Introduction
When shoppers come to eBay, our goal is to help them easily find a product they’ll love. Our newly launched recommendation model, commonly referred to as a “ranker,” now provides more relevant product recommendations by leveraging deep learning Natural Language Processing (NLP) techniques to encode item titles as semantic embeddings via a Bidirectional Encoder Representations from Transformers (BERT1) model. We apply these embeddings to generate a distance score between items to use as a feature in our ranker. This new approach allows for better understanding of the most important information in the item title from a semantic perspective, especially given that sellers often put important descriptors in their item titles. Thus, buyers will receive improved item recommendations that are more relevant and aligned to their shopping interests, while sellers’ promoted items will be shown in the right context.
Background
There are different stages of a buyer’s shopping journey, often referred to as the “funnel.” In the “lower funnel stage” of the journey, buyers have identified the product or item type they are interested in within the eBay marketplace and clicked on a product listing. On the product listing page, there are several modules recommending items to the buyer based on different themes. The top module “Similar Sponsored Items” recommends similar items with respect to the main item on the page, which we call the “seed” item.This module enables shoppers to compare different listings promoted2 by sellers for the particular item they want to buy, and to find the item with the right price, seller, shipping speed and condition for their needs. Recently our team has introduced several improvements to the ranking engine that generates recommendations for the “Similar Sponsored Items” module, as seen below.
Machine Learning Ranking Engine
Our Promoted Listing SIM (PLSIM3) ranking engine has three stages. It:
-
Retrieves a subset of candidate PLS items (the “recall set”) that are most relevant to the seed item.
-
Applies a trained machine learning ranker to rank the listings in the recall set according to the likelihood of purchase.
-
Re-ranks the listings by incorporating seller ad-rate, in order to balance seller velocity enabled through promotion with the relevance of recommendations.
The ranking model in Stage 2 of the engine is trained offline on historical data. The features, or variables, of the ranking model include data such as:
-
Recommended item historical data
-
Recommended item to seed item similarity
-
Context (country, product category)
-
User personalization features
We iteratively train versions of the model as we innovate new features, using a Gradient Boosted Tree (GBT) to rank items according to items’ relative purchase probabilities. Furthermore, the recent incorporation of new deep-learning-based features in the item to item similarity category have resulted in significant uplift to model performance.
Title Similarity Features
When experimenting with new features in a machine learning model, it is important to not only consider how the model’s performance evaluation metrics change, but also the importance of the new features to the model. Within the context of GBTs, this importance is referred to as the “gain,” meaning the relative contribution of each feature to the model. A higher “gain” when compared to another feature implies it is more important for generating a prediction within a tree.
One of the most influential feature sets in our recommendation ranking models pertains to the degree of similarity between the title of the item currently being viewed by the buyer and a candidate item for recommendation. Our previous recommendation ranking models evaluated title similarity by comparing title keywords using Term Frequency-Inverse Document Frequency (TF-IDF4) as well as the Jaccard similarity coefficient5. These measures have basic limitations when it comes to handling synonyms and complex or lengthy titles with lots of item descriptors. For instance, the colors “red” and “crimson” have zero common words. Hence such pairs will be treated as very dissimilar items by traditional token-based methods like TF-IDF or Jaccard metrics, while in fact they represent nearly the same meaning.
Fine-Tuned Siamese MicroBERT
The well-known BERT model has exhibited solid performance on language understanding tasks across the board. BERT is a pre-trained model that leverages an extensive amount of unlabeled data – sentences from the Wikipedia and Toronto Books corpora – which enables it to recognize semantically similar words (i.e. synonyms) as well as generate contextualized word embeddings. For example, the embedding of the word “server” would be different in the sentence “The server crashed” versus the sentence “Can you ask the server for the bill?” Pre-trained BERT models can be fine-tuned to solve different NLP problems by adding task-specific layers which map the contextualized word embeddings into the desired output function. Many studies show that fine-tuning pre-trained models for a specific task yields the best performance among all existing approaches.
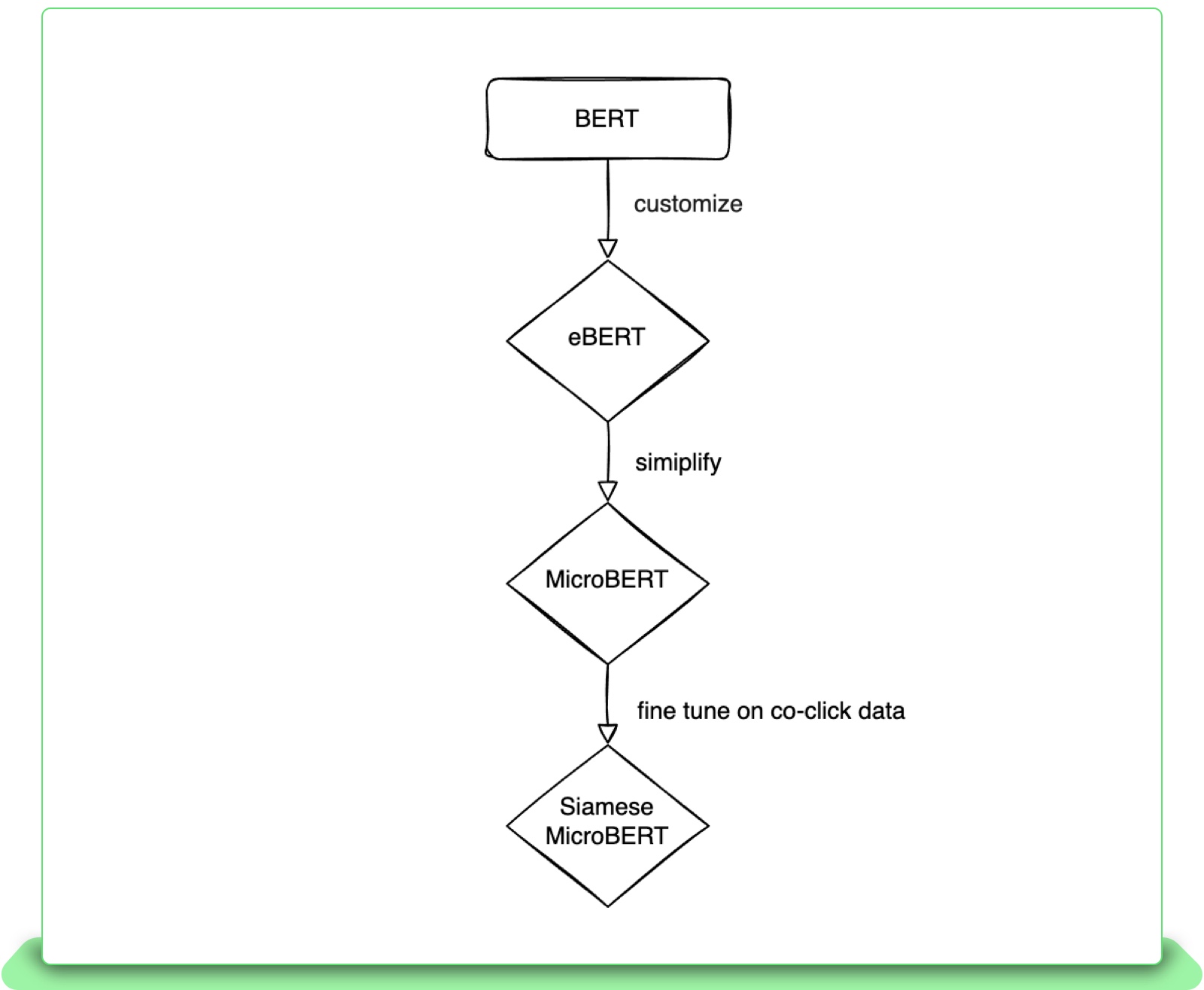
Although these out-of-the-box models achieve acceptable results, there is still room for improvement in applying BERT to language understanding tasks at eBay because our corpora is quite different from the language used in books or Wikipedia. Most significantly, eBay item titles often include product-specific words. Therefore, we introduce eBERT, a variant of BERT which has been pre-trained on eBay item titles alongside the Wikipedia corpus, that is more well-suited to the needs of eBay language understanding tasks. eBERT’s training data consists of 250 million sentences from Wikipedia and three billion eBay titles in English, German, French, Italian and Spanish. In offline evaluations, this eBERT model significantly outperforms out-of-the-box BERT models on a collection of eBay-specific tagging tasks, with a F1 score of 88.9 compared to RoBERTa’s 84.5.
Furthermore, the BERT architecture is often too heavy for applications which require high-throughput inference; in this case, the latency is too high and the model thus isn’t able to make recommendations in the allotted time. In order to address this issue, another eBay-specific model called MicroBERT has been developed as a smaller version of BERT optimized for CPU inference, similarly to MobileBERT6. At training time, the eBERT model serves as a teacher to the MicroBERT model in a process called knowledge distillation. This approach allows MicroBERT to retain 95-98% of the teacher model’s quality while decreasing inference time by 300%.
Finally, to cater to our similar item recommendation use case, we fine-tuned MicroBERT to encode item titles as embedding vectors such that the mathematical distance between these large vectors of numbers is small for similar item titles. We used a contrastive loss function called InfoNCE7, which trains the model to increase the cosine similarity of the embeddings of titles that are known to be related to each other, while decreasing the cosine similarity of all other pairings of item titles in a mini-batch. The advantage of this approach is that it only requires positive pairs of semantically related items in the training data. In our case, we defined positive pairs as items that were both clicked on following the same search query as a cheap way to construct training data via user behavior rather than manual labeling. The MicroBERT model fine-tuned on this dataset, referred to as “Siamese MicroBERT,” produces 96-dimensional title embedding vectors. While title embeddings could, in principle, also be extracted from pre-trained models directly, the fine-tuning significantly boosts the quality of the embedding vectors. The flow chart below outlines the evolution of the BERT model inferenced by our online recommendation ranker in production:
Offline Experiment Results
We leveraged the title embeddings inferenced from the Siamese MicroBERT to calculate the cosine similarity between the item title on the View Item page and the title of each recommendation item candidate. Our ranking model achieved a 3.5% improvement in purchase rank (i.e. the average rank of the sold item), and this new cosine similarity feature holds the top position in the feature gain list.
Online Inference Challenge and Solution
The complexity of the Siamese MicroBERT model makes it hard to conduct title embedding inference in real-time based on eBay’s online serving latency requirements. Thus, instead of computing the title embeddings on demand, we run a daily batch job offline to generate the title embeddings of all new items listed on eBay and cache them in NuKV, eBay’s cloud-native key-value store, with item titles as keys and title embeddings as values. The expiration of each entry in the cache is set to be the latest of expirations of the listings sharing the same title, so that the entry for a title is kept in the cache for only as long as necessary. With this approach, we are able to meet the latency requirement in retrieving the embeddings. Also as a side benefit, we greatly saved computing power by avoiding repeated computation of embeddings for the same item title.
To further reduce latency, we retrieve the title embeddings and compute the cosine similarities between title embeddings in parallel with other tasks that serve our ranking model. With that we are able to keep the overall latency at the same level as our previous model without the cosine similarity feature.
Online Experiment Results
The new ranking model significantly improves Purchases, Clicks and Ad Revenue compared to the model previously in production on Native app (iOS & Android) and Desktop web platforms.

The A/B test results validate that incorporating deep learning-based Natural Language Processing (NLP) techniques that capture semantic similarity between item attributes in our recommendation ranking model drives better conversion. See below for an online example of recommendations generated by the baseline production model vs. the enhanced model with eBERT title similarity feature for a given seed item:

Although the recommendation in the first slot is the same between the two models, the recommendations in the second and third slots indicate that eBERT detects the relative importance of “White Sox” in the title by showing Michael Jordan baseball cards as opposed to basketball cards.
Based on these improved ranking results verified by both visual inspection and positive A/B test metrics, the team is exploring other potential deep learning-based features such as item image similarity and multimodal (combined title & image) similarity.
Alex Egg, Michael Kozielski and Pavel Petrushkov also contributed to this article.
1BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2 Promoted Listing Standard (PLS) offers higher surface rates to sellers and costs an additional ad rate fee that is Cost Per Acquisition (CPA) based, which means we don’t charge ads fee until conversions happen. Ads fee is determined by ad rate that sellers set with regard to total sale amount.
3Optimizing Similar Item Recommendations in a Semi-structured Marketplace to Maximize Conversion
4Semantic Sensitive TF-IDF to Determine Word Relevance in Documents
5Using of Jaccard Coefficient for Keywords Similarity
6MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices