
At eBay, we have approximately 152 million users and 1.5 billion live listings at any given time on our marketplace. This article takes a look at how we’ve created an in-house system, using a combination of engineering and machine learning methodologies to develop personalized recommendations for our community.
The blog headline may sound daunting, but let’s deconstruct it to see what we mean by it. By using the word “Building,” we’ll delve into step-by-step engineering instructions on how to develop a large-scale industrial system. Next is “Deep Learning,” which will cover the Natural Language Processing (NLP) methods to generate embeddings based on textual information of item and user entities. “Retrieval System” will review how to build a state-of-the-art index based on trained embeddings and using recent developments in Approximate Nearest Neighbor (ANN) methods to generate results quickly in real-time. And finally “Personalized Recommendations” is the product setting where we will discuss a recommender system generating personalized item recommendations based on a user’s past browsing activity.
Recommender systems are ubiquitous in ecommerce and most industrial web applications. This article will discuss a specific flavor of recommender systems where the input is a sequence of user-clicked items on an ecommerce platform, and the output would be “personalized” items that this user may be interested in purchasing. Typically, this recommendations module would appear on the “homepage” or an “item page” of an ecommerce marketplace, with a tag line that is something similar to “items based on your recent views”.
Figure 1: Personalized recommendations module on eBay’s homepage.
There are straightforward ways to generate this by using a user’s Recently Viewed Items (RVI) and generating similar items to these RVIs. However, if you want to build up a true user representation automatically and encapsulate it in a user embedding, as well as having your system learn that a “red dress” is similar to a “scarlet dress,” the power of deep learning is needed. Let’s learn how we build up this system step-by-step!
We have built this recommender system at eBay, however, the whole system or components of it can be applied to a variety of settings. This blog is aimed at large-scale, high-volume traffic production systems that require a low latency real-time response. We will now discuss the three phases we went through to build the recommender system: Phase 1: Offline, Phase 2: Offline / Near Real Time (NRT) Hybrid, and Phase 3: NRT.
Phase 1: Offline
The idea of this recommender system seems straightforward, but how do you put together all of the necessary components? Well, first off you would need an ecommerce website, a rendered UI module with item recommendations, and a real-time back-end application service for generating the content for that module. We assume all of these are already built, and we will focus on the back-end components and pipelines that power these components for this blog. Additionally, you would need a tracking/logging system in place that would capture a user’s click history on the website and aggregate it to a data lake, we use Hadoop for this.
Now that you have access to the data, your data scientists/machine learning engineers will build a two-tower NLP based deep learning model. Here is our version of this model. In a nutshell, one tower represents item embeddings and the other tower represents user embeddings, and we can use k-Nearest Neighbor (KNN) search methods to find the nearest item embedding for a given input user embedding. This is what we mean by “personalized recommendations.” For more details, please refer to the paper. This article’s focus is on the inference/prediction side, so we assume that we have a fully trained best-in-class model.
The easiest and first system that you may build will perform most of the calculations offline, and cache the results for fast run-time access. Here, we can refer to Figure 2 for our Phase 1 architectural diagram.
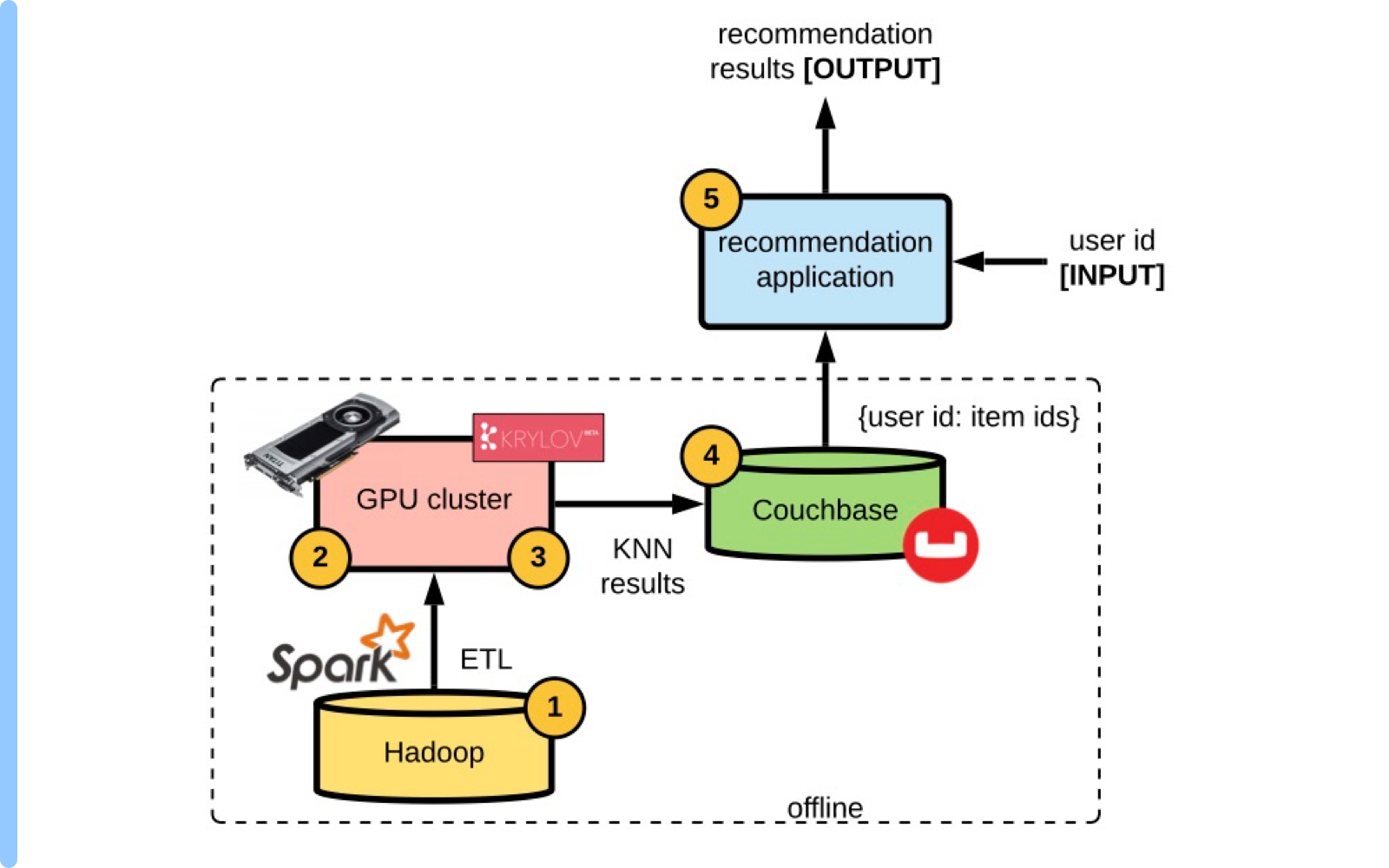
Figure 2: Architectural diagram for the Phase 1 recommender system.
Here are the steps to translate raw data into item recommendations in Phase 1:
- A daily ETL job (we use Spark for this) aggregates all of the raw item metadata (needed for machine learning (ML) features) and user historical data.
- Python scripts are run on the trained model file (we use PyTorch and pytorch-lightning frameworks), perhaps using a GPU accelerator (at eBay, our GPU cluster is called Krylov), to generate/predict the item and user embeddings using data from the previous step.
- A KNN search is then performed offline using a user embedding as input and searching through all of the candidate item embeddings (we use FAISS for this).
- These KNN results are then written to Couchbase DB with {key: value} = {user id: item ids}.
- Finally, the real-time recommendation application takes in a user id, when a user is browsing the website, calls the fast Couchbase run-time cache (latency ~few milliseconds) to get the recommendation results, and displays them to the user.
Scheduling this pipeline can be done using cron, Jenkins, Airflow or a combination of these.
Here are the pros and cons of this approach.
-
Pros:
- More basic architecture to start with
- Fast run-time using low latency cache
- Most computation is performed offline
-
Cons:
- The big con is there is delay (maybe one or two days depending on offline data infrastructure) between user activity and recommendation generation
Phase 2: Offline / Near Real Time (NRT) Hybrid
Now, our actual goal is to perform all of these calculations in Near Real Time (NRT) in order to reduce the big con of Phase 1. Phase 2 will act as a stepping stone on our journey to build this system. The critical component that needs to be built is a real-time KNN service in order to perform the KNN search in real time. With recent developments in ANN methods, such as HNSW or ScaNN, developing such a service has become practical and efficient. We continue generating the item and user embeddings offline; however, the KNN search is now performed in real-time. The input to the real-time KNN service is a user embedding, and the output is recommended items that would be relevant to the user. We built this service in-house at eBay, however, similar cloud services are available for customers, like the Vertex AI Matching Engine from Google. The ANN retrieval model performs well in terms of relevance quality, measured by a brute force comparison. The recommendation results from the real-time KNN service are very comparable to the offline Phase 1 KNN results when evaluated using human judgment.
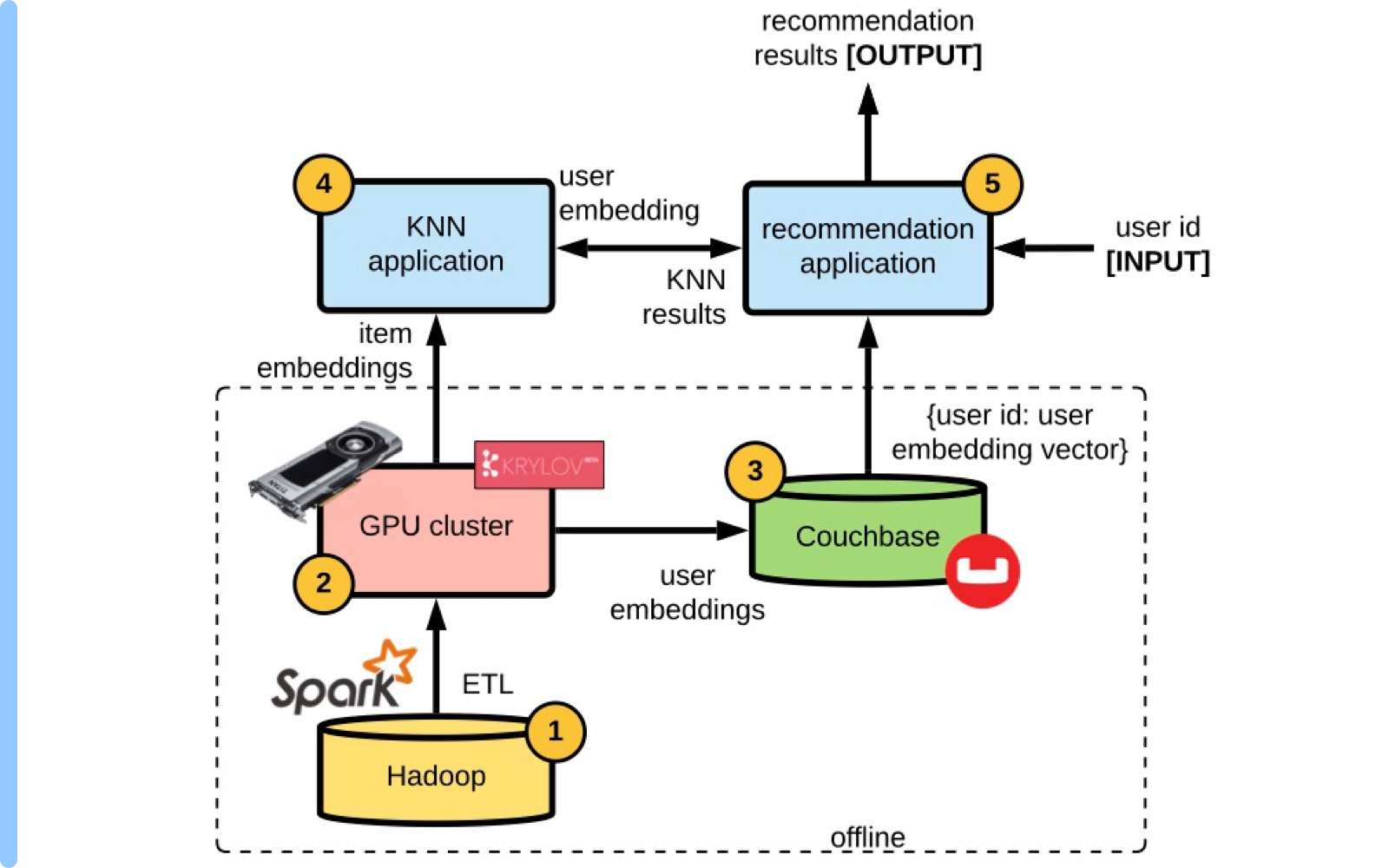
Figure 3: Architectural diagram for the Phase 2 recommender system, adding the KNN service.
Here are the steps for Phase 2 architecture:
- A daily ETL job. (same as Phase 1, Step 1)
- Python scripts to generate the item and user embeddings. (same as Phase 1, Step 2)
- Write user embeddings to Couchbase with {key: value} = {user id: user embedding vector}.
- Write item embeddings in batch mode to populate the real-time KNN service index.
- Finally, the real-time recommendation application takes in a user id, when a user is browsing the website, calls Couchbase to get a user embedding vector, then calls the real-time KNN service to perform the KNN search in real-time and displays the recommendation results back to the user.
Here are the pros and cons of this approach:
- Pros:
-
Cons:
- There is still a delay (maybe one or two days depending on offline data infrastructure) between user activity and recommendation generation due to offline embedding generation
Phase 3: NRT
Now, for the final iteration to develop the state-of-the-art deep learning based retrieval system — we want to move entirely away from offline processing towards NRT processing. This requires streaming technology in order to be able to process user click events in real-time, as well as a model prediction service that will perform deep learning model inference in real-time. As the user is clicking around on the ecommerce website, looking at different items to purchase, these events are captured by an event streaming platform, such as Apache Kafka. Then, we aggregate these events with an Apache Flink application, taking the last N events in order to generate the embedding for a user in real-time.
In order to generate a user embedding in real-time, we use a deep learning model prediction service, developed in-house at eBay. This service runs Nvidia’s Triton Inference Server to execute a deep learning model prediction on GPUs. We export our PyTorch models to Torchscript or ONNX format so that the prediction can run in an optimized non-Python environment. Finally, when a user embedding is generated in real-time, it is stored in Couchbase, so it is available for access by the recommendation back-end application.
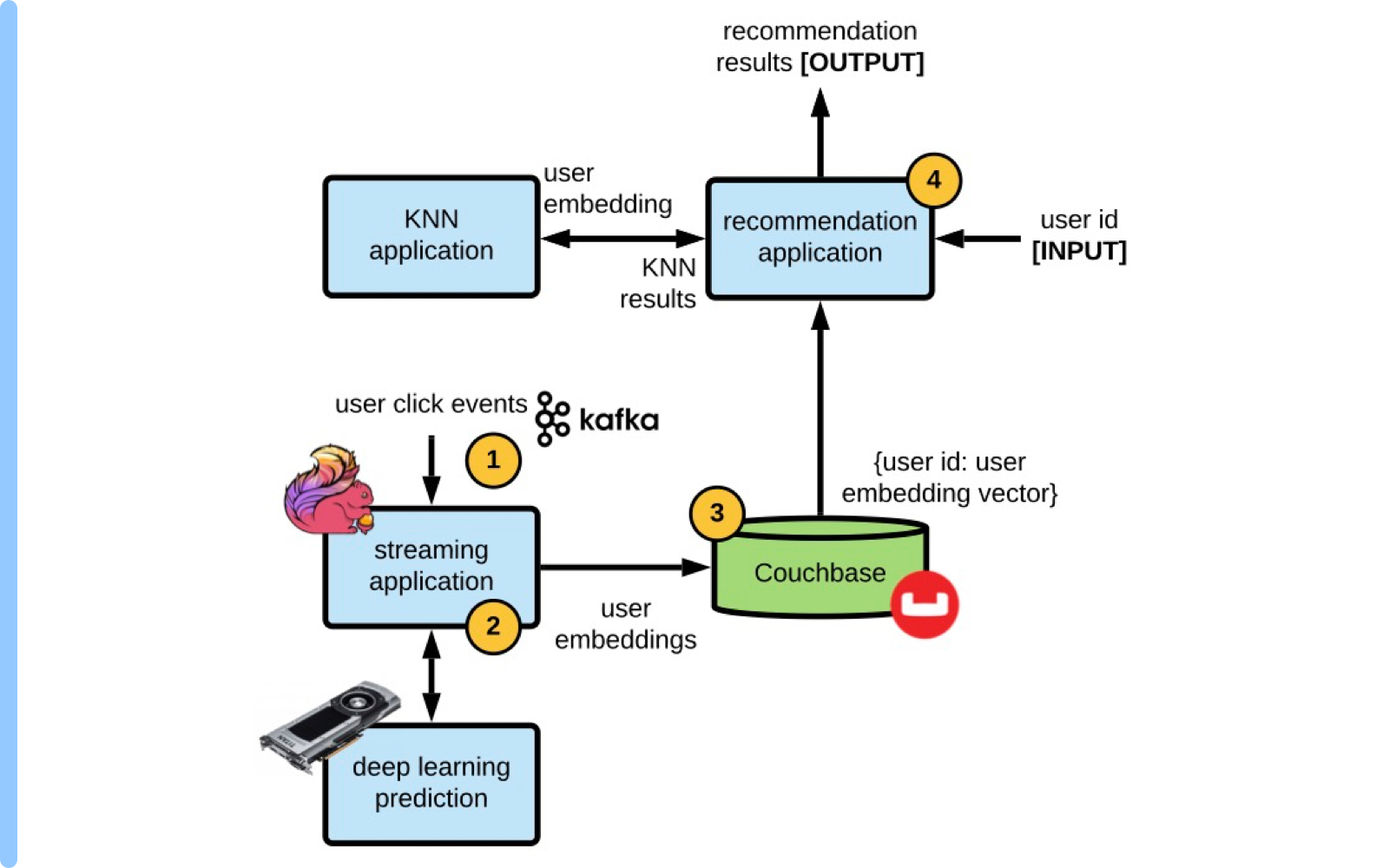
Figure 4: Architectural diagram for the Phase 3 recommender system, depicting fully NRT personalized recommendation generation.
Here are the steps for Phase 3 architecture put together:
- A user click event happens, it is captured by eBay’s Kafka event streaming platform.
- A Flink application captures several user events and calls the deep learning prediction service to generate the user embedding.
- Write user embeddings to Couchbase with {key: value} = {user id: user embedding vector}.
- Finally, the real-time recommendation application takes in a user id, when a user is browsing the website, calls Couchbase to get a NRT user embedding vector, then calls the real-time KNN service to perform the KNN search in real-time and displays the recommendation results back to the user. (same as Phase 2, Step 5, but with NRT user embeddings)
Note that the item flow that populates the KNN service here is the same as in Phase 2, but can be upgraded to NRT as well. Newly listed items, that were not loaded using the daily batch upload, can be loaded to the KNN service index using the Phase 3 type NRT solution, which makes the KNN service serve all of the live items continuously.
Here are the pros and cons of this approach:
-
Pros:
- Delay reduced to seconds using NRT
- Fast run-time using low latency cache
-
Cons:
- Advanced architecture complexity
- Maintenance of complex system
The system design evolution was broken up into these three phases from an organizational resource optimization perspective. Building the Phase 3 system may be a multi-year and certainly a multi-developer endeavor. So the idea here is that individual components will be built over time, potentially by separate scrum teams, and eventually the whole system will be completed. Furthermore, even if this exact system is not designed like we described, most of the components in this microservice architecture will be useful for a wide variety of recommender system and information retrieval tasks.
This article provides a high-level overview on the scale and complexity of building a deep learning based retrieval system for generating personalized recommendations.


