
With the releases of Apache Spark 3.4 and 3.5 in 2023, we focused heavily on improving PySpark performance, flexibility, and ease of use. This blog post walks you through the key improvements.
Here’s a rundown of some of the most important features added in Apache Spark 3.4 and 3.5 in 2023:
- Spark Connect introduces a decoupled client-server architecture that permits remote connectivity to Spark clusters from any application. Thus, Spark as a service is enabled while also enhancing stability, upgradability, and observability.
- With Arrow-optimized Python user-defined functions (UDFs), we leveraged the Arrow columnar format to double the performance of regular Python UDFs, demonstrating a leap forward in efficiency.
- With Python user-defined table functions (UDTFs), users can now perform table-based transformations natively in PySpark.
- New Spark SQL features, such as GROUP BY ALL and ORDER BY ALL, were introduced; these can all be used natively from PySpark.
- Python arbitrary stateful processing provides the ability to maintain arbitrary state in streaming queries.
- TorchDistributor supports distributed PyTorch training on Apache Spark clusters.
- The new testing API enables effective testing of PySpark applications and helps developers produce high-quality code.
- The English SDK is an LLM-powered approach to programming that allows commands in plain English to be transformed into PySpark and SQL, thus boosting developer productivity.
In the following section, we’ll examine each of these and provide pointers to some additional notable improvements.
Apache Spark 3.5 and 3.4: Feature Deep Dives
Spark Connect: Remote connectivity for Apache Spark
Spark Connect debuted in Apache Spark 3.4, introducing a decoupled client-server architecture that enables remote connectivity to Spark clusters from any application running anywhere. This separation of the client and server allows modern data applications, IDEs, notebooks, and programming languages to access Spark interactively. Furthermore, the decoupled architecture improves stability, upgradability, debuggability, and observability.
In Apache Spark 3.5, Scala support was completed, as well as support for major Spark components such as Structured Streaming (SPARK-42938), ML and PyTorch (SPARK-42471), and the Pandas API on Spark (SPARK-42497).
Use Databricks Connect to get started with Spark Connect on Databricks or Spark Connect directly for Apache Spark.
Arrow-optimized Python UDFs: Boosting the performance of Python UDFs
Arrow-optimized Python UDFs (SPARK-40307) enable substantial performance optimizations by leveraging the Arrow columnar format. For example, when chaining UDFs in the same cluster, Arrow-optimized Python UDFs execute ~1.9 times faster than pickled Python UDFs on a 32 GB dataset.
Python UDTFs
In Apache Spark 3.5, we extended PySpark’s UDF support with user-defined table functions, which return a table as output instead of a single scalar result value. Once registered, they can appear in the FROM clause of a SQL query. For example, the UDTF SquareNumbers outputs the inputs and their squared values as a table:
from pyspark.sql.functions import udtf
@udtf(returnType="num: int, squared: int")
class SquareNumbers:
def eval(self, start: int, end: int):
for num in range(start, end + 1):
yield (num, num * num)from pyspark.sql.functions import lit
SquareNumbers(lit(1), lit(3)).show()
+---+-------+
|num|squared|
+---+-------+
| 1| 1|
| 2| 4|
| 3| 9|
+---+-------+New SQL Features
One of the major benefits of PySpark is that Spark SQL works seamlessly with PySpark DataFrames. In 2023, Spark SQL introduced many new features that PySpark can leverage directly via spark.sql, such as GROUP BY ALL and ORDER BY ALL, general table-valued function support, INSERT BY NAME, PIVOT and MELT, ANSI compliance, and more. Here’s an example of using GROUP BY ALL and ORDER BY ALL:
spark.sql("""
SELECT name, firstname, level, sum(comp) as totalcomp
FROM {table}
GROUP BY ALL
ORDER BY ALL
""", table=df)Python arbitrary stateful processing
Python arbitrary stateful operations in Structured Streaming unblock a massive number of real-time analytics and machine learning use cases in PySpark by allowing state processing across streaming query executions. The following example demonstrates arbitrary stateful processing:
# Group the data by word, and compute the count of each group
output_schema = "session STRING, count LONG"
state_schema = "count LONG"
sessions = events.groupBy(events["session"]).applyInPandasWithState(
func,
output_schema,
state_schema,
"append",
GroupStateTimeout.ProcessingTimeTimeout,
)
# Start running the query that prints the windowed word counts to the console
query = sessions.writeStream.foreachBatch(
lambda df, _: df.show()).start()TorchDistributor: Native PyTorch Integration
TorchDistributor provides native support in PySpark for PyTorch, which enables distributed training of deep learning models on Spark clusters. It starts the PyTorch processes and leaves it to PyTorch to work out the distribution mechanisms, acting just to ensure that the processes are coordinated.
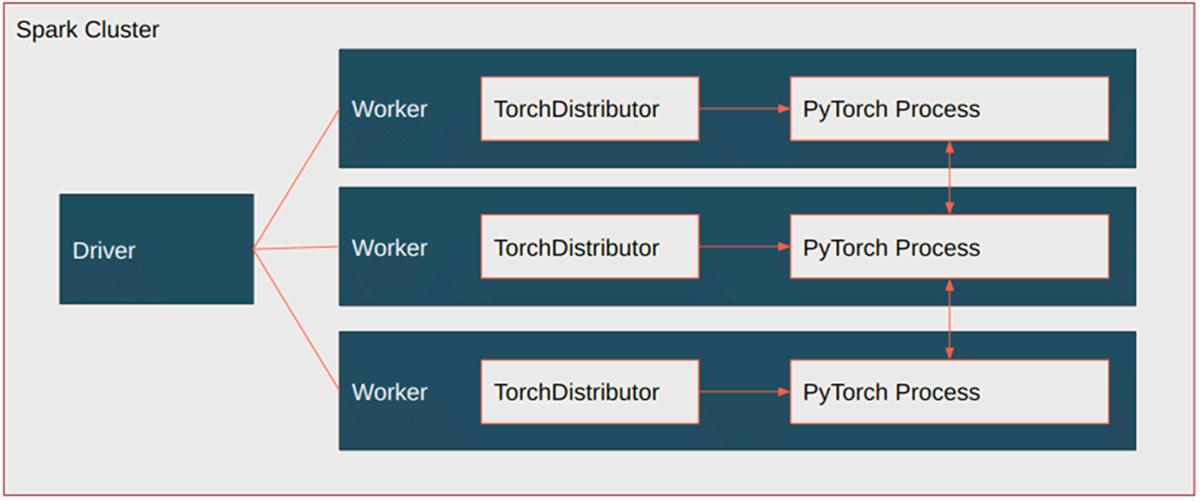
TorchDistributor is simple to use, with a few main settings to consider:
from pyspark.ml.torch.distributor import TorchDistributor
model = TorchDistributor(
num_processes=2,
local_mode=True,
use_gpu=True,
).run(<function_or_script>, <args>)Testing API: Easier Testing for PySpark DataFrames
The new testing API in the pyspark.testing package (SPARK-44042) brings significant enhancements for developers testing PySpark applications. It provides utility functions for equality tests, complete with detailed error messages, making identifying discrepancies in DataFrame schemas and data easier. The example output below illustrates:
*** actual ***
Row(name='Amy', languages=['C++', 'Rust'])
! Row(name='Jane', languages=['Scala', 'SQL', 'Java'])
*** expected ***
Row(name='Amy', languages=['C++', 'Rust'])
! Row(name='Jane', languages=['Scala', 'Java'])English SDK: English as a Programing Language
The English SDK for Apache Spark simplifies its use by enabling users to input commands in plain English and then convert them into PySpark and Spark SQL code. This makes PySpark programming more accessible, especially for code related to DataFrame transformation operations, data ingestion, and UDFs, and thanks to caching it further boosts productivity. The English SDK has great potential to streamline development processes, minimize code complexity, and expand the Spark community’s reach. Try it out yourself!
Other Notable Improvements
Here are some of the other features introduced in Apache Spark 3.4 and 3.5 that you might want to explore if you aren’t familiar with them already:
Reflections and the Road Ahead
In 2023, vibrant innovation from the open-source community significantly enriched both PySpark and Apache Spark, broadening the toolkits available for data professionals and streamlining analytics workflows. With Apache Spark 4.0 on the horizon, PySpark is poised to further revolutionize data processing through new features and enhanced performance, reaffirming its commitment to advancing data analytics within the data engineering and data science community.
Getting Started with the New Features
This post provided a quick overview of the most significant improvements made in Apache Spark 3.4 and 3.5 in 2023 to enhance the ease of use, performance, and flexibility of PySpark. All of these features are available in Databricks Runtime 13 and 14—why not try some of them out for yourself today?


