database — such as ClickHouse[1] — favors large blocks over individual rows. Therefore, applications often rely on some buffering mechanism, such as Kafka, to store data temporarily. They also have a message-processing engine to aggregate Kafka messages into large blocks which then get loaded to the backend database. We call this message-processing engine the Block Aggregator. A naive aggregator that forms blocks without additional measures may cause data duplication or data loss. In this article, we present the solution we have developed to achieve the exactly-once delivery from Kafka to ClickHouse. Our solution has been developed and deployed to the production clusters that span multiple data centers at eBay.
Our ClickHouse and Kafka Deployment Model
Figure 1 shows our ClickHouse/Kafka deployment to achieve a scalable, highly available and fault-tolerant processing pipeline. The ClickHouse cluster and the associated Kafka clusters are deployed in multiple data centers (DCs). More details about the deployment below:
- Each ClickHouse cluster is sharded, and each shard has multiple replicas located in multiple DCs.
- The current deployment has four replicas across two DCs, where each DC has two replicas.
- We have two Kafka clusters each located in a different DC.
- Each ClickHouse replica simultaneously consumes Kafka messages of a single topic from both Kafka clusters.
The Block Aggregator is conceptually located between a Kafka topic and a ClickHouse replica. The number of the Kafka partitions for each topic in each Kafka cluster is configured to be the same as the number of the replicas defined in a ClickHouse shard. Kafka balances message consumption by assigning partitions to the consumers evenly. As a result, under normal situations, one ClickHouse replica is assigned with one partition of the topic from each of the two Kafka clusters. When one ClickHouse replica is down, the corresponding partition is picked up by another ClickHouse replica in the same shard. For two-DC ClickHouse deployment configuration, we can tolerate two ClickHouse replicas being down at the same time in the entire DC.
With respect to the Kafka clusters deployed in two DCs, as each ClickHouse replica simultaneously consumes messages from both Kafka clusters, when one DC goes down, we still have the other active Kafka cluster to accept the messages produced from the client application and allow the active ClickHouse replicas to consume the messages.
To simplify the topics management in the Kafka cluster, each ClickHouse shard is assigned with a unique topic in each Kafka cluster. One topic contains messages (rows) that are associated with multiple tables defined in ClickHouse. With this deployment model, when a user-defined table gets added to ClickHouse, we do not need to make any changes to Kafka clusters that can have hundreds of topics. Furthermore, as a ClickHouse cluster often has multiple tables, the number of the topics does not grow as the tables continue to be added to the cluster.
For the Kafka messages consumed from the two Kafka clusters: If they are associated with the same table when the corresponding blocks get inserted, all messages (rows) will be stored into the same table and get merged over time by the ClickHouse’s background merging process.
Given this is a highly scalable and distributed system, failures can happen to the real-time injection pipeline between the Kafka broker, the Block Aggregator and the ClickHouse replica; in those failure instances, the Block Aggregator can retry sending the data to ClickHouse. However, resending data may cause data duplication. To avoid data duplication, ClickHouse provides a block-level deduplication mechanism[2]. The challenge now is how to deterministically produce identical blocks by the Block Aggregator from the shared streams shown in Figure 1, and to avoid data duplication or data loss.
Kafka Engine: Can’t Handle Multi-table Topic Consumption and Avoid Data Duplication
Currently, ClickHouse provides a table engine called Kafka Engine[3] to consume Kafka messages; convert the messages into table rows; and persist the table rows into the destination table. Although a Kafka engine can be configured with multiple topics, a Kafka engine can only have one table schema defined. Therefore, the Kafka engine cannot be used in our ClickHouse deployment that needs to handle messages that belong to multiple tables. In addition, the Kafka engine only supports at-least-once guarantee[4, 5]. The reason that the official Kafka engine only provides at-least-once guarantee is that it first loads the data to the ClickHouse and then commits offset back to Kafka. Now, if the Kafka engine process crashes after loading data to ClickHouse and fails to commit offset back to Kafka, data will be loaded to ClickHouse by the next Kafka engine process causing data duplication.
Block Aggregator Architecture
We have developed our own Block Aggregator to consume the Kafka messages, accumulate the messages into the ClickHouse blocks and then send the blocks to the ClickHouse shard. The Block Aggregators of different replicas retry sending the blocks in case of failures in a way that each message will be part of the same identical block, irrespective of which replica is retrying. This will avoid data duplication while letting us prevent data loss in case of failures.
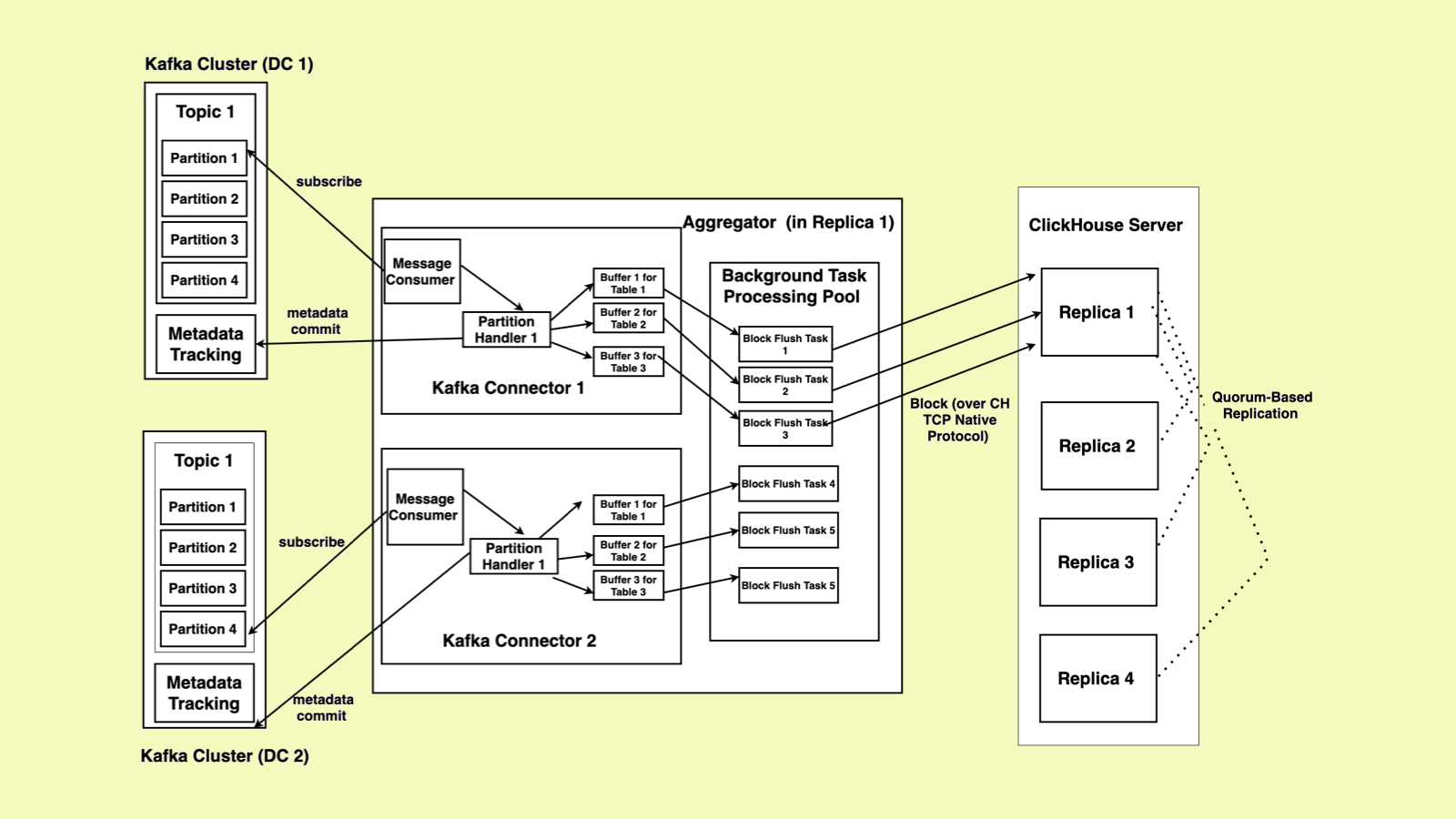
Figure 2: The Architecture of Block Aggregator
Shown in Figure 2, a Block Aggregator is a process co-located with a ClickHouse replica process in a compute node. In Kubernetes, both the Block Aggregator and the ClickHouse replica are hosted in two different containers in the same pod. In the Block Aggregator, two Kafka Connectors are launched, each of which subscribing to a topic that belongs to one of the two Kafka clusters — each in a separate DC as we mentioned before. Since the number of the partitions in each topic is configured to be the same as the number of the replicas, each Block Aggregator can receive balanced Kafka message loads in a shard.
The client application publishes table rows as Kafka messages into the Kafka broker, with each table row being encoded in protobuf format for each message. Multiple rows can be batched for better efficiency. The Block Aggregator retrieves table schema definition from the co-located ClickHouse replica at the start time and also later whenever a new table is introduced or the existing table’s schema gets updated. Based on the table schema, the Block Aggregator dynamically constructs a binary row de-serializer to decode the Kafka messages.
After subscribing to the topic, each Kafka connector starts to consume messages from the Kafka broker via its message consumer. The message consumer then sorts the message and hands it to the corresponding partition handler (it is possible that a Kafka connector gets assigned with more than one partition when re-partitioning happens and thus each Block Aggregator may have more than one partition handler accordingly). The partition handler identifies the table name from the Kafka message and constructs the corresponding table de-serializer to reconstruct the rows from the Kafka message.
Each row inserted gets accumulated into a ClickHouse block. Once the block reaches a threshold (either its block size reaches the maximum byte size — such as 10 MB — or the lifetime of the block reaches some time limit, such as one second), the block is sealed and a block flushing task is submitted to a background processing pool. The block flushing task relies on ClickHouse’s native TCP/IP protocol to insert the block into its corresponding ClickHouse replica and gets persisted into ClickHouse. We choose insert quorum = 2 to force two replicas to have the same data copies before the block flushing task gets successful acknowledgement.
The offsets of the processed messages and other metadata get persisted to the Kafka’s metadata tracking store (a built-in Kafka topic) by the partition handler. As we will explain in Section 4 in detail, this information will be used by the next Block Aggregator in case of the failure of the current Block Aggregator.
By having the Block Aggregator to fully take care of Kafka message consumption and ClickHouse block insertion, we are able to support the following features that the Kafka Engine from the ClickHouse distribution cannot offer:
- Multiple tables per topic/partition;
- No data loss/duplication;
- Better visibility by introducing over one hundred metrics to monitor the Kafka message processing rates, block insertion rate and its failure rate, block size distribution, block loading time, Kafka metadata commit time and its failure rate, and whether some abnormal Kafka message consumption behaviors have happened (such as message offset being re-wound).
In the rest of this article, we will focus on the protocol and algorithms that we have developed in the Block Aggregator to avoid data duplication and data loss, under multi-table topic consumption.
The Deterministic Message Replay Protocol
As explained above, the job of the Block Aggregator is to consume messages from Kafka, form large blocks and load them to ClickHouse. A naive Block Aggregator that forms blocks without additional measures can potentially cause either data duplication or data loss.
For example, consider a simple Block Aggregator that works as follows: the Block Aggregator consumes messages and adds them to a buffer. Once the buffer reaches a certain size, the Block Aggregator flushes it to ClickHouse. After ClickHouse acknowledges loading the block, the Block Aggregator commits offset to Kafka thereby marking the position up to which we are done with processing the Kafka messages. Now, consider the scenario where the Block Aggregator fails right after flushing the block to ClickHouse and before committing offset to Kafka. In this case, the next Block Aggregator will re-consume the messages already loaded to ClickHouse causing data duplication.
On the other hand, suppose we change the Block Aggregator’s algorithm such that it first commits the offset to Kafka and then loads data to ClickHouse. In this case, however, we will have data loss if the Block Aggregator crashes after committing offset to Kafka and before flushing the block to ClickHouse. Therefore, neither of these algorithms can guarantee that data is loaded to ClickHouse exactly one time.
One solution to this problem is to make sure we load the block to ClickHouse and commit offset to Kafka atomically using an atomic commit protocol such as 2-Phase Commit (2PC). However, 2PC comes with its costs and complications. Instead of using an atomic commit protocol — such as the traditional 2PC — we use a different approach that utilizes the native block deduplication mechanism offered by the ClickHouse[2]. Specifically, ClickHouse deduplicates “identical blocks” (i.e., blocks with the same size), containing the same rows in the same order. If we somehow make sure that our retries are in the form of identical blocks, then we avoid data duplication while we are re-sending data. To form identical blocks, we store metadata back to Kafka which describes the latest blocks formed for each table. Using this metadata, in case of a failure of the Block Aggregator, the next Block Aggregator that picks up the partition will know exactly how to reconstruct the latest blocks formed for each table by the previous Block Aggregator. Note that the two Block Aggregators described here can be two different instances co-located in two different ClickHouse replicas shown in Figure 2.
Whenever a Block Aggregator is assigned a partition, it retrieves the stored metadata from Kafka, and starts to consume from the recorded offset. The message consumption is divided into two phases. The Block Aggregator first starts in the REPLAY mode where it deterministically reproduces the latest blocks formed by the previous Block Aggregator. After all of these blocks (one block for each table) are formed and loaded to ClickHouse, the Block Aggregator changes to the CONSUME mode where it normally consumes and forms the blocks. In the CONSUME mode, the Block Aggregator keeps track of blocks for each table. Specifically, for each table, it keeps track of the start and end offsets of the messages included in the current buffer for the table.
Once a buffer is ready to be flushed to ClickHouse, the Block Aggregator commits the metadata to Kafka, and then flushes the blocks to ClickHouse. Thus, we don’t flush any block to ClickHouse, unless we have recorded our “intention to flush” on Kafka. If the Block Aggregator crashes, the next Block Aggregator will retry to avoid data loss, and since we have committed the metadata, the next Block Aggregator knows exactly how to form the identical blocks. If the previous try by the previous Block Aggregator was indeed successful and blocks were loaded to ClickHouse, we won’t have data duplication, as ClickHouse is guaranteed to de-duplicate the identical blocks.
The layout of the metadata is shown in Figure 3.
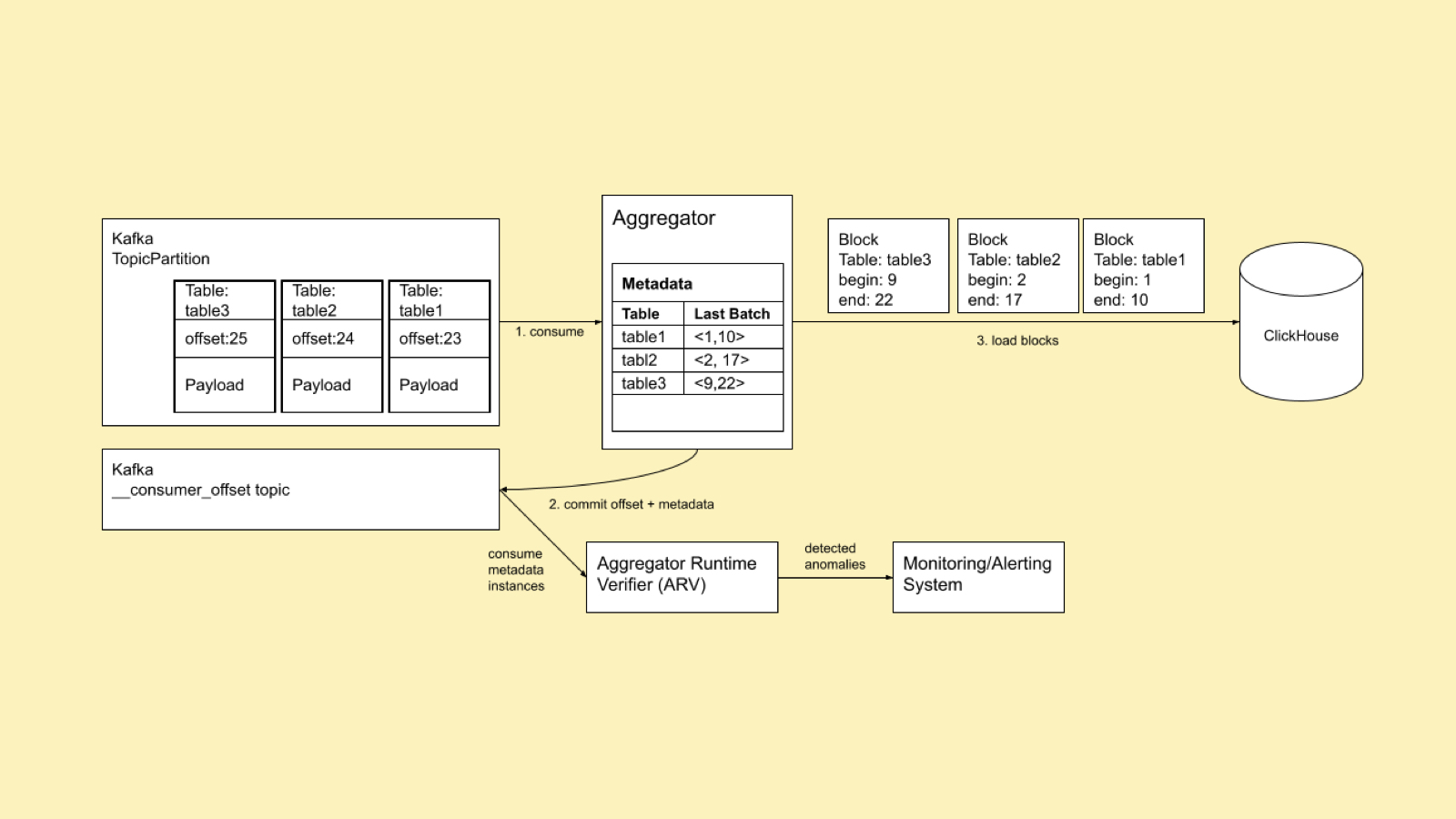
Figure 3: The Layout of the Metadata Used in Block Aggregator
The metadata keeps track of the start and end offsets for each table. Thus, we can represent the metadata as follows: table1, start1, end2, table2, start2, end2, … . We define the minimum offset of a metadata instance as the minimum of its start offsets. When we want to store metadata M to Kafka, we commit offset = M.min to Kafka. This causes Kafka to consider any message with an offset less than M.min successfully processed. Thus, in case of a failure of a Block Aggregator, the next Block Aggregator starts consuming from M.min.
We have designed an algorithm that efficiently implements the approach explained above for streams of messages destined at different tables.
The Aggregator Runtime Verifier
To make sure that our system is working properly without data duplication and data loss, we have designed a component called Aggregator Runtime Verifier (ARV). In our system, ARV is a separate program written in NodeJs. The job of ARV is to analyze the history of the system and make sure that we don’t have any anomalies leading to data loss/duplication. Since we commit metadata to Kafka, we have the whole history of our system in an internal Kafka topic called __consumer_offset. Thus, the ARV subscribes to the __consumer_offset topic and analyzes the metadata instances committed by the Block Aggregators. The ARV raises an alert whenever it detects an anomaly. To detect data loss, we augment metadata with more information. Specifically, in addition to the start and end offsets for each table, we keep track of the number of messages sent for each table starting from a common reference offset.
Let M.t.start and M.t.end be the start offset and end offset for table t in metadata M, respectively. Let M.count be the number of messages consumed for all tables starting from M.reference. The ARV looks for the following anomalies for any given metadata instances M and M’:
Backward Anomaly: For some table t, M’.t.end < M.t.start.
Overlap Anomaly: For some table t, M.t.start < M’.t.end AND M’.t.start < M’.t.start.
Gap Anomaly: M.reference + M.count < M’.min
ARV checks the above anomalies for each M and M’ where M is right before M’ in the sequence of the metadata instances committed to the __consumer_offset for each partition. For this approach, ARV needs to read metadata instances in the order they are committed to Kafka. However, the __consumer_offset is a partitioned topic and Kafka does not guarantee order across partitions. To solve this issue, we put metadata instances to a minimum heap according to their commit timestamp, and run the verification periodically by reading and popping the top of the heap. This approach, however, requires the clock of the Kafka brokers to be synchronized with an uncertainty window less than the time between committing two metadata instances. In other words, we should not commit metadata to Kafka too frequently. This is not a problem in our system, as we commit metadata to Kafka for each block every several seconds, which is not very frequent compared to the clock skew. Whenever we don’t have backward and overlap anomalies, we are guaranteed that we don’t have data duplication due to block formation. However, for data loss, we have to periodically flush all blocks that we have accumulated. At these forced flush points, the Block Aggregator flushes any buffer that it has accumulated disregarding its size or lifetime and resets the reference. Now, when we don’t have any gap anomalies, we are guaranteed that we don’t have any data loss.
We have deployed ARV in our production systems. It continuously monitors all blocks that Block Aggregators form and load to ClickHouse as explained above. Having ARV running in our system gives us confidence that we don’t have data loss/duplication due to continuous partition rebalances by Kafka in our message processing pipeline.
Conclusions
We have developed a Block Aggregator as a Kafka consumer to load data into ClickHouse in large blocks. It is deployed as part of a scalable, highly available and fault-tolerant processing pipeline that has Kafka clusters and the ClickHouse clusters hosted in a multi-DC environment. The multi-table per partition and data duplication avoidance are the two main reasons that prevent us from adopting the Kafka Engine of ClickHouse in our system. We presented the protocol and algorithms that we have developed for the Block Aggregator to address data duplication and data loss. The entire system shown in Figure 1 is already in production. In our current largest deployment, we have close to 1 million rows/second to be inserted by the Block Aggregators.
References
[1] ClickHouse architecture document, https://clickhouse.tech/docs/en/development/architecture/
[2] ClickHouse block de-duplication, https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/replication/
[3] ClickHouse Kafka Engine, https://clickhouse.tech/docs/en/engines/table-engines/integrations/kafka/
[4] ClickHouse Kafka Engine at-least-once delivery, https://altinity.com/blog/clickhouse-kafka-engine-faq
[5] ClickHouse GitHub Issue on Kafka Engine’s exactly-once semantics, https://github.com/ClickHouse/ClickHouse/issues/20285