
Background
It might sound paradoxical to deliberately break something we’re trying to fix, but sometimes, that’s the most efficient method to do it. Fault injection is the process by which we deliberately introduce faults into the system. We can observe the system behavior with the injected faults to identify the weakness of the system. Within the industry, fault injection is a common practice as a means to build fault-tolerant, resilient systems.
The eBay notification platform team practiced the idea of fault injection from a different perspective in eBay’s notification platform. This platform is responsible for pushing platform notifications to third party applications to provide the latest changes in item price, item stock status, payment status and more. It is a highly distributed and large-scale system relying on many external dependencies, including distributed store, message queue, push notification endpoints and others. Any faults in these dependent services will directly impact the stability of the system, so it’s quite valuable to run experiments in the system containing the failures of these dependencies, in order to understand the behaviors and mitigate any weaknesses.
To achieve this, the faults are injected by simulation in the application level by the code instrumentation. As far as we know, we are the very first in the industry to practice this idea officially and widely to experiment on the mission-critical system with different kinds of deliberately designed faults.
Application Level vs Infrastructure Level
There is no unified way to inject these faults. The most straightforward and ubiquitous way to do so in the industry is to create real faults directly. For example, to introduce the http disconnection or timeout error, one option is to turn off the network or shut down the downstream services temporarily; to introduce the disk full error, one option is to create a bunch of files in the file system. We can think of this as fault injection at the infrastructure level, and if we think about it from this perspective, it will inevitably drive us to create the concrete faults for the infrastructure resources. Creating faults will directly harm the infrastructure resources; turning off the network obviously causes many issues, in the previous example. If the resource is shared, this will introduce extra impacts and risks to other services depending on it. If the resource is dedicated, it will increase the cost.
But there is a different way to approach this problem: Instead of creating faults at the infrastructure level, what if we created them at the application level? This would allow us to simulate the faults we’d like to use with the application API leveraged to talk with the infrastructure resources. For example, to inject the http timeout fault, we add the latency in the http client library; to simulate the internal service error, we simulate the response code with 500 http status code. The faults are restricted to the API level and do no harm to the underlying infrastructure resources. In this way, we’ve found an affordable, secure and reusable way to do fault injection.
As our service is a Java-based application, we’ve provided a Java agent. Within it, we instrumented the class files of the client libraries for the dependent services to introduce different kinds of faults we defined. The introduced faults are raised when our service communicates with the underlying resource through the instrumented API. The faults do not really happen in our dependent services, owing to the changed codes, but the effect is simulated, enabling us to experiment without risk.
Instrumentation
To simulate the faults for the client libraries by instrumentation is challenging. Our main task is to force the invoked methods to experience failures. One method to do this is to inject failure directly into the method, by, for example, throwing the exception in the method body. The other method calls for changing the value or the state of the input parameters to drive the method to go to the failure execution path. There are three instrumentation patterns in our project.
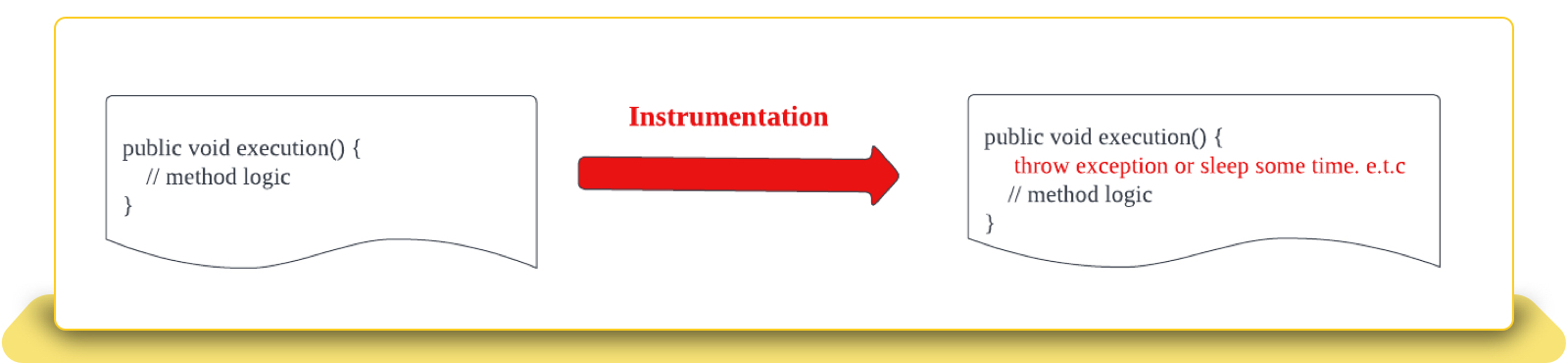
1. Block or interrupt the method logic
This type of instrumentation is straightforward in that the API can throw exceptions or sleep for a specific period of time to simulate the error or timeout.
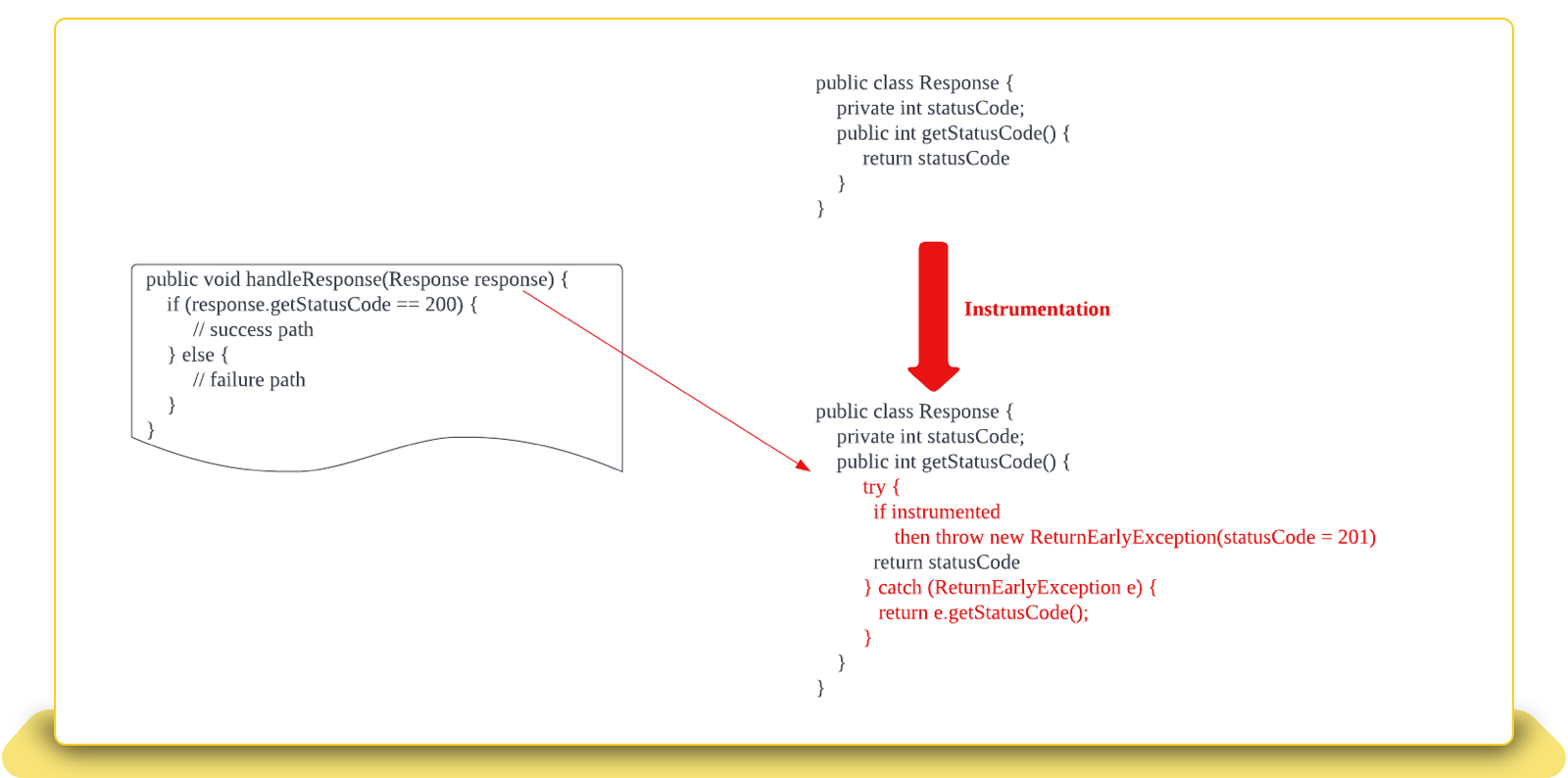
2. Change the state of method parameters
Under some circumstances, the simulation of faults will depend on the specific state of the input parameters. For example, the below method logic is depending on the return value of the response.getStatusCode(). If the value does not equal 200, the failure logic will be triggered. So if we want to simulate the faults with failure code, then we need to find a way to change the state of response which will be returned from the response.getStatusCode().
The way we achieved this is to add the instrumented code snippet to throw a specific defined exception and let the exception carry the response code we need to simulate. Meanwhile, we instrument the method by adding the try-catch block to the method to specifically catch the exception we throw and return the code in the catch block. By doing so, we’ve changed the method execution path to return the designated value.
3. Replace the value of method parameters
In contrast to the above example, sometimes the method logic will depend on the value of the parameters. So if you want to simulate a fault, then you need to change the value of the input parameter. To change the value of the parameter, we need to know the name of the parameter first and inject the code to replace the value for the parameter with its name. This is not easy because the parameter name can only be known in the runtime. So we leverage the Java reflection to get the names of the parameters in the runtime.
 To implement the above three types of instrumentation, we have created a Java agent. In the agent, we have implemented a classloader which will instrument the code of the methods leveraged in the application code. We also created an annotation to indicate which method will be instrumented and put the instrumentation logic in the methods annotated. Here’s an example:
To implement the above three types of instrumentation, we have created a Java agent. In the agent, we have implemented a classloader which will instrument the code of the methods leveraged in the application code. We also created an annotation to indicate which method will be instrumented and put the instrumentation logic in the methods annotated. Here’s an example:
 In the above code snippet, we’d like to provide the instrumentation logic for org.asynchttpclient.providers.netty.future.NettyResponseFuture.done(). So what we do is to create a new method with the same signature, and make it be annotated by @Enforce, which is the user-defined Java annotation used to indicate the instrumentation logic for fault injection. The annotation has two fields: value and type. The value field is the class name of the method we want to instrument. (We’ll discuss the type field shortly.) When the agent is loaded, the defined class loader will find all the methods annotated by @Enforce and inject the instrumentation logic defined in the methods to the methods to be instrumented. The type field of @Enforce has the two values runtime(default value) and static. In the above example, we implement the instrumentation logic with the Java code. But there remains a chance that we might need to provide the instrumentation logic with a string literal. Here’s an example of that:
In the above code snippet, we’d like to provide the instrumentation logic for org.asynchttpclient.providers.netty.future.NettyResponseFuture.done(). So what we do is to create a new method with the same signature, and make it be annotated by @Enforce, which is the user-defined Java annotation used to indicate the instrumentation logic for fault injection. The annotation has two fields: value and type. The value field is the class name of the method we want to instrument. (We’ll discuss the type field shortly.) When the agent is loaded, the defined class loader will find all the methods annotated by @Enforce and inject the instrumentation logic defined in the methods to the methods to be instrumented. The type field of @Enforce has the two values runtime(default value) and static. In the above example, we implement the instrumentation logic with the Java code. But there remains a chance that we might need to provide the instrumentation logic with a string literal. Here’s an example of that:

Customized Class Loader
Now we have implemented the instrumentation logic in the Java agent. However, we still need to create a customized class loader to inject the instrumentation logic in the target methods of the client libraries into which we want to inject faults. The class loader leverages Javassist, the instrument library, which can manipulate the Java bytecode to transform the class files of the target methods to include the defined faults.
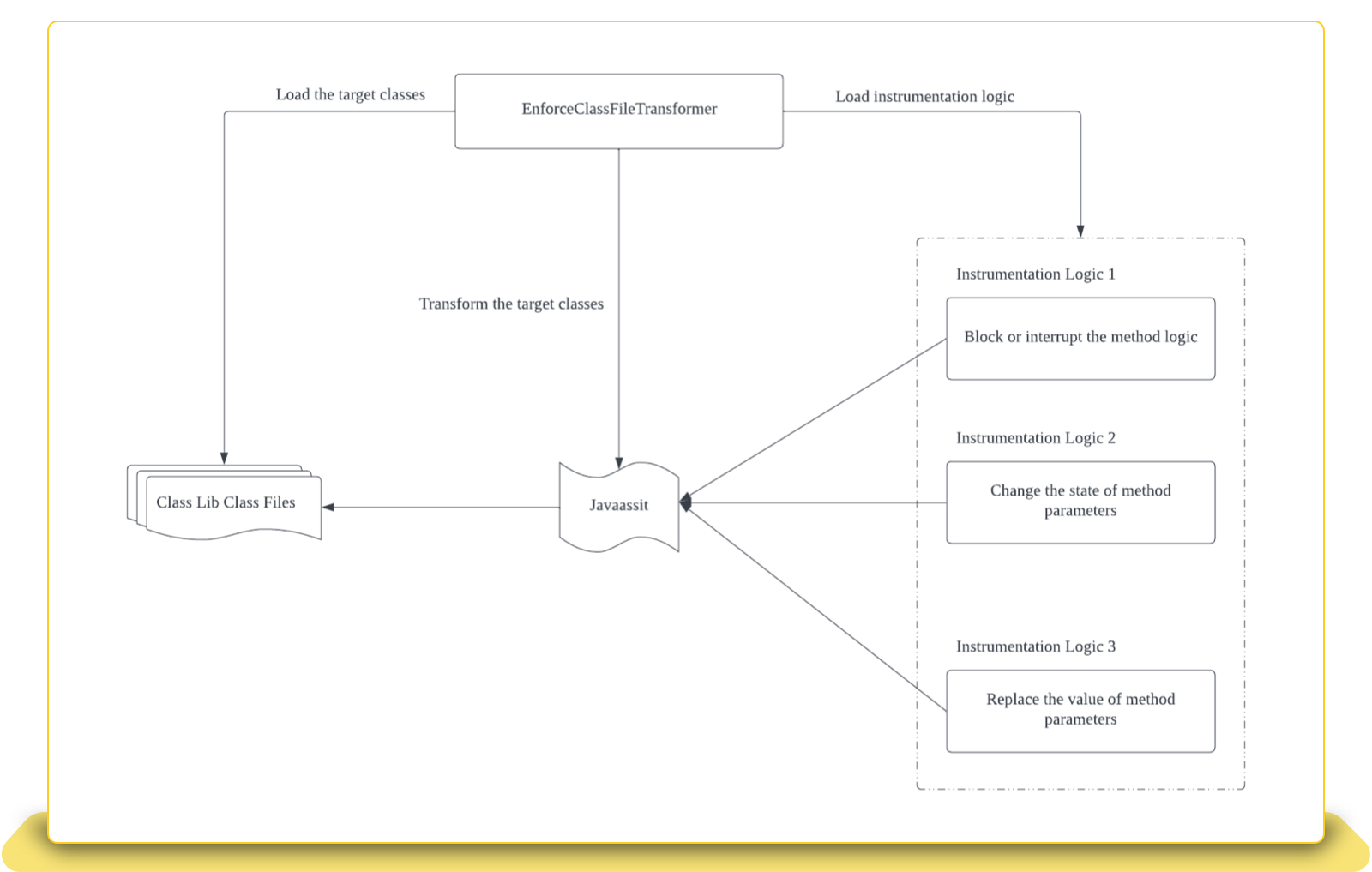
With the above implementation described, we have injected the faults by instrumentation for the below client libraries of the three resources we are depending on.
Configuration Management
To dynamically change the configuration for the fault injections in the runtime, we have implemented a configure management console in the Java agent. As our service is a web application, we can instrument the javax.servlet.http.HttpServlet.service(HttpServletRequest, HttpServletResponse) to expose the endpoints for the configure management. The endpoint will render a configuration page to let developers configure the attributes of the fault injection in the runtime. For example, a developer could globally enable or disable the fault injection and other subtypes of the faults; for example, a timeout for AyncHttpClient.
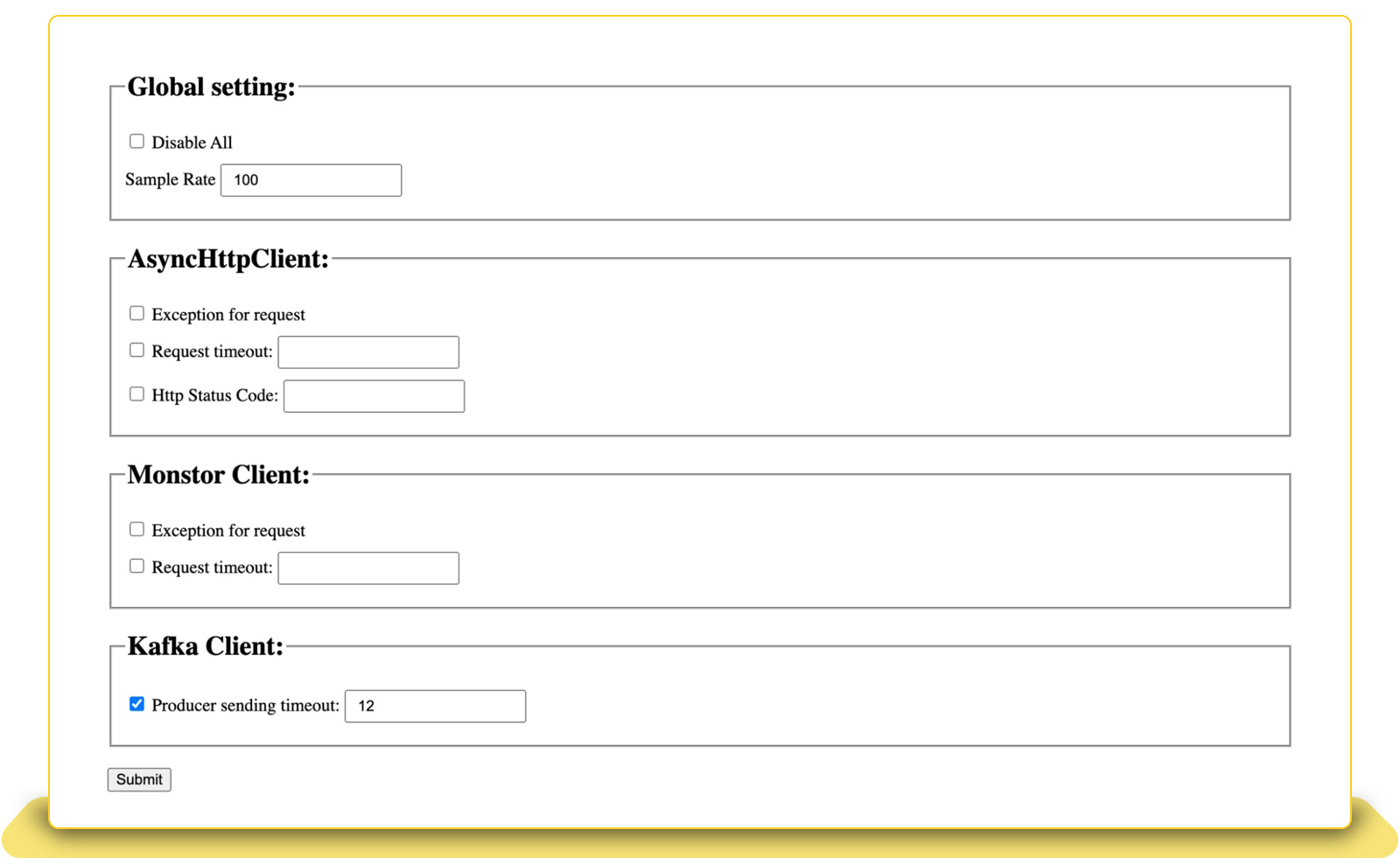
What’s Next
We will expand the scope of the application level fault injection in more client libraries and fault categories to diversify the scenarios of experiments for our services under different kinds of fault circumstances. Meanwhile, as the configuration of the faults setting through the configuration management console can only be triggered at the instance level, we will find a way to broadcast the changes across the cluster.


