Introduction
Analysts need to analyse and simulate a rule on historical data to check the performance and accuracy of the rule. Backtesting enables analysts to run simulations of the rules and manage the results from the rule engine UI.
Backtesting helps analysts to:
- Define the desired impact of the rule for our business and users.
- Evaluate the accuracy of the rule based on historical data.
- Compare and analyse results with data points, such as known false positives, user segments, risk profile of a user or transaction, and so on.
Currently, the analytics process to test performance of a rule is not standardised, and is inaccurate and inefficient. Analysts from different teams have different approaches:
- Offline process using Presto tables. This process is lengthy and inaccurate.
- Offline process based on the rule engine payload. The setup takes time, and the process is not streamlined.
- Running rules in shadow mode. This process takes days to get the desired result.
- A team in Grab uses different rule engines to manage rules and do backtesting. This doubles the effort for analysts and engineers.
In our vision for backtesting, it should allow analysts to:
- Efficiently run and manage their jobs.
- Create custom metrics, reports and dimensions for backtesting.
- Add external data points and metrics to do a deep dive.
For the purpose of establishing a minimum viable product (MVP), backtesting will support basic capabilities and enable analysts to access required metrics and data points. Thus, analysts can:
- Run backtesting jobs from the rule engine UI.
- Get fixed reports and dimensions for every checkpoint.
- Get access to relevant data to analyse backtesting results.
Background
Assume a simple use case: A rule to detect the transaction risk.
Each transaction has a transaction_id, user_id, currency, amount, timestamp. The rule engine also provides a treatment (Approve or Decline) based on the rule logic for the transaction.
In this specific use case, we would like to see what will be the aggregation number of the total transactions, total distinct users, and the sum of the amount, based on the dimensions of date, treatment, and currency in the last couple of weeks.
The result may look like the following data:
| Dimension | Dimension | Dimension | metric | metric | metric |
|---|---|---|---|---|---|
| Date | Treatment | Currency | Total tx | Distinct user | Total amount |
| 2020-05-1 | Approve | SGD | 100 | 80 | 10020 |
| 2020-05-1 | Decline | SGD | 50 | 40 | 450 |
| 2020-05-1 | Approve | MYR | 110 | 100 | 1200 |
| 2020-05-1 | Decline | MYR | 30 | 15 | 400 |
* This data does not reflect actual Grab data and is for illustrative purposes only.
Solution
- Use a cloud-agnostic Spark-based data pipeline to replay any existing or proposed rule to check performance.
- Use a Web Portal to:
- Create or select a rule to replay, with replay time range.
- Display and download the result, such as total events and hit counts.
- Replay any existing or proposed rule for checking performance.
- Allow users to create or select a rule to replay in the rule engine UI, with provided replay time range.
- Display the replay result in the rule engine UI, such as total events and hit counts.
- Provide a way to download all testing results in the rule engine UI (for example, all rule responses).
- Remove dependency on the specific cloud provider stack, so other teams in Grab can use it instead of Google Cloud Platform (GCP).
Architecture details
The rule editor UI reacts to the user input. Its engine sends a job command to the Amazon Simple Queue Service (SQS) to initialise the job. After that, the rule editor also performs the following processes in the background:
- Lambda listens to the request SQS queue and invokes a job via the Spark jobs API.
- The job fetches the executable artifacts, data source. After the job is completed, the job script saves the result sheet as required to S3.
- The Spark script pushes the job final status (success, failure, timeout) through the shutdown hook to respond to the SQS queue.
- The rule editor engine listens to response callback messages, and processes the job metadata to the database, or sends notifications.
- The rule editor displays the job metadata on the UI.
- The package pipeline builds and deploys the executable artifacts to S3 as a manageable structure.
- The Spark script takes the filter logic as its input parameters.
Workflow
Historical data preparation
The historical events are published by the rule engine through Kafka, and stored into the S3 bucket based on time. The Backtesting system then fetches these data for testing based on the time range requested.
By using a Kubernetes stream pipeline, we also save the trust inference stream to Trust AWS subaccount. With the customer bucket and file format, we can improve the efficiency of the data processing, and also avoid any delay from the data lake.
Engineering specifications
s3a://stg-trust-inference-event/<engine-name>/<predict-name>/<YYYY>/MM/DD/hh/mm/ss/<000001>.snappy.parquet
s3a://prd-trust-inference-event/<engine-name>/<predict-name>/<YYYY>/MM/DD/hh/mm/ss/<000001>.snappy.parquet
Description: Following the fields of steam definition, the engine name would be ruleengine, or catwalk. The predict-name would be preride (checkpoint name), or cnpu (model name).
- File Format: avro
- File Compression: Snappy
- There is no auto retention on sub-account S3. We will implement the archive process in the future.
- The default pipeline and the new pipeline will run in parallel until the Data Engineering team is ready to retire the default pipeline.
Backtesting
- Upon scheduling, the Backtesting Portal sends a message to SQS, which is then captured by the listening Lambda.
- Lambda invokes a Spark job over the AWS elastic mapreduce engine (EMR).
- The EMR engine fetches the executable artifacts containing the rule script and historical data from S3, and starts a Spark job to apply the rule script over historical data. Depending on the size of data, the Spark cluster will scale automatically to ensure timely completion.
- Once completed, a report file is generated and available on Backtesting UI.
UI
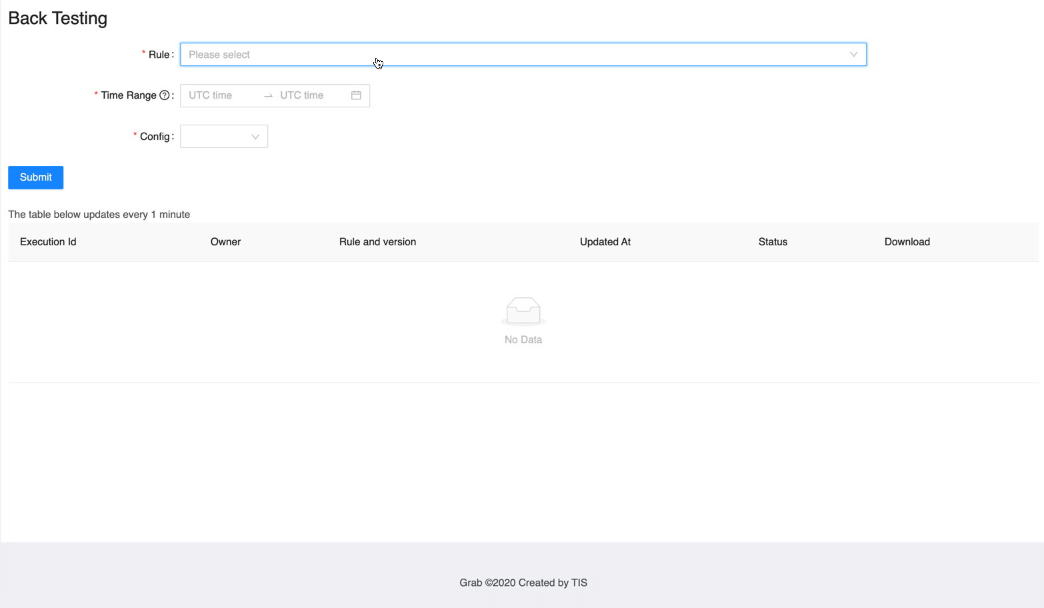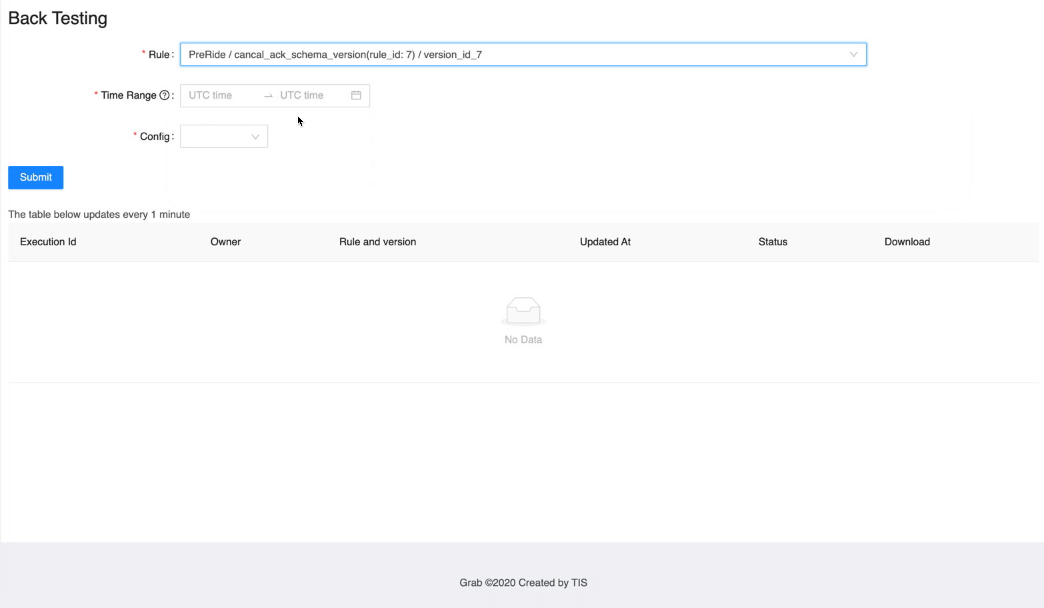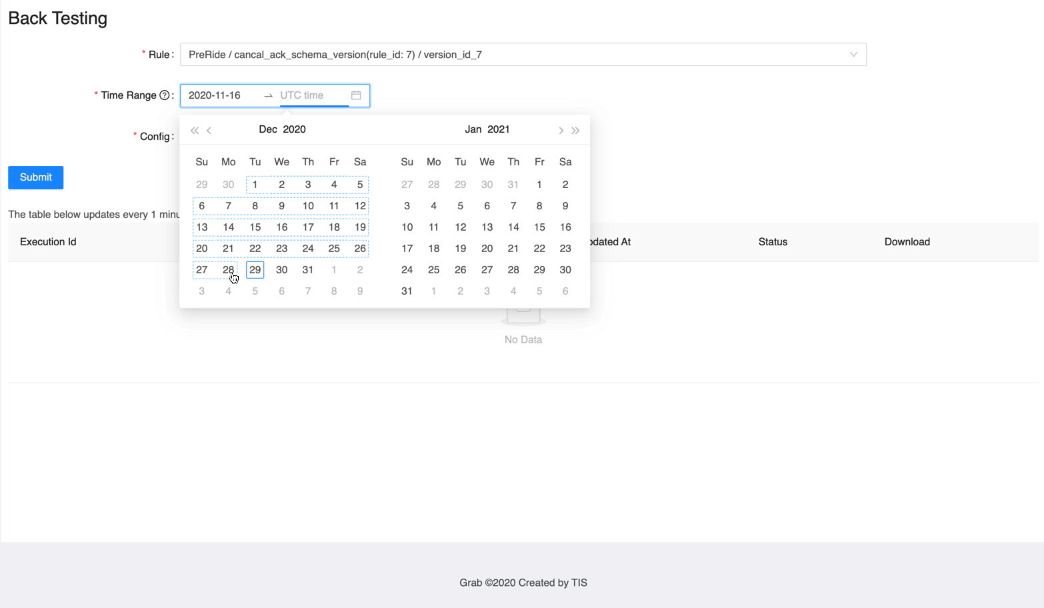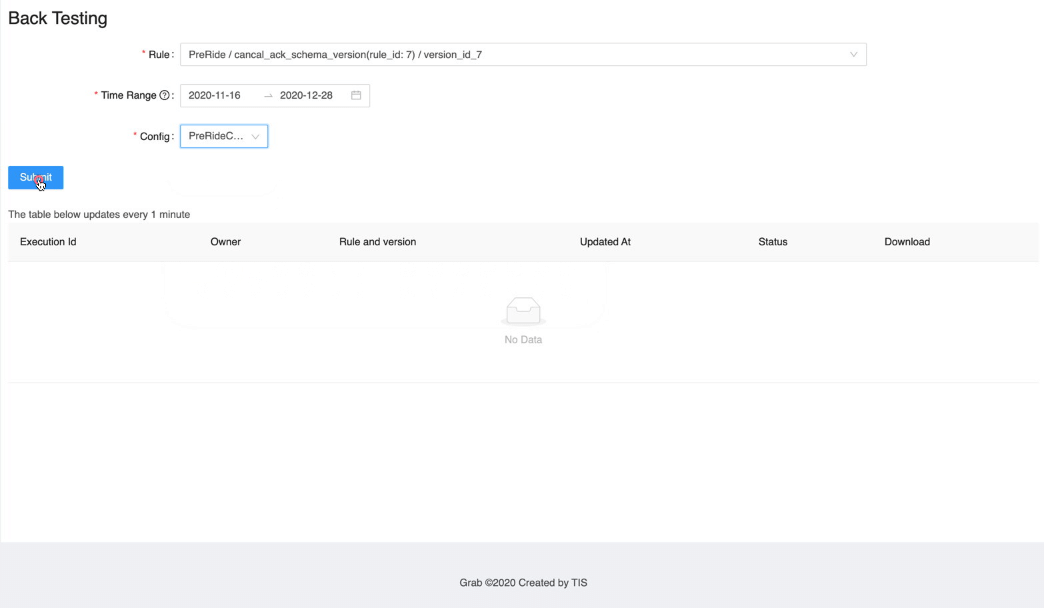
Learnings and conclusions
After the release, here’s what our data analysers had to say:
- For trust analysts, testing a rule on historical data happens outside the rule engine UI and is not user-friendly, leading to analysts wasting significant time.
- For financial analysts, as analysts migrate to the rule engine UI, the existing solution will be deprecated with no other solution.
- An alternative to simulate a rule; we no longer need to run a rule in shadow mode because we can use historical data to determine the outcome. This new approach saves us weeks of effort on the rule onboarding process.
What’s next?
The underlying Spark jobs in this tool were developed by knowledgeable data engineers, which is a disadvantage because it requires a high level of expertise to modify the analytics. To mitigate this restriction, we are looking into using domain-specific language (DSL) to allow users to input desired attributes and dimensions, and provide the job release pipeline for self-serving jobs.
Thanks to Jia Long Loh for the support on the offline infrastructure engineering.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!