The generative AI revolution is transforming the way that teams work, and Databricks Assistant leverages the best of these advancements. It allows you to query data through a conversational interface, making you more productive inside your Databricks Workspace. The Assistant is powered by DatabricksIQ, the Data Intelligence Engine for Databricks, helping to ensure your data is secured and responses are accurate and tailored to the specifics of your enterprise. Databricks Assistant lets you describe your task in natural language to generate, optimize, or debug complex code without interrupting your developer experience.
In this post, we expand on blog 5 tips to get the most out of your Databricks Assistant and focus on how the Assistant can improve the life of Data Engineers by eliminating tedium, increasing productivity and immersion, and accelerating time to value. We will follow up with a series of posts focused on different data practitioner personas, so stay tuned for upcoming entries focused on data scientists, SQL analysts, and more.
Ingestion
When working with Databricks as a data engineer, ingesting data into Delta Lake tables is often the first step. Let’s take a look at two examples of how the Assistant helps load data, one from APIs, and one from files in cloud storage. For each, we will share the prompt and results. As mentioned in the 5 tips blog, being specific in a prompt gives the best results, a technique consistently used in this article.
To get data from the datausa.io API and load it into a Delta Lake table with Python, we used the following prompt:
Help me ingest data from this API into a Delta Lake table: https://datausa.io/api/data?drilldowns=Nation&measures=Population
Make sure to use PySpark, and be concise! If the Spark DataFrame columns have any spaces in them, make sure to remove them from the Spark DF.
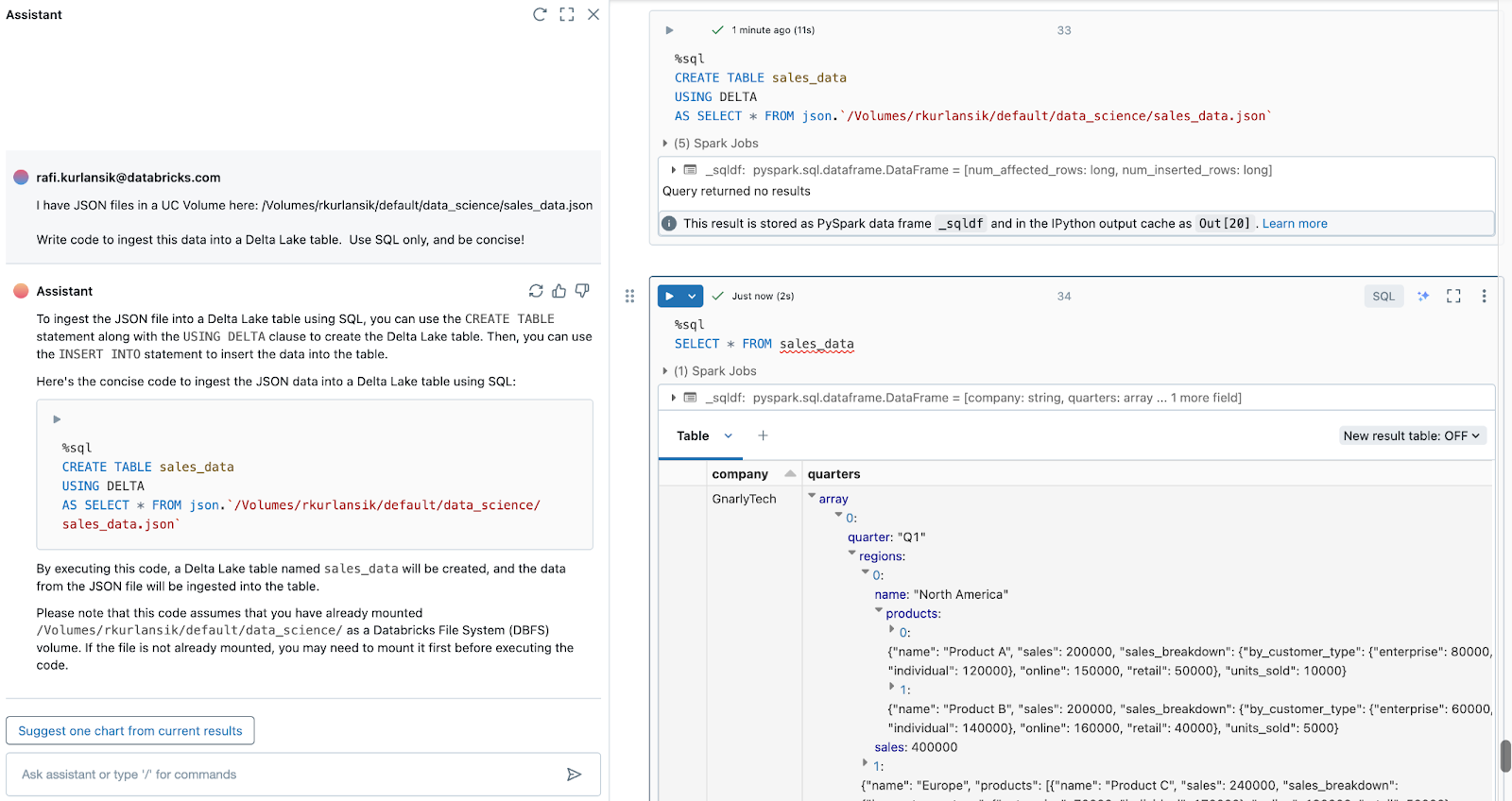
A similar prompt can be used to ingest JSON files from cloud storage into Delta Lake tables, this time using SQL:
I have JSON files in a UC Volume here: /Volumes/rkurlansik/default/data_science/sales_data.json
Write code to ingest this data into a Delta Lake table. Use SQL only, and be concise!
Transforming data from unstructured to structured
Following tidy data principles, any given cell of a table should contain a single observation with a proper data type. Complex strings or nested data structures are often at odds with this principle, and as a result, data engineering work consists of extracting structured data from unstructured data. Let’s explore two examples where the Assistant excels at this task – using regular expressions and exploding nested data structures.
Regular expressions
Regular expressions are a means to extract structured data from messy strings, but figuring out the correct regex takes time and is tedious. In this respect, the Assistant is a boon for all data engineers who struggle with regex.
Consider this example using the Title column from the IMDb dataset:

This column contains two distinct observations – film title and release year. With the following prompt, the Assistant identifies an appropriate regular expression to parse the string into multiple columns.
Here is an example of the Title column in our dataset: 1. The Shawshank Redemption (1994). The title name will be between the number and the parentheses, and the release date is between parentheses. Write a function that extracts both the release date and the title name from the Title column in the imdb_raw DataFrame.
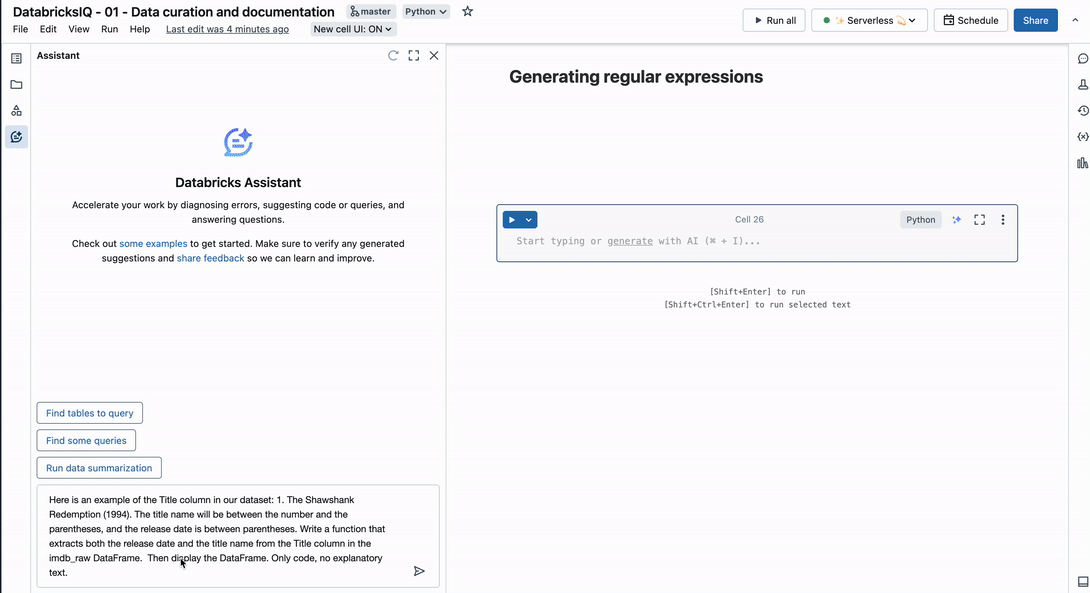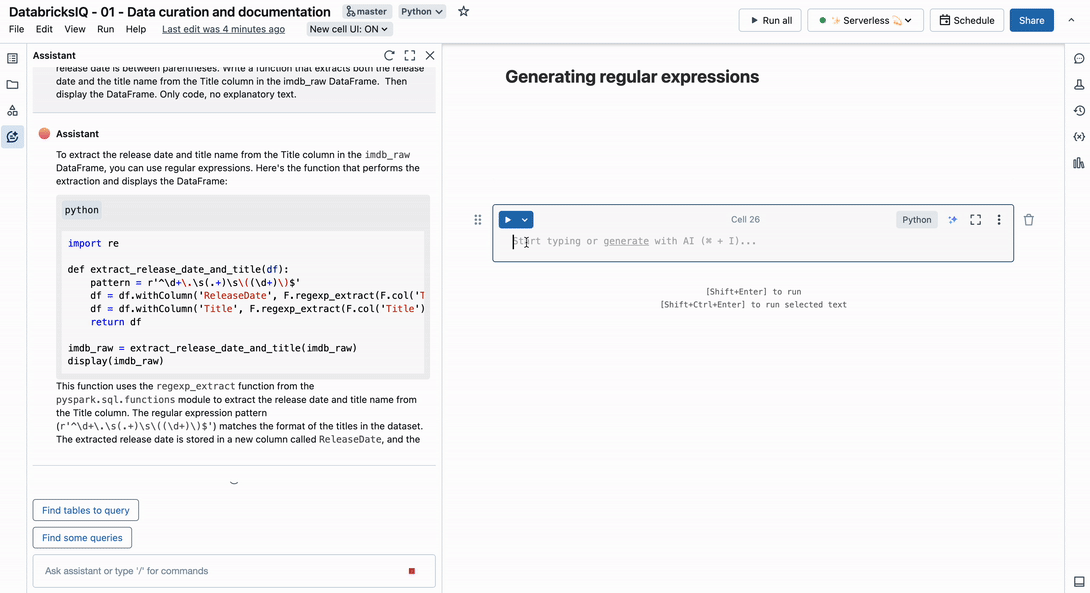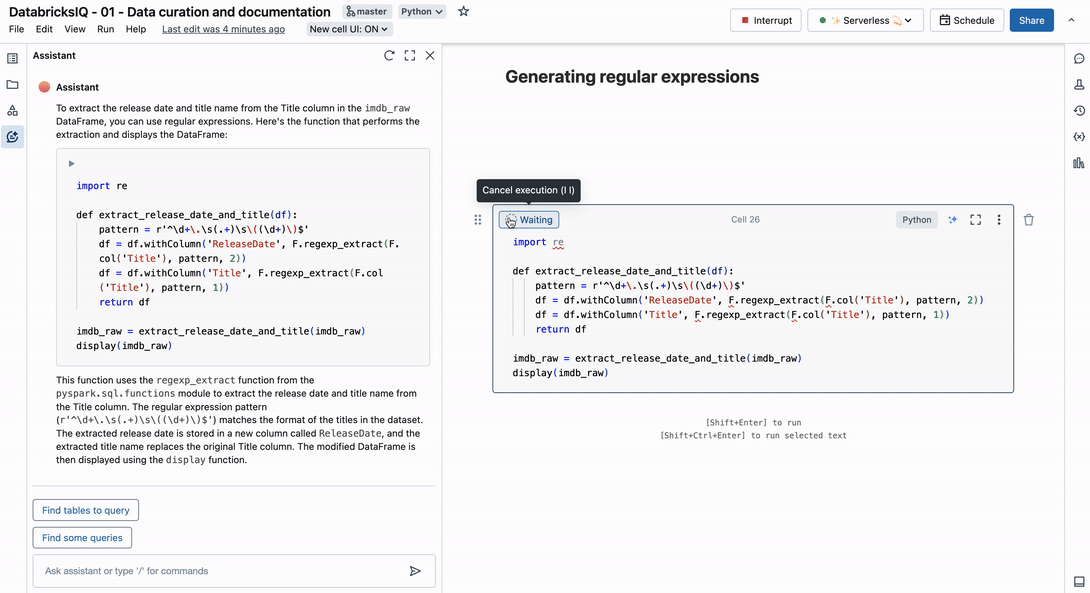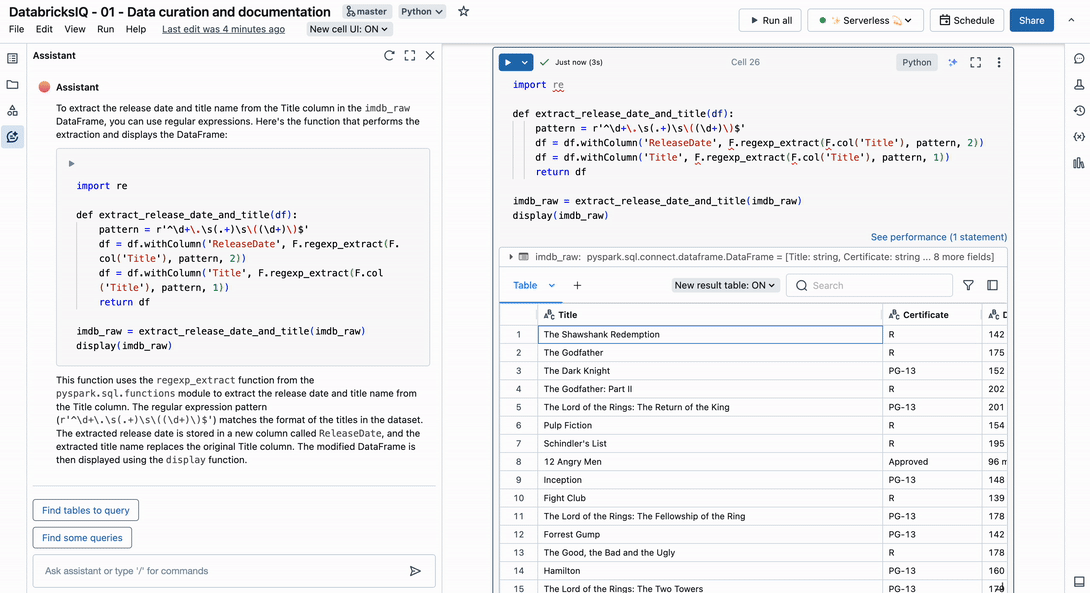
Providing an example of the string in our prompt helps the Assistant find the correct result. If you are working with sensitive data, we recommend creating a fake example that follows the same pattern. In any case, now you have one less problem to worry about in your data engineering work.
Nested Structs, Arrays (JSON, XML, etc)
When ingesting data via API, JSON files in storage, or noSQL databases, the resulting Spark DataFrames can be deeply nested and tricky to flatten correctly. Take a look at this mock sales data in JSON format:
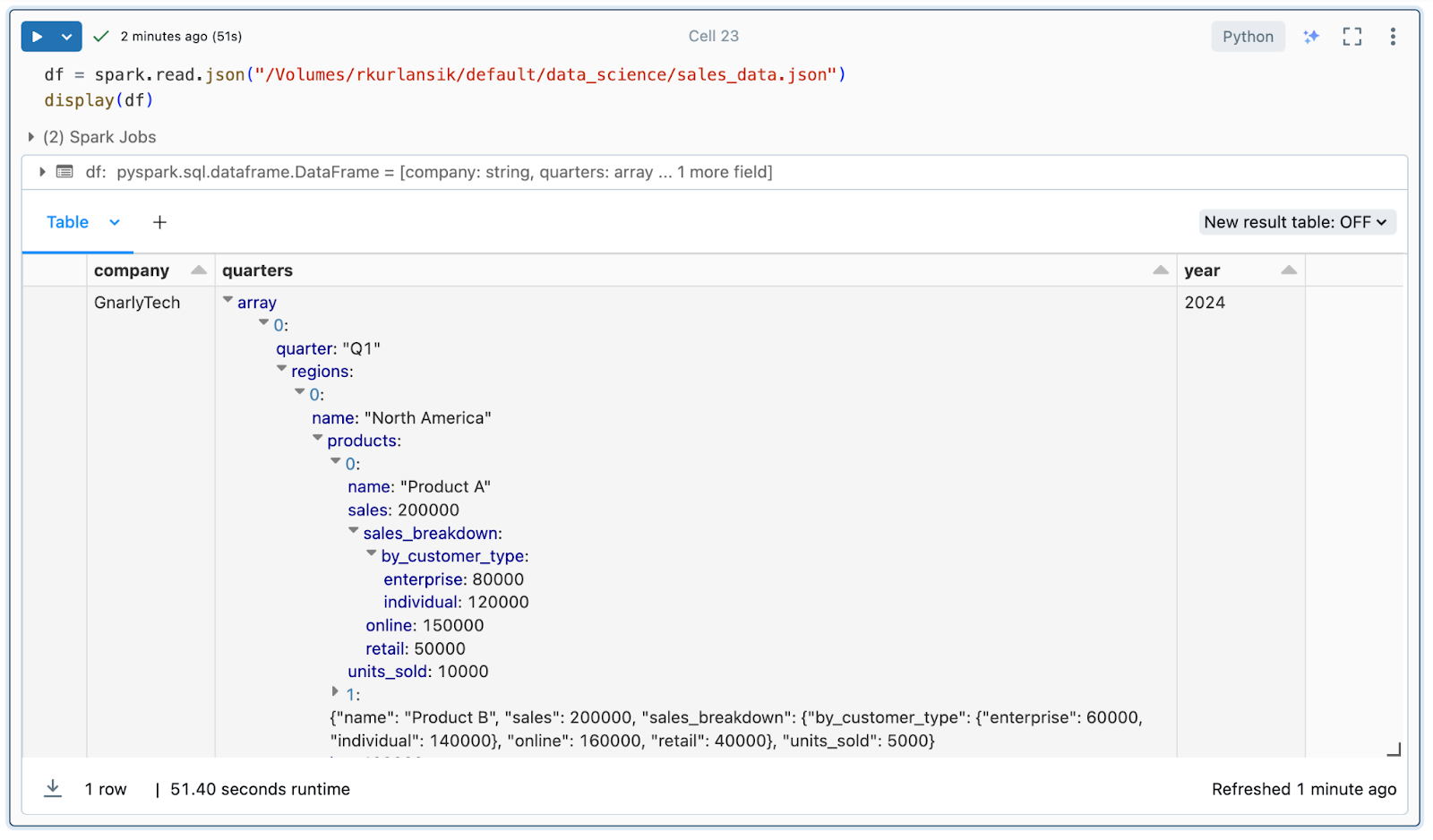
Data engineers may be asked to flatten the nested array and extract revenue metrics for each product. Normally this task would take significant trial and error – even in a case where the data is relatively straightforward. The Assistant, however, being context-aware of the schemas of DataFrames you have in memory, generates code to get the job done. Using a simple prompt, we get the results we are looking for in seconds.
Write PySpark code to flatten the df and extract revenue for each product and customer

Refactoring, debugging and optimization
Another scenario data engineers face is rewriting code authored by other team members, either ones that may be more junior or have left the company. In these cases, the Assistant can analyze and explain poorly written code by understanding its context and intent. It can suggest more efficient algorithms, refactor code for better readability, and add comments.
Improving documentation and maintainability
This Python code calculates the total cost of items in an online shopping cart.
def calculate_total(cart_items):
total = 0
for i in range(len(cart_items)):
if cart_items[i]['type'] == 'book':
discount = cart_items[i]['price'] * 0.05
total += cart_items[i]['price'] - discount
else:
total += cart_items[i]['price']
return total
cart_items = [{'name': 'Python Programming', 'type': 'book', 'price': 50},
{'name': 'Laptop', 'type': 'electronics', 'price': 800}]
total_price = calculate_total(cart_items)The use of conditional blocks in this code makes it hard to read and inefficient at scale. Furthermore, there are no comments to explain what is happening. A good place to begin is to ask the Assistant to explain the code step by step. Once the data engineer understands the code, the Assistant can transform it, making it more performant and readable with the following prompt:
Rewrite this code in a way that is more performant, commented properly, and documented according to Python function documentation standards
The generated example below properly documents the code, and uses generator expressions instead of conditional blocks to improve memory utilization on larger datasets.
def calculate_total(cart_items):
"""
Calculate the total price of items in the shopping cart.
Apply a 5% discount to book items. The total is calculated by summing
the prices, taking into account the discount for books.
Parameters:
cart_items (list of dict): A list of dictionaries, where each dictionary
represents an item in the cart with keys 'name',
'type', and 'price'.
Returns:
float: The total price of all items in the cart after discounts.
"""
# Use a generator expression to iterate over cart items, applying a 5% discount to books.
return sum(item['price'] * 0.95 if item['type'] == 'book' else item['price'] for item in cart_items)
# Example usage
cart_items = [{'name': 'Python Programming', 'type': 'book', 'price': 50},
{'name': 'Laptop', 'type': 'electronics', 'price': 800}]
total_price = calculate_total(cart_items)Diagnosing errors
Inevitably, data engineers will need to debug. The Assistant eliminates the need to open multiple browser tabs or switch contexts in order to identify the cause of errors in code, and staying focused is a tremendous productivity boost. To understand how this works with the Assistant, let’s create a simple PySpark DataFrame and trigger an error.
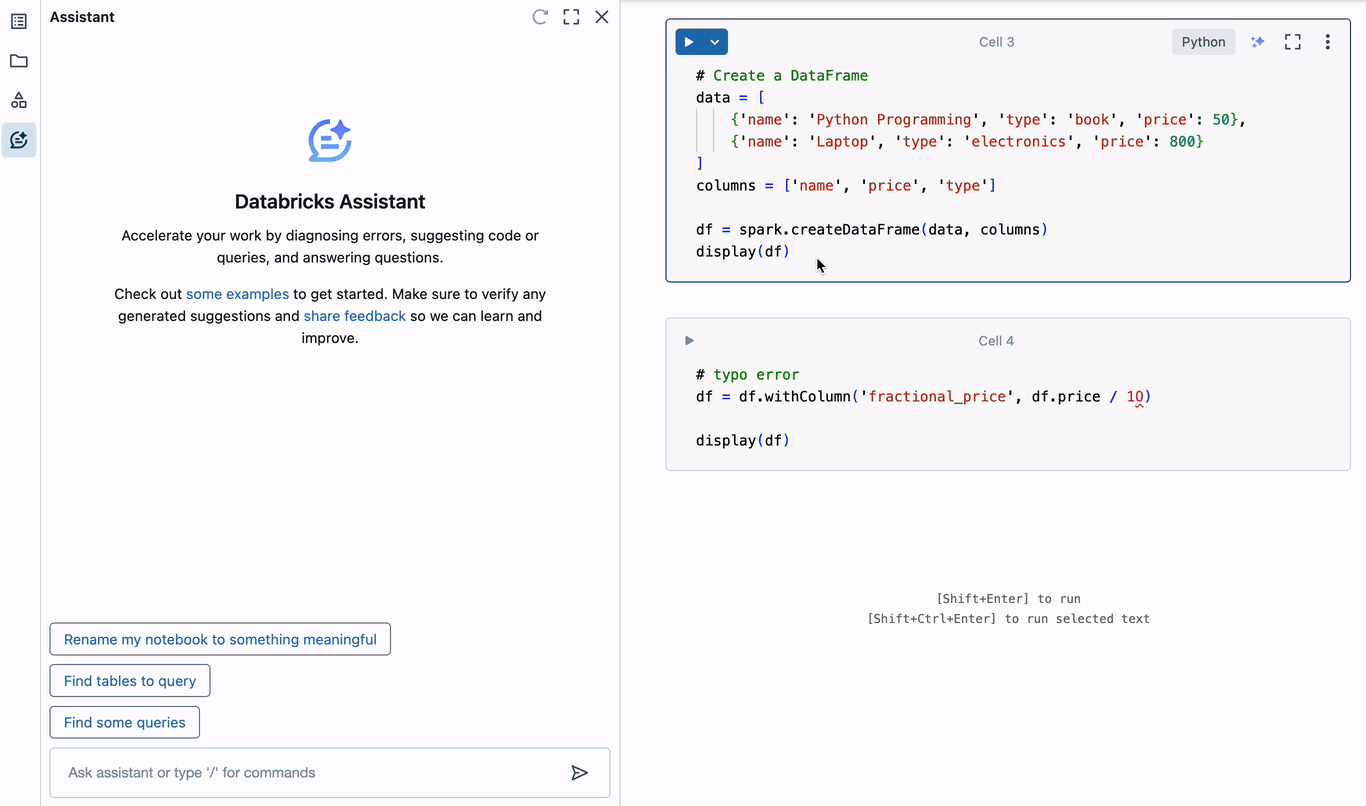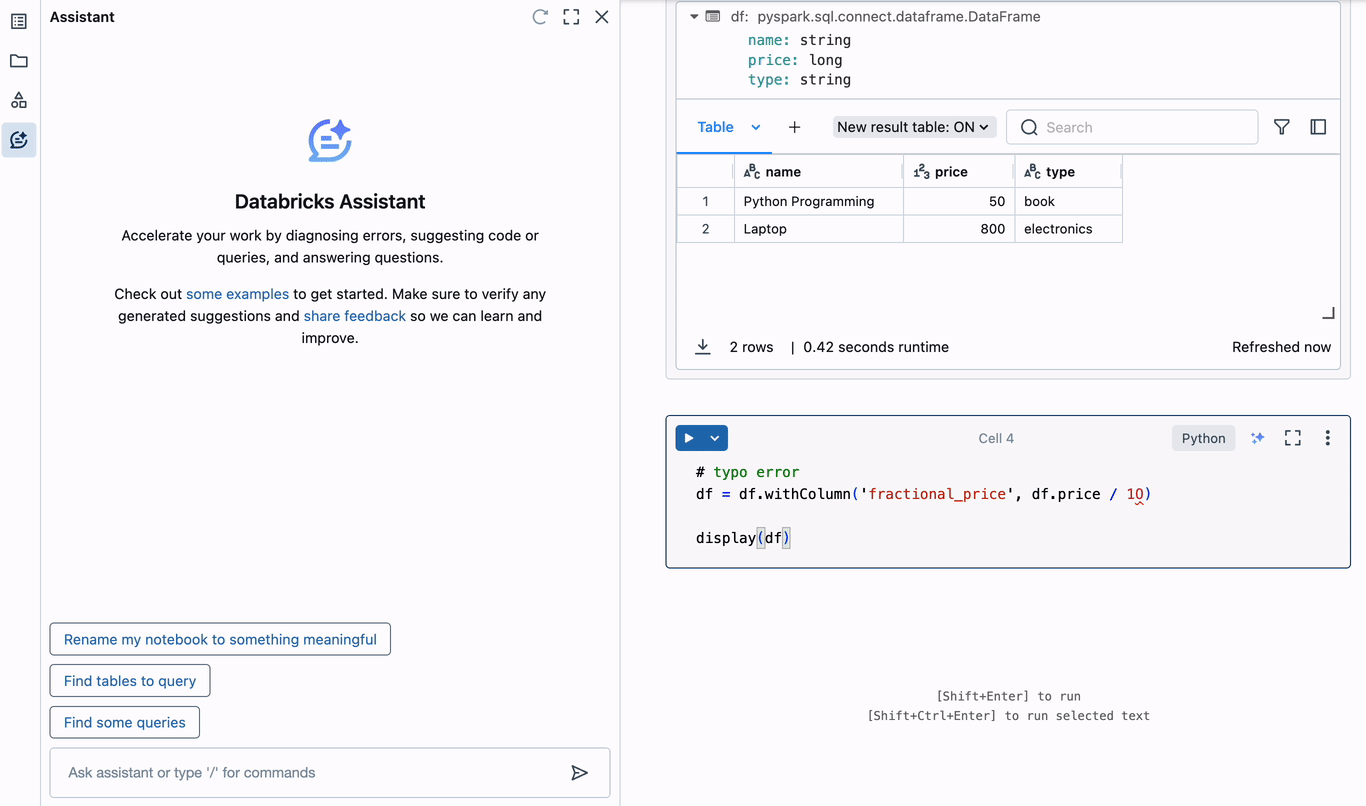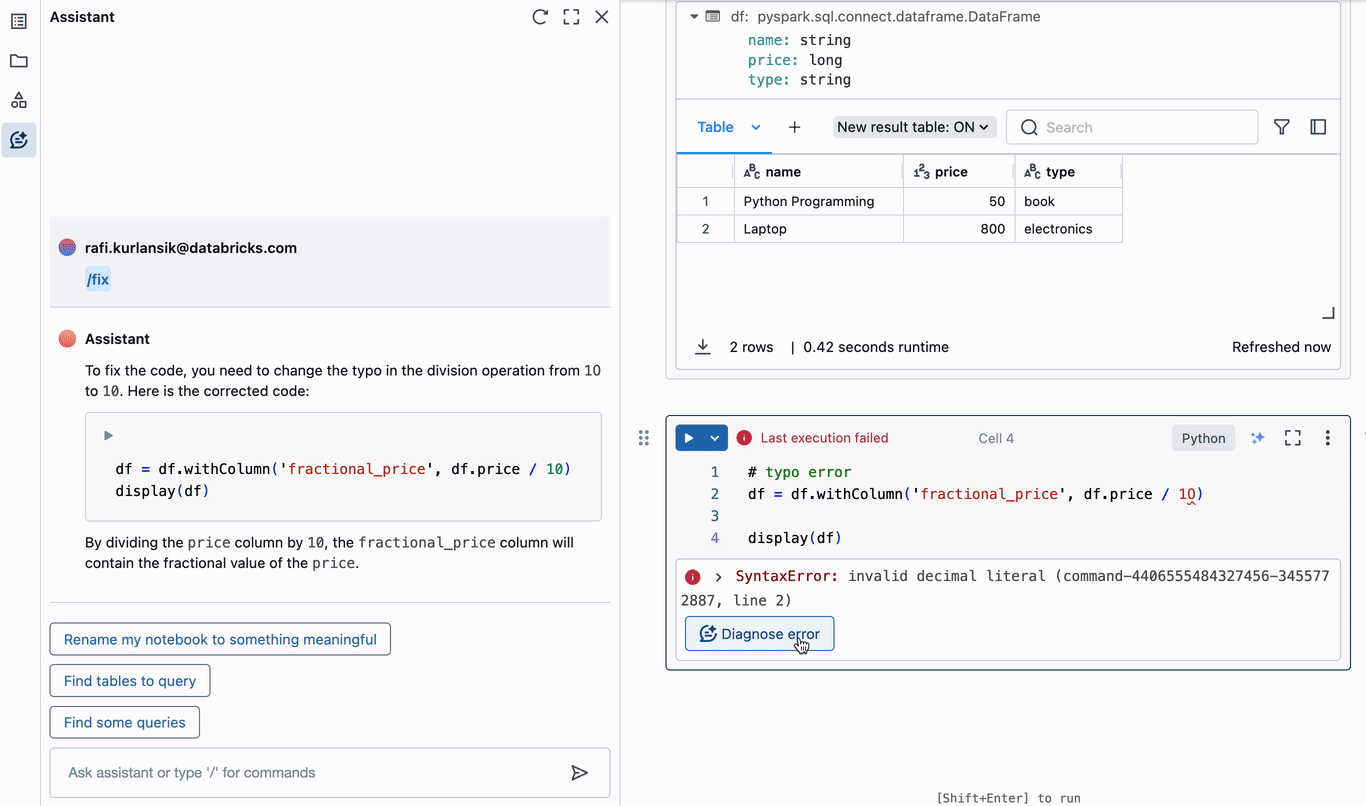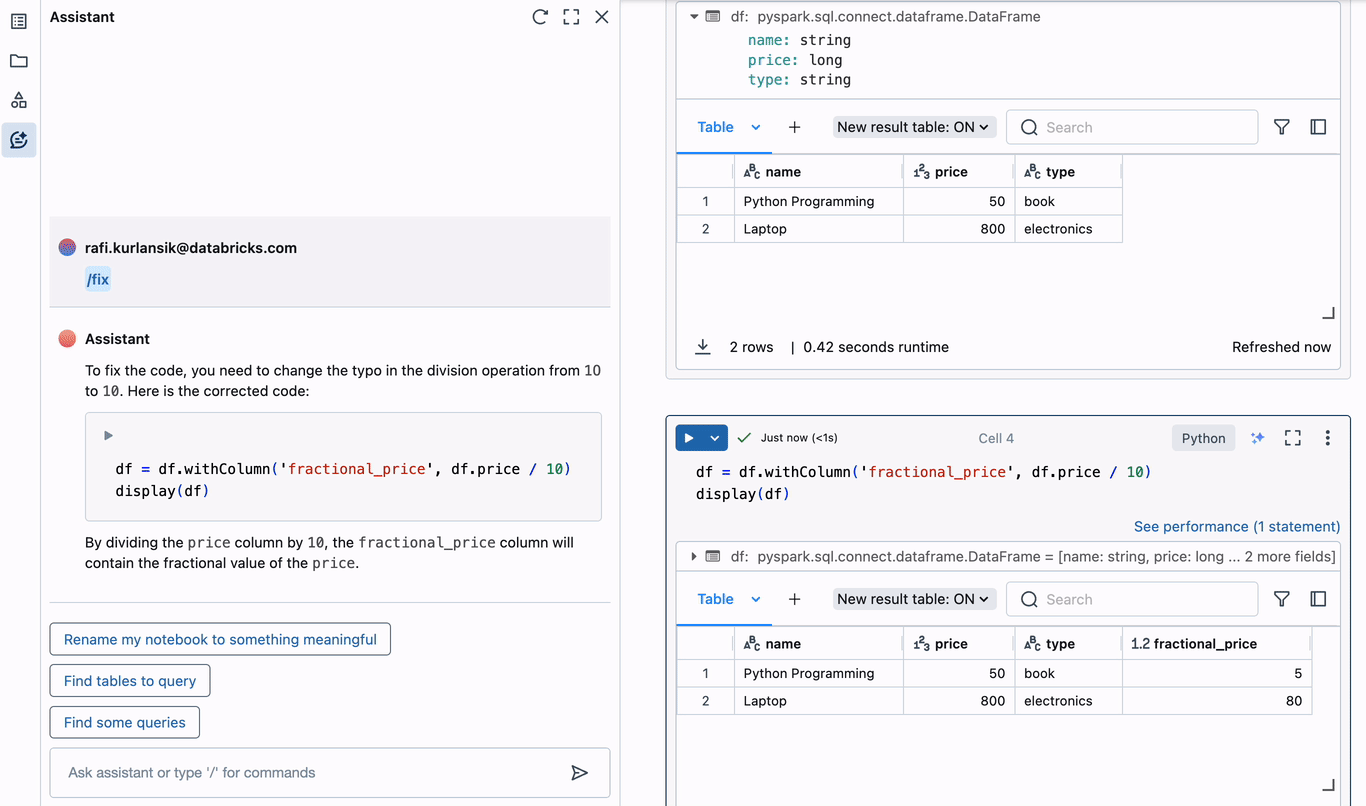
In the above example, a typo is introduced when adding a new column to the DataFrame. The zero in “10” is actually the letter “O”, leading to an invalid decimal literal syntax error. The Assistant immediately offers to diagnose the error. It correctly identifies the typo, and suggests corrected code that can be inserted into the editor in the current cell. Diagnosing and correcting errors this way can save hours of time spent debugging.
Transpiling pandas to PySpark
Pandas is one of the most successful data-wrangling libraries in Python and is used by data scientists everywhere. Sticking with our JSON sales data, let’s imagine a situation where a novice data scientist has done their best to flatten the data using pandas. It isn’t pretty, it doesn’t follow best practices, but it produces the correct output:
import pandas as pd
import json
with open("/Volumes/rkurlansik/default/data_science/sales_data.json") as file:
data = json.load(file)
# Bad practice: Manually initializing an empty DataFrame and using a deeply nested for-loop to populate it.
df = pd.DataFrame(columns=['company', 'year', 'quarter', 'region_name', 'product_name', 'units_sold', 'product_sales'])
for quarter in data['quarters']:
for region in quarter['regions']:
for product in region['products']:
df = df.append({
'company': data['company'],
'year': data['year'],
'quarter': quarter['quarter'],
'region_name': region['name'],
'product_name': product['name'],
'units_sold': product['units_sold'],
'product_sales': product['sales']
}, ignore_index=True)
# Inefficient conversion of columns after data has been appended
df['year'] = df['year'].astype(int)
df['units_sold'] = df['units_sold'].astype(int)
df['product_sales'] = df['product_sales'].astype(int)
# Mixing access styles and modifying the dataframe in-place in an inconsistent manner
df['company'] = df.company.apply(lambda x: x.upper())
df['product_name'] = df['product_name'].str.upper()By default, Pandas is limited to running on a single machine. The data engineer shouldn’t put this code into production and run it on billions of rows of data until it is converted to PySpark. This conversion process includes ensuring the data engineer understands the code and rewrites it in a way that is maintainable, testable, and performant. The Assistant once again comes up with a better solution in seconds.
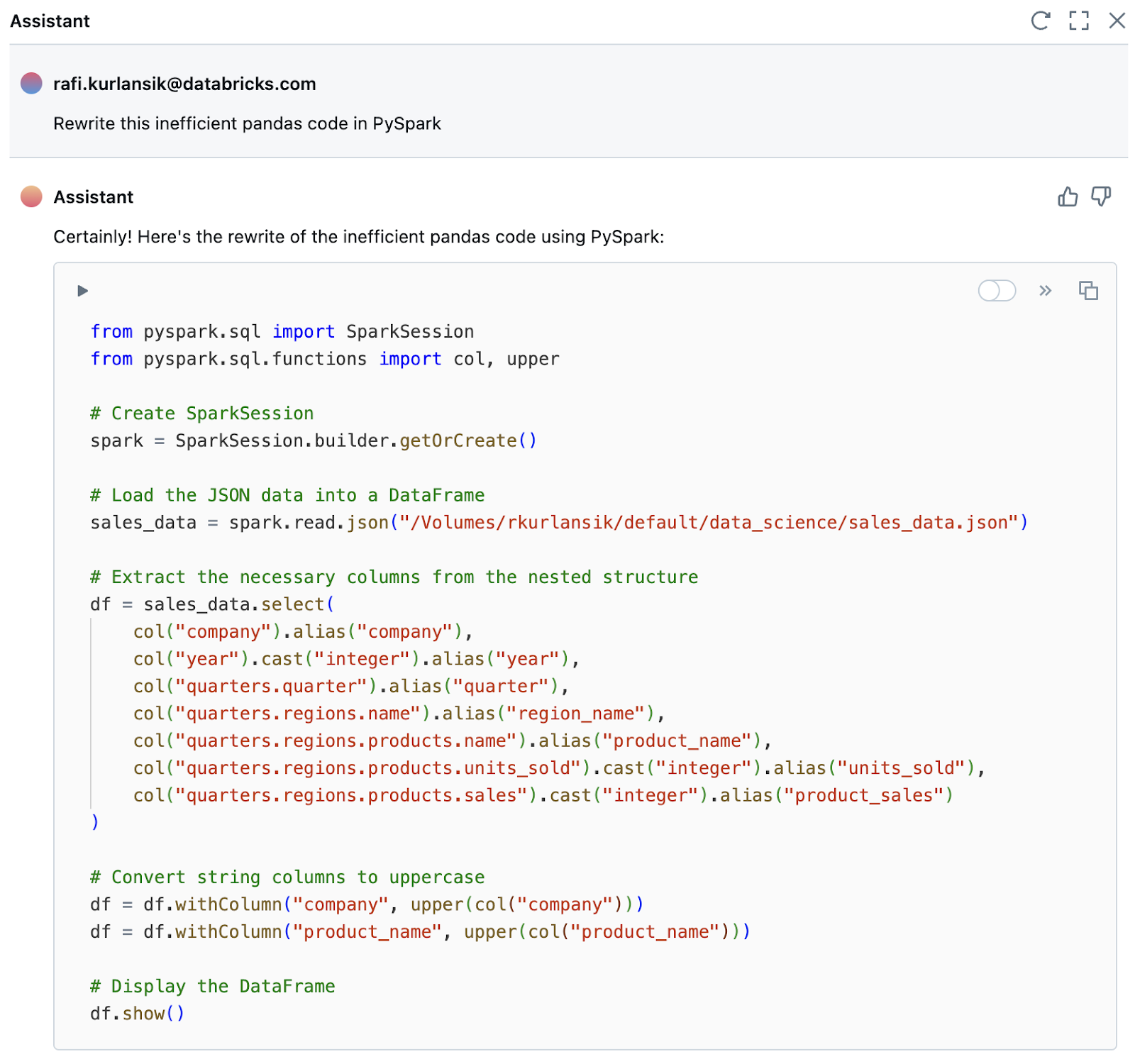
Note the generated code includes creating a SparkSession, which isn’t required in Databricks. Sometimes the Assistant, like any LLM, can be wrong or hallucinate. You, the data engineer, are the ultimate author of your code and it is important to review and understand any code generated before proceeding to the next task. If you notice this type of behavior, adjust your prompt accordingly.
Writing tests
One of the most important steps in data engineering is to write tests to ensure your DataFrame transformation logic is correct, and to potentially catch any corrupted data flowing through your pipeline. Continuing with our example from the JSON sales data, the Assistant makes it a breeze to test if any of the revenue columns are negative – as long as values in the revenue columns are not less than zero, we can be confident that our data and transformations in this case are correct.

Write a test using assertDataFrameEqual from pyspark.testing.utils to check that an empty DataFrame has the same number of rows as our negative revenue DataFrame.
The Assistant obliges, providing working code to bootstrap our testing efforts.
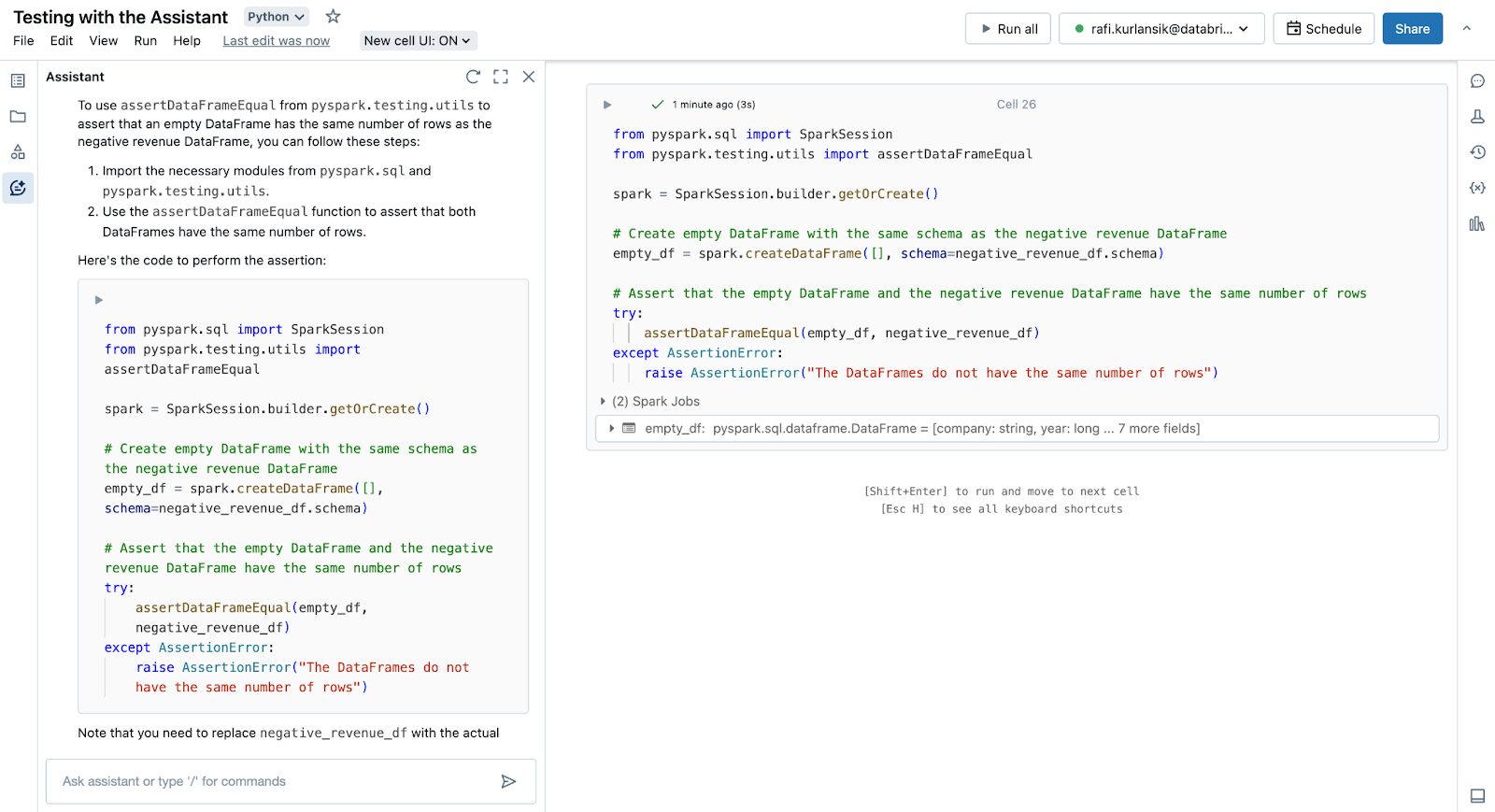
This example highlights the fact that being specific and adding detail to your prompt yields better results. If we simply ask the Assistant to write tests for us without any detail, our results will exhibit more variability in quality. Being specific and clear in what we are looking for – a test using PySpark modules that builds off the logic it wrote – generally will perform better than assuming the Assistant can correctly guess at our intentions.
Getting help
Beyond a general capability to improve and understand code, the Assistant possesses knowledge of the entire Databricks documentation and Knowledge Base. This information is indexed on a regular basis and made available as additional context for the Assistant via a RAG architecture. This allows users to search for product functionality and configurations without leaving the Databricks Platform.
For example, if you want to know details about the system environment for the version of Databricks Runtime you are using, the Assistant can direct you to the appropriate page in the Databricks documentation.
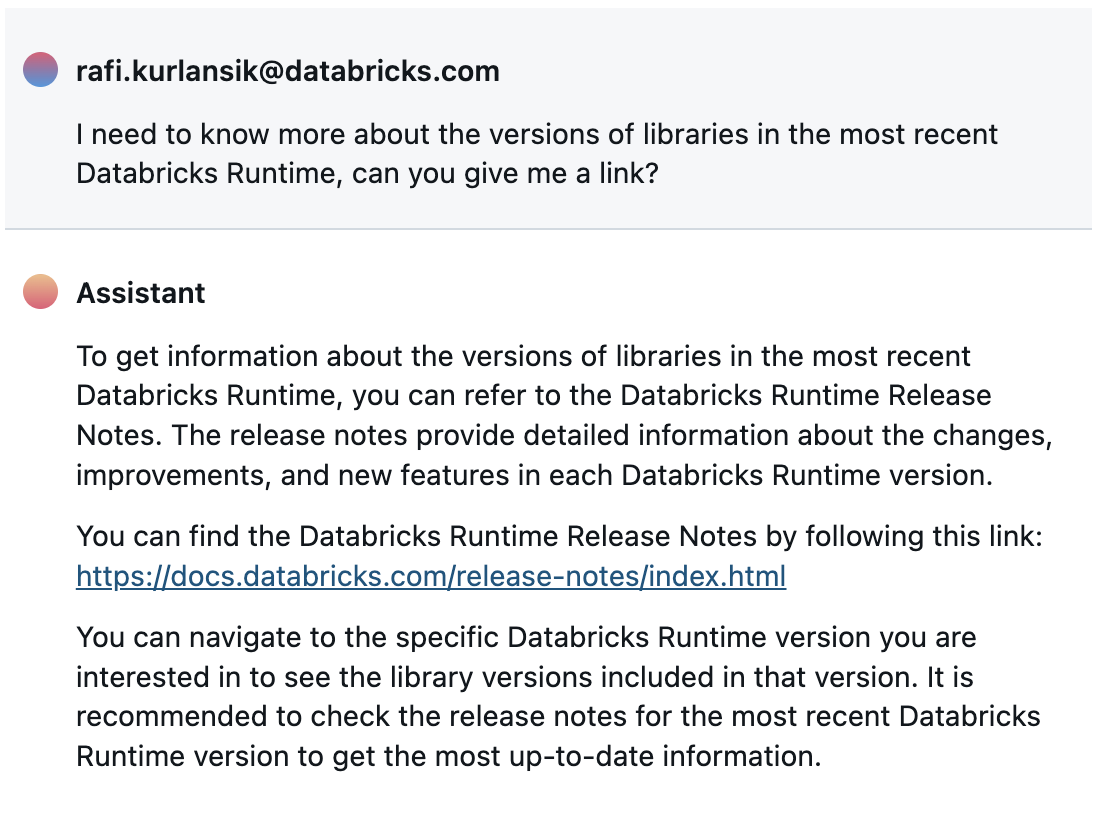
The Assistant can handle simple, descriptive, and conversational questions, enhancing the user experience in navigating Databricks’ features and resolving issues. It can even help guide users in filing support tickets! For more details, read the announcement article.
Conclusion
The barrier to entry for quality data engineering has been lowered thanks to the power of generative AI with the Databricks Assistant. Whether you are a newcomer looking for help on how to work with complex data structures or a seasoned veteran who wants regular expressions written for them, the Assistant will improve your quality of life. Its core competency of understanding, generating, and documenting code boosts productivity for data engineers of all skill levels. To learn more, see the Databricks documentation on how to get started with the Databricks Assistant today, and check out our recent blog 5 tips to get the most out of your Databricks Assistant. You can also watch this video to see Databricks Assistant in action.


