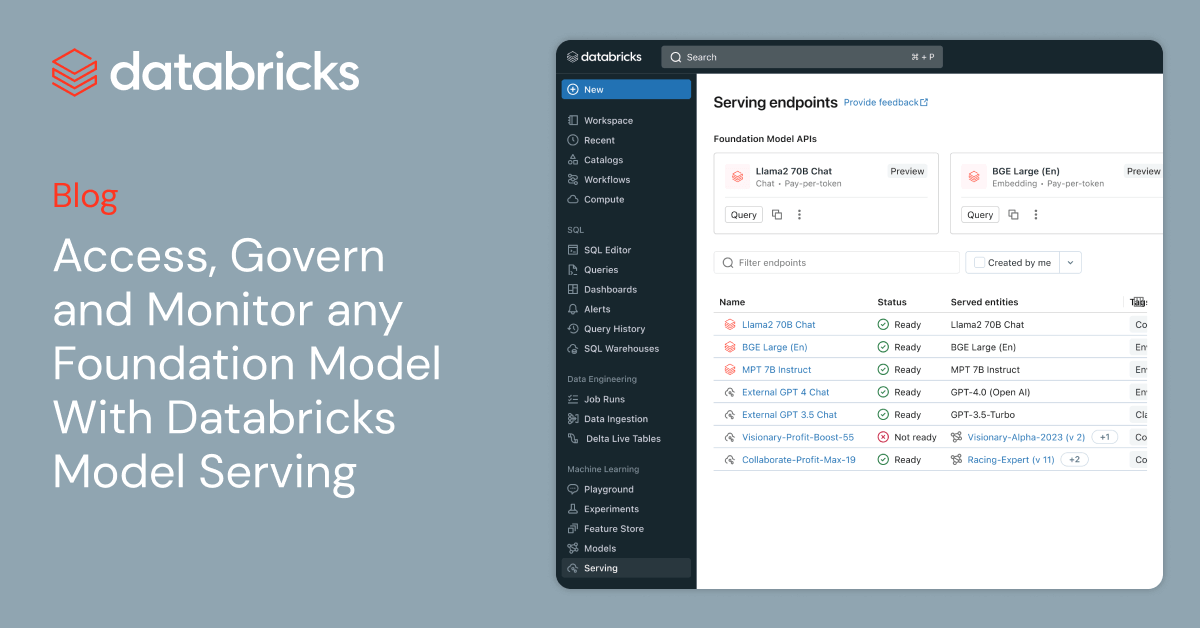
Build GenAI Apps Faster with New Foundation Model Capabilities
Following the announcements we made last week about Retrieval Augmented Generation (RAG), we’re excited to announce major updates to Model Serving. Databricks Model Serving now offers a unified interface, making it easier to experiment, customize, and productionize foundation models across all clouds and providers. This means you can create high-quality GenAI apps using the best […]
Continue Reading