This topic introduces the methodology to mavenize more than 3,000 business libraries built by a legacy system. Those libraries together build up a huge dependency graph with sub-belonging dependencies. The article highlights the challenges during the migration process, including how to test the libraries in build and runtime level.
On eBay, there are a large number of site businesses, which we support across 3,000+ libraries for different business domains (e.g. buying, selling and shipping). Those libraries are still using old code structures, and owners cannot use the standard maven approach to develop and release on their own.They have to use a specific IDE to build and compile, which is cumbersome to set up. Later, they need to go through a full codebase central build process for release.This way of development is stale and given the fact that these libraries are requested to become maven native style, a strategy must be evaluated thoroughly in order for more than 3,000 libraries to be mavenized and verified.
Strategy
Mavenization is not simply generating a pom.xml. It must be able to decouple the full codebase central build into an independent project build with the same output. The legacy build system has existed for more than 20 years. It has become a monolithic system that few people have knowledge on how it works. It also requires a huge amount of extra effort to find and investigate every little difference that lies in between the two build systems in order to automate the mavenization process. Meanwhile, after manvenization, the team should address solid and practical automation designs to verify the libraries.
Based on the above, the migration process has been split into three steps.
- Mavenization
- Build verification
- Runtime verification
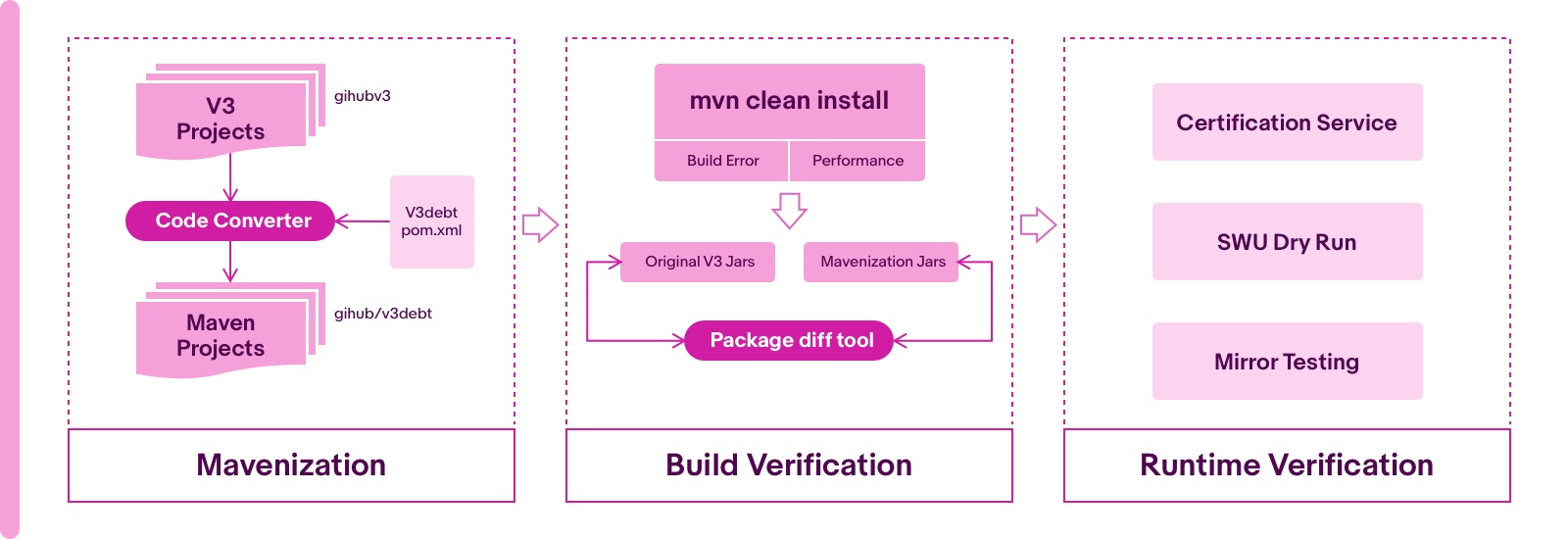
Mavenization
Considering 3,000+ libraries and repeatable conversion requests, it is not possible to carry out the mavenization process manually. A conversion tool is made by the Migration team to automate the process in which the applications turn into maven styles.The tool resolves the following crucial points.
Dependencies
The conversion tool generates a pom.xml for each library project including all the necessary dependencies. A library project contains three types of dependencies.
- Third-party libraries
- Kernel libraries (Enterprise SDK)
- Other domain libraries
Please see the diagram below.
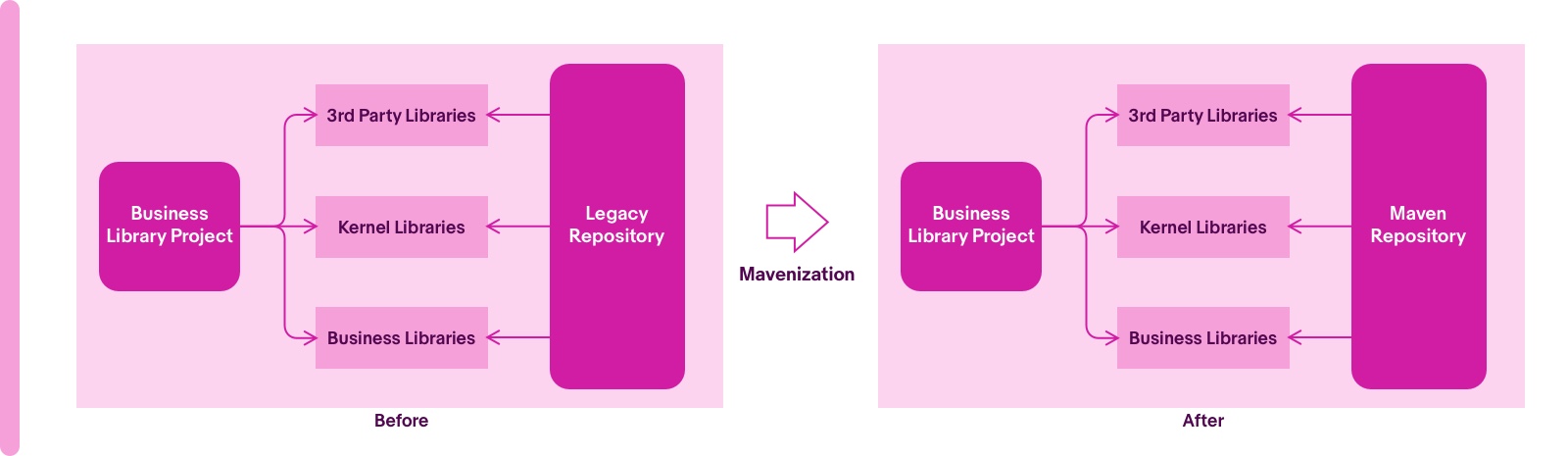
Before the mavenization, those libraries were in the repository of the legacy system. After the migration, the automation tool is desired to identify the correct mapping version in the maven repository for third-party libraries. There are multiple candidate versions in maven, and not all are backward compatible. Mapping thousands of them to correct versions by automation creates challenges.
The version selection is not only considered to have a successful build and identical functionality, but also whether the version would conflict when it is used by an application (some third-party library versions of an application are managed by a platform).
Here is the strategy to pick up versions in order to meet the criteria of platform and functionality.
- Use the version managed in the platform parent pom if it exists.
- Use the most commonly used version in maven repo if it works.
- Try a version from the version candidates until the library project can build successfully.
Based on the steps 1 and 2, most projects migrated by conversion tools could be built successfully. If there is an exception, go through step 3 to find an available version, and then the version will then be maintained by a project metadata file, which is consumed by the conversion tool. After iteratively going through the three steps, the migration team is able to determine all the third-party versions for all of the projects. Moreover, with a project metadata file, it brings the capability that if any version is not suitable by verification, the version in the metadata file can be tweaked to the right one.
As a result, version selection is automated after a couple of rounds.
Code Generation
Code generation is a common case, and there are several kinds of code generation types in the legacy build system. Many library projects have their own code generation codes. The codes normally generate stub classes from source files like xsd files. The legacy system proceeds the Ant tasks to generate, which is totally transparent and more of black box approach to application owners. Such use cases must be supported since the legacy system will no longer be used after mavenization. Afterall, a maven build could automatically generate source codes the same as before without any manual intervention. The goal requires the team to read the codes of the legacy build system to turn the black box into white box. Below is the breakdown of the solution.
Code Generation Projects
Here’s our strategy on identifying how many projects have code generation and determining what code generation approaches are used for each application.
- Identify the projects: Scan the 3,000+ libraries to compare the original source codes and built source codes. If there are incremental source codes, the project belongs to the code generation project. Repeatedly for each project, a code generation project list will be found. The result is nearly half of all the libraries.
-
Identify build logic: There are different approaches to code generation. Here are some examples used in code generation.
- Castor
- JaxB
- Saxon
- Axis
- Perl
- Plugin
Each project has respective combinations of approaches. The code generation logic is wrapped in a set of build.xmls of Ant task. The whole code generation logic could be scattered in many build.xml meaning the team desires to aggregate those into one xml and sanitize the logic.
-
- Read and understand the build logic to know where the build.xmls are from.
- Analysis the files to grab the necessary build.xmls for a given project.
- Distill the code gen snippets and aggregate them as one.
This is the key part to decouple the build logic. It is something like jigsaw puzzles in which some pictures are splitted into small mixed-up units. The team acquires patience and skill to restore them.
Code Generation Dependencies
It is not possible to run a build without necessary dependencies. The challenge to identify full dependencies is that there is no place to get the full dependencies list, even from the build.xmls, because some libraries are loaded by the legacy build system by default. The migration team must pick up the necessary libraries set for each project, which should be an input for individual project maven build.
The strategy is as follows:
- Collect the dependencies from build.xml as much as possible.
- Repeat maven build to find the missing dependencies during code generation.
- Find the right maven version for the missing dependencies following the way mentioned in the “Dependency” chapter.
Code Generation Sources
The code generation sources are another input of code generation. There are a couple of source repositories. One file change could impact multiple classes, vice versa, a code generation of a project could use multiple source files.
The team needs to elaborate the relationship by the following:
- Collect the source repo from build.xml.
- Retrieve the source files used in build.xml.
After the relationship is carded, the code generation no longer is mysterious and a final solution can be proposed.
Solution
Based on the result of the above three steps, the automation of code generation is able to run at project level. The team offers a maven ant plugin to perform code generation logic.
The plugin can configure source files and dependencies as an input and a build.xml as a build script. The details are as follows:
- To facilitate the source files changes and management, the source repositories would be packaged as a maven artifact to have version management. The plugin would read source files from source artifacts.
- It can specify the dependent libraries in the plugin dependencies section.
- The plugin could run the ant task to invoke code generation logic with build.xml during the maven build.
Here is the diagram of the maven plugin.
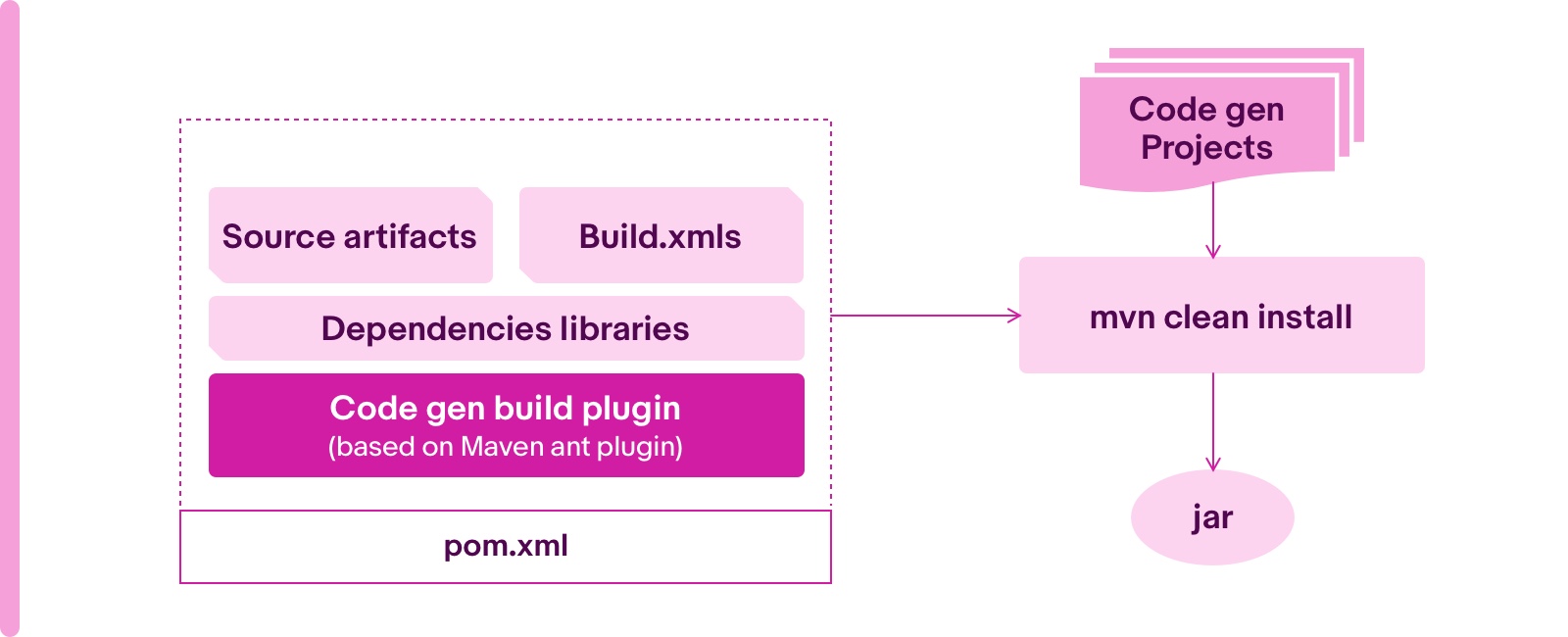
With integration of the plugin, the maven build is able to automatically generate the codes. The customers can test code generation logic locally and fix it immediately instead of going with a process to perform a central build to save time.
Build Verification
After mavenization, the library should not only be verified with a successful maven build but also verified with an output as identical as before. The aspects are essential to be verified.
- Dependency: Make sure all the dependencies have the right version and are not missing any necessary dependencies.
- JDK backward compatibility: The old source codes are compiled by JDK6, while the new source codes are requested to be compiled by at least JDK8. From JDK6 to JDK8, some incompatible changes are noted, meaning the team has to do some code level tuning to adapt to the difference of a JDK upgrade.
- Performance: The mavenization build should be fast and efficient. The project which has a large volume of dependencies needs to be specially cared for to make them can be built within minutes and memory cost is reasonable.
- Output: The output should be identical. It is the key step for the code generation projects to verify whether the code generation logic is correct or not.
The team sets up a CI to continuously verify for all the library projects according to the four problematic aspects, and then keeps fixing the problem from the CI running report until all the issues are resolved.
Dependency Missing
The missing dependency is caused by the legacy project dependency metadata not being full. The legacy system has some default dependencies, which allow the project to define less dependencies. A CI is responsible to detect 3,000+ library projects to automatically proceed build and send out the build report. With the report, the team is able to configure the missing dependency with the correct version in the metadata file of the conversion tool. Therefore, the conversion tool could deliver a well-formed dependency for this project next time.
JDK Incompatible
For the JDK incompatible cases, there is no choice but to rewrite the code to meet the new JDK compiler. The cases are not too many, but the challenge is still there. The code is the customer’s business logic code, however most of them do not have the clear ownership. The team must take the responsibility to rewrite it. Since the team is not the original code owner, how can the team make sure there is no impact for dependent libraries for code changes? Here all the JDK compile failures are categorized into two types:
The two kinds of problems are all associated with Generic type but do not impact the method name. Here is the solution.
- For case one, change the Generic type to a proper base type in the code.
- For case two, split one into multiple overload methods.
After testing, those fixes can work out as before. Those rewritten files are kept in a dedicated git repository and the conversion tool will replace the incompatible files with the rewritten files. It means at the next round, after the tool converts the one project, the JDK incompatible problem is resolved.
Performance
During the maven build, two special cases are found for performance issues.
Circular dependencies
During a build time data analysis, some project build time can be abnormal compared to the others which have a similar amount of dependencies. The team needs to investigate the root cause. The challenge is that there is no clue to show why and how that build is successful as well. The migration team sets logs inside the maven library and then compares the normal and abnormal logs. Finally, the team finds the time costs in handling circular dependency chains. If libraries have circular maven dependencies, it would greatly increase the build time. Consequently, the team developed a dependency analyzer tool to build all the libraries as a dependency graph to detect circular dependency. As a result, two circles are found and must be broken apart. Thus, PRs were fired to break the circular dependency. This change reduces build time significantly, e.g. one project build from about 20minitues to three minutes.
GC Overhead
After the circular dependency problem is fixed, few library projects still cannot be built successfully with OutOfMemory error messages. If the maven memory setting increases to 6G, the build could be successful although it is not acceptable. Here is a sample file of a project.

From the file, the dependency instances created are 3,174,700, while the dependency number of the failure project is only about 1,000+. Where do those large numbers of instances come from? After our team investigated, one was highlighted. The instance number needed to be split into 3,000,000= 3,000* 1,000. The 1,000 is about the project dependency count, and the 3,000 is about all the library’s count. Is it possible that this is the relationship hidden in the numbers?
At that time, all the projects had shared a parent pom which contained all of the libraries to manage the version. The shared parent pom was suspected to cause the problem. For confirmation, the team rebuilt a parent pom and removed 600 libraries from it. Theoretically, the number should be 2,400*1,000= 2,400,000. By doing the maven build again and dumping the file, the number is exactly matched.
After debugging the maven logic, the root cause is that each artifact would duplicately load the artifacts of parent pom during maven pom analysis. The failure project has 1,000+ library dependencies and the parent pom has 3,000+ management artifacts. So the instance number was 3,000* 1,000 = 3 million. Three million-plus instances will occupy a huge memory, and most of them are duplicated. The fixing strategy is directly specifying the version in the library project pom file instead of a shared parent pom. After that fix, the memory cost of the problematic project is back to about 900 million.
Build Output
After the build is successful, the next part is to ensure the build output is the same as before. Based on the same codes, the mavenized project will process a build and compare the build output with the one from the legacy system. It should be an apple-to-apple comparison to measure any build logic problem. It is the key for code generation to verify whether the code generation works correctly or not. The tool “package diff” can automatically compare files for verification after configuring the noise patterns like timestamp and .git folder.
Runtime Verification
Library verification is not able to test the runtime behavior. It needs to test applications which apply the new libraries to verify on the fly. Here addresses the strategy to verify the libraries.
- Goal: Define the metrics to be verified.
- Scope: Pick up the applications with criteria.
- Approach: Methodology to verify.
Goal
When an application has some changes, there is always a desire to evaluate whether it is healthy or not. The migration team defines two measurement aspects.
-
Functional features: A functional features test is targeted to make sure the behaviors are the same as before for a project with the new libraries. Some cases are not able to be detected during build, but only during runtime, like the following exceptional cases.
- Deprecated libraries found
- Transactive libraries missing
- Class conflict
These problems would impact two scenarios
-
Non Functional features: Besides the functionality, the non-functional features are monitored as well to guarantee the application works for a long time without the exceptions like the following cases
- Memory leak
- High CPU usage
- Long transaction time
Scope
Not all the applications should be verified. The team defines the criteria to pick up the applications. The criteria of application for tests are:
- Cover different application types, e.g. web, batch, messaging, service
- Contain the most migration libraries
- Have measurable traffic
After scanning, 400 applications meet the criteria.
The team does not make test wheels by itself. The strategy is trying to find existing infrastructures and integrate with them. Currently there are verification infrastractures for platform upgrades.
- Seventeen certification applications to run well-prepared integration tests.
- Dry run mechanism to verify 1,500 applications deployment and server startup.
Here is the testing scope after considering to reuse the existing infrastructure
- Totally reuse 17 certification applications for integration tests.
- Dry run 400 applications (in scope) for server startup tests.
- Pick up 12 applications for functional and non-functional tests. The applications convert web, batch, messaging and services, and have the most number of shared libraries. Each type of application contains three applications.
Approach
The first two will not be introduced since they are already sophisticated ways. Here we focus on step three.
Regarding functional and non-functional tests, the most challenging is how to accomplish them. Use a service application as an example, an application is a pure black box. The team does not know the business logic and does not know the input combination and response formats as well. It is not possible to have a common white-box test approach for all the projects. Therefore, the team leverages the black-box the test facilities which are widely used in eBay key projects.
The idea is called the mirror test. The concept is, for the same input, the output should be the same for the old and new code.
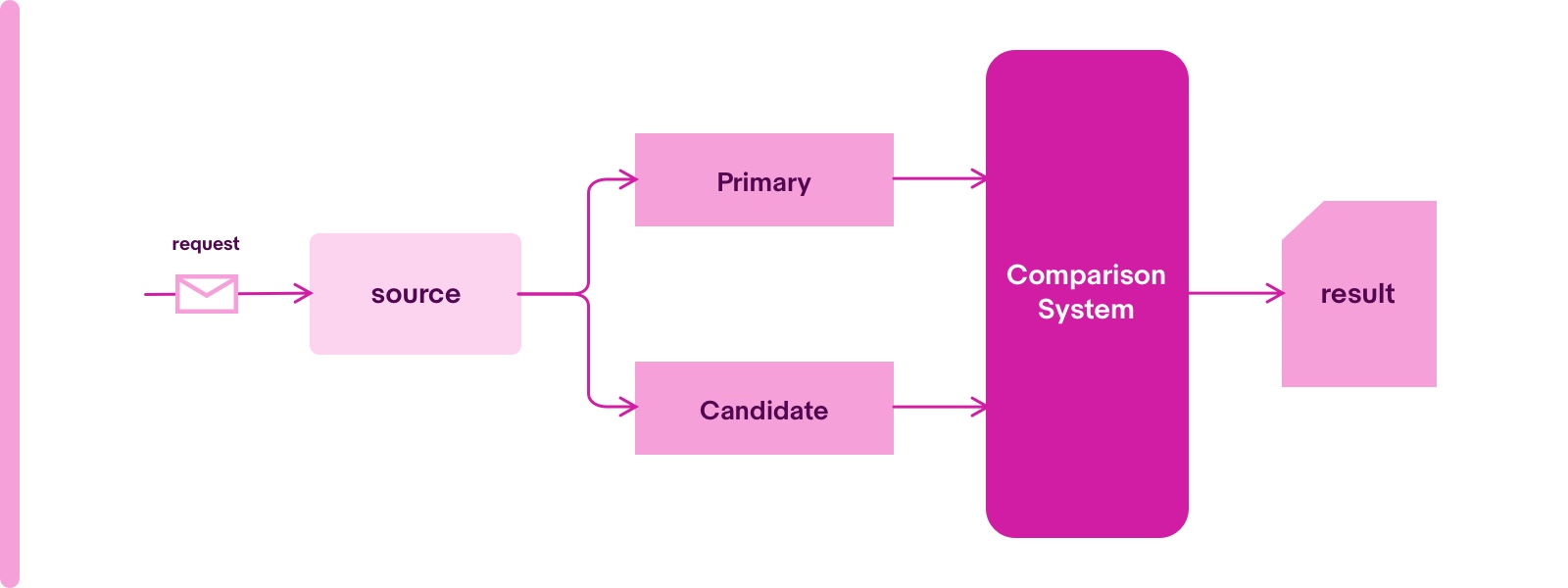
There are different strategies for different application types.
- Service Application: A http request is dispatched from the source to primary (old) and candidate (new) application, then two responses are compared by comparison system.
- Messaging Application: The same event is dispatched to primary and candidate applications. The running result can be compared.
- Batch Application: The same dummy job (empty logic) to run in primary and candidate applications. The exit code and exceptions and duration can be compared.
After the team finishes the three layer tests, it brings confidence that the shared libraries could have the same functionality to replace the previous ones.
Summary
Mavenization of legacy domain business libraries provides a standardized maven development experience, meaning developers can build, develop and even patch on their own in a short time. It is a brand new methodology to proceed with the library mavenization.
Besides creating different kinds of tools to facilitate the automation, the team also has created processes with detailed steps to follow in order to ensure the quality during migration. The team is able to go deep further to investigate the unprecedented challenges and break them down into actionable items to tackle step by step.