
Databricks announced the public preview of Mosaic AI Agent Framework & Agent Evaluation alongside our Generative AI Cookbook at the Data + AI Summit 2024.
These tools are designed to help developers build and deploy high-quality Agentic and Retrieval Augmented Generation (RAG) applications within the Databricks Data Intelligence Platform.
Challenges with building high-quality Generative AI applications
While building a proof of concept for your GenAI application is relatively straightforward, delivering a high-quality application has proven to be challenging for a large number of customers. To meet the standard of quality required for customer-facing applications, AI output must be accurate, safe, and governed. To reach this level of quality, developers struggle to
- Choose the right metrics to evaluate the quality of the application
- Efficiently collect human feedback to measure the quality of the application
- Identify the root cause of quality problems
- Rapidly iterate to improve the quality of the application before deploying to production
Introducing Mosaic AI Agent Framework and Agent Evaluation
Built-in collaboration with the Mosaic Research team, Agent Framework and Agent Evaluation provide several capabilities that have been specifically built to address these challenges:
Quickly get human feedback – Agent Evaluation lets you define what high-quality answers look like for your GenAI application by letting you invite subject matter experts across your organization to review your application and provide feedback on the quality of responses even if they are not Databricks users.
Easy evaluation of your GenAI application – Agent Evaluation provides a suite of metrics, developed in collaboration with Mosaic Research, to measure your application’s quality. It automatically logs responses and feedback by humans to an evaluation table and lets you quickly analyze the results to identify potential quality issues. Our system-provided AI judges grade these responses on common criteria such as accuracy, hallucination, harmfulness, and helpfulness, identifying the root causes of any quality issues. These judges are calibrated using feedback from your subject matter experts, but can also measure quality without any human labels.
You can then experiment and tune various configurations of your application using Agent Framework to address these quality issues, measuring each change’s impact on your app’s quality. Once you have hit your quality threshold, you can use Agent Evaluations’ cost and latency metrics to determine the optimal trade-off between quality/cost/latency.
Fast, End-to-End Development Workflow – Agent Framework is integrated with MLflow and enables developers to use the standard MLflow APIs like log_model and mlflow.evaluate to log a GenAI application and evaluate its quality. Once satisfied with the quality, developers can use MLflow to deploy these applications to production and get feedback from users to further improve the quality. Agent Framework and Agent Evaluation integrate with MLflow and the Data Intelligence platform to provide a fully paved path to build and deploy GenAI applications.
App Lifecycle Management – Agent Framework provides a simplified SDK for managing the lifecycle of agentic applications from managing permissions to deployment with Mosaic AI Model Serving.
To help you get started building high-quality applications using Agent Framework and Agent Evaluation, Generative AI Cookbook is a definitive how-to guide that demonstrates every step to take your app from POC to production, while explaining the most important configuration options & approaches that can increase application quality.
Building a high-quality RAG agent
To understand these new capabilities, let’s walk through an example of building a high-quality agentic application using Agent Framework and improving its quality using Agent Evaluation. You can look at the complete code for this example and more advanced examples in the Generative AI Cookbook here.
In this example, we are going to build and deploy a simple RAG application that retrieves relevant chunks from a pre-created vector index and summarizes them as a response to a query. You can build the RAG application using any framework, including native Python code, but in this example, we are using Langchain.
# ##################################
# Connect to the Vector Search Index
# ##################################
vs_client = VectorSearchClient()
vs_index = vs_client.get_index(
endpoint_name="vector_search_endpoint",
index_name="vector_index_name",
)
# ##################################
# Set the Vector Search index into a LangChain retriever
# ##################################
vector_search_as_retriever = DatabricksVectorSearch(
vs_index,
text_column='chunk_text',
columns=['chunk_id', 'chunk_text', 'document_uri'],
).as_retriever()
# ##################################
# RAG Chain
# ##################################
prompt = PromptTemplate(
template = "Answer the question...",
input_variables = ["question", "context"],
)
chain = (
{
"question": itemgetter("messages"),
"context": itemgetter("messages")| vector_search_as_retriever,
}
| prompt
| ChatDatabricks(endpoint='dbrx_endpoint')
| StrOutputParser()
)The first thing we want to do is leverage MLflow to enable traces and deploy the application. This can be done by adding three simple lines in the application code (above) that allow Agent Framework to provide traces and an easy way to observe and debug the application.
## Enable MLflow Tracing
mlflow.langchain.autolog()
## Inform MLflow about the schema of the retriever so that
# 1. Review App can properly display retrieved chunks
# 2. Agent Evaluation can measure the retriever
############
mlflow.models.set_retriever_schema(
primary_key='chunk_id'),
text_column='chunk_text',
doc_uri='document_uri'), # Review App uses `doc_uri` to display
chunks from the same document in a single view
)
## Tell MLflow logging where to find your chain.
mlflow.models.set_model(model=chain)MLflow Tracing provides observability into your application during development and production
The next step is to register the GenAI application in Unity Catalog and deploy it as a proof of concept to get feedback from stakeholders using Agent Evaluation’s review application.
# Use Unity Catalog to log the chain
mlflow.set_registry_uri('databricks-uc')
UC_MODEL_NAME='databricks-rag-app'
# Register the chain to UC
uc_registered_model_info = mlflow.register_model(model_uri=model_uri,
name=UC_MODEL_NAME)
# Use Agent Framework to deploy a model registed in UC to the Agent
Evaluation review application & create an agent serving endpoint
deployment_info = agents.deploy(model_name=UC_MODEL_NAME,
model_version=uc_model.version)
# Assign permissions to the Review App any user in your SSO
agents.set_permissions(model_name=UC_MODEL_NAME,
users=["[email protected]"],
permission_level=agents.PermissionLevel.CAN_QUERY)You can share the browser link with stakeholders and start getting feedback immediately! The feedback is stored as delta tables in your Unity Catalog and can be used to build an evaluation dataset.
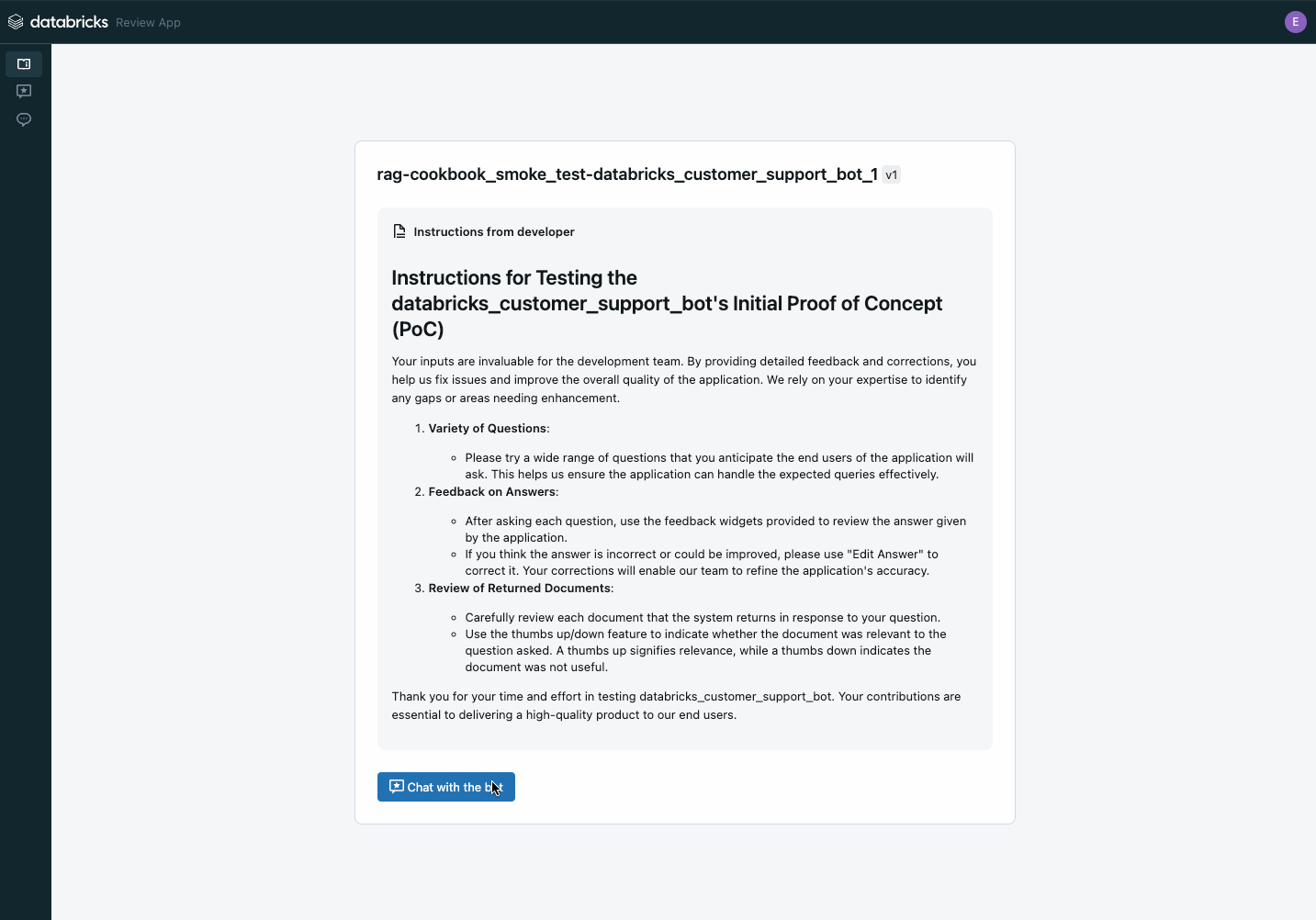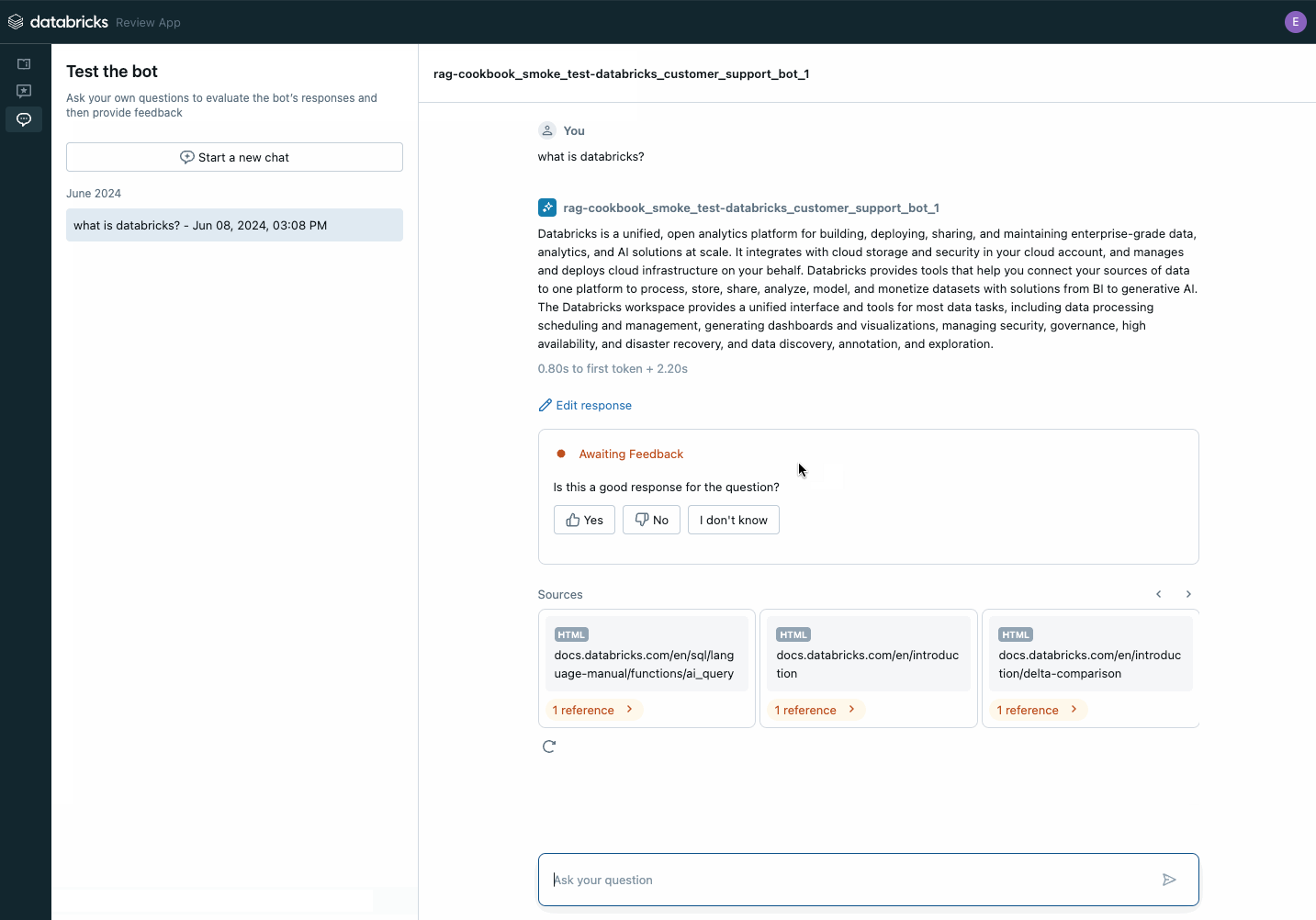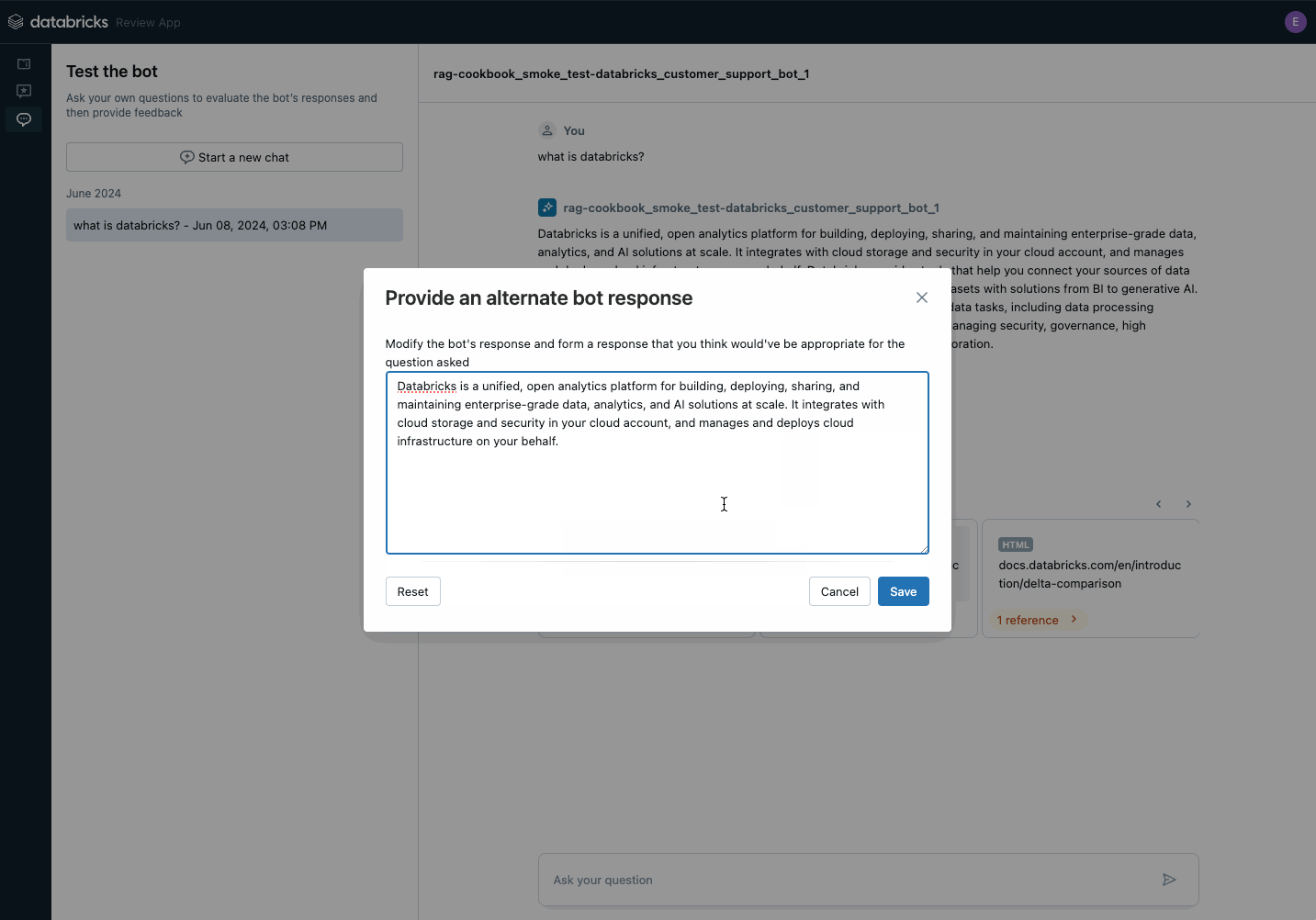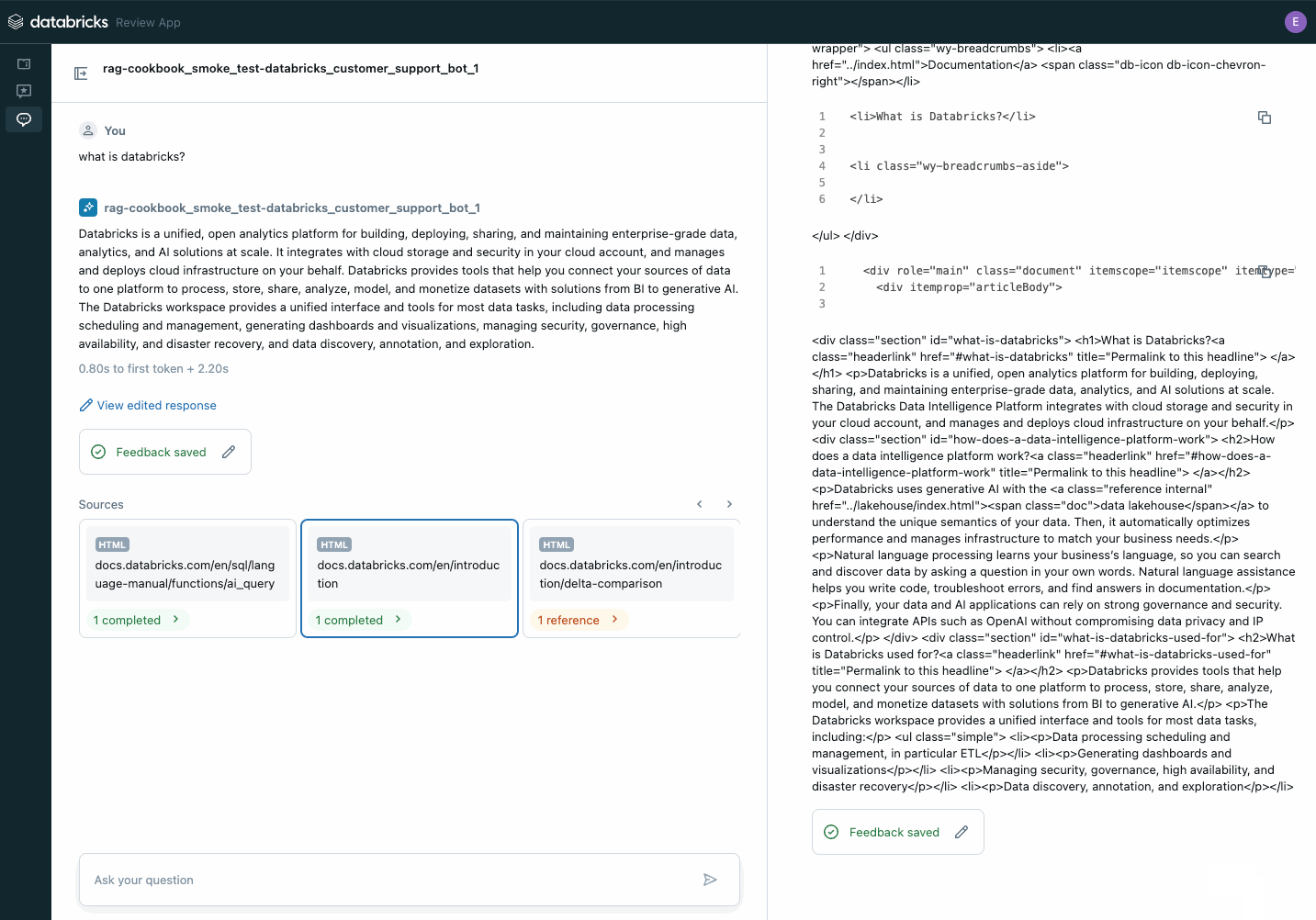
Use the review application to collect stakeholder feedback on your POC
Corning is a materials science company – our glass and ceramics technologies are used in many industrial and scientific applications, so understanding and acting on our data is essential. We built an AI research assistant using Databricks Mosaic AI Agent Framework to index hundreds of thousands of documents including US patent office data. Having our LLM-powered assistant respond to questions with high accuracy was extremely important to us – that way, our researchers could find and further the tasks they were working on. To implement this, we used Databricks Mosaic AI Agent Framework to build a Hi Hello Generative AI solution augmented with the U.S. patent office data. By leveraging the Databricks Data Intelligence Platform, we significantly improved retrieval speed, response quality, and accuracy.
— Denis Kamotsky, Principal Software Engineer, Corning
Once you start receiving the feedback to create your evaluation dataset, you can use Agent Evaluation and the in-built AI judges to review each response against a set of quality criteria using pre-built metrics:
- Answer correctness – is the app’s response accurate?
- Groundness – is the app’s response grounded in the retrieved data or is the app hallucinating?
- Retrieval relevance – is the retrieved data relevant to the user’s question?
- Answer relevance – is the app’s response on-topic to the user’s question?
- Safety – does the app’s response contain any harmful content?
# Run mlflow.evluate to get AI judges to evaluate the dataset.
eval_results = mlflow.evaluate(
data=eval_df, # Evaluation set
model=poc_app.model_uri, # from the POC step above
model_type="databricks-agent", # Use Agent Evaluation
)The aggregated metrics and evaluation of each question in the evaluation set are logged to MLflow. Each LLM-powered judgment is backed by a written rationale for why. The results of this evaluation can be used to identify the root causes of quality issues. Refer to the Cookbook sections Evaluate the POC’s quality and Identify the root cause of quality issues for a detailed walkthrough.
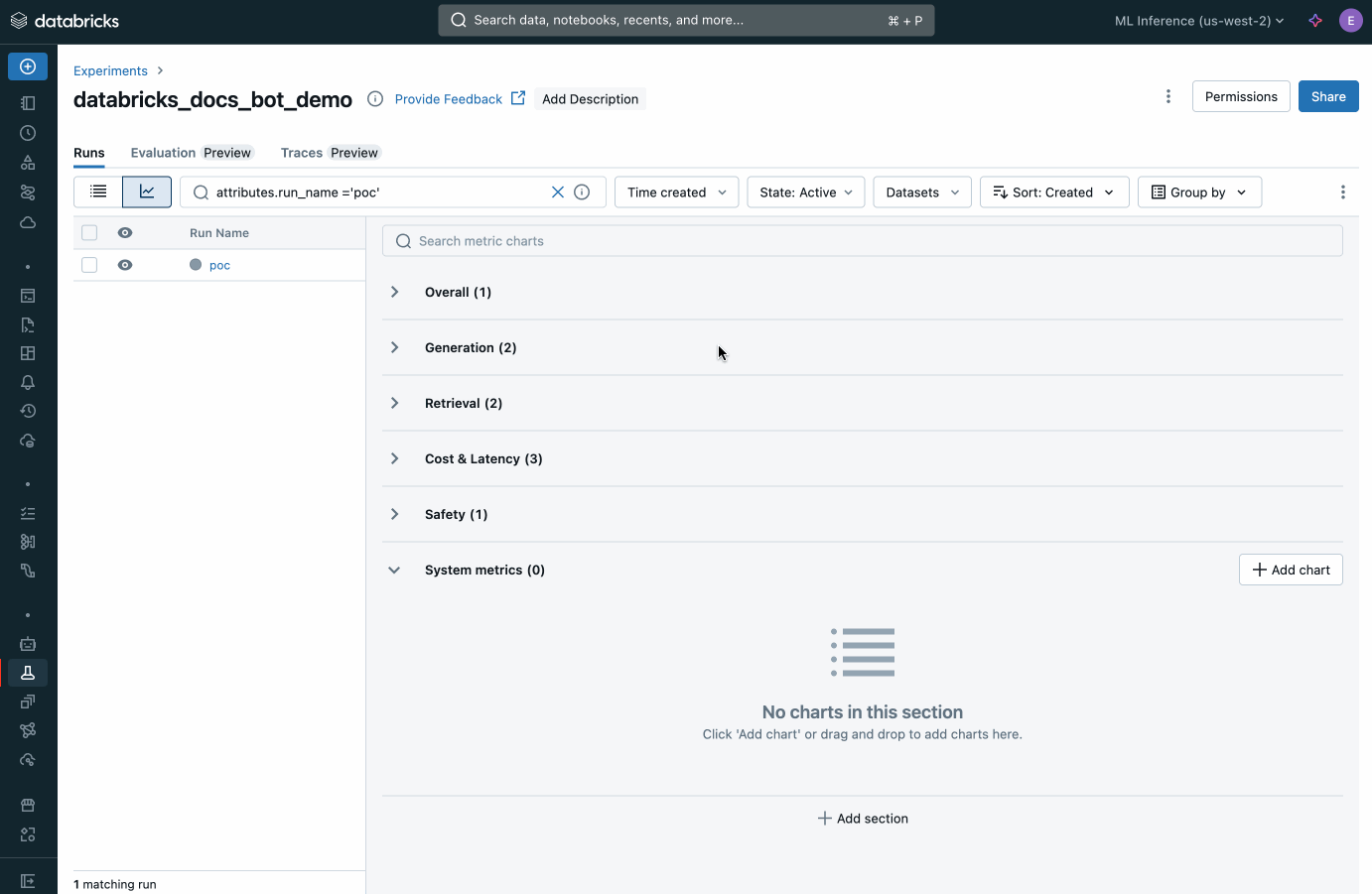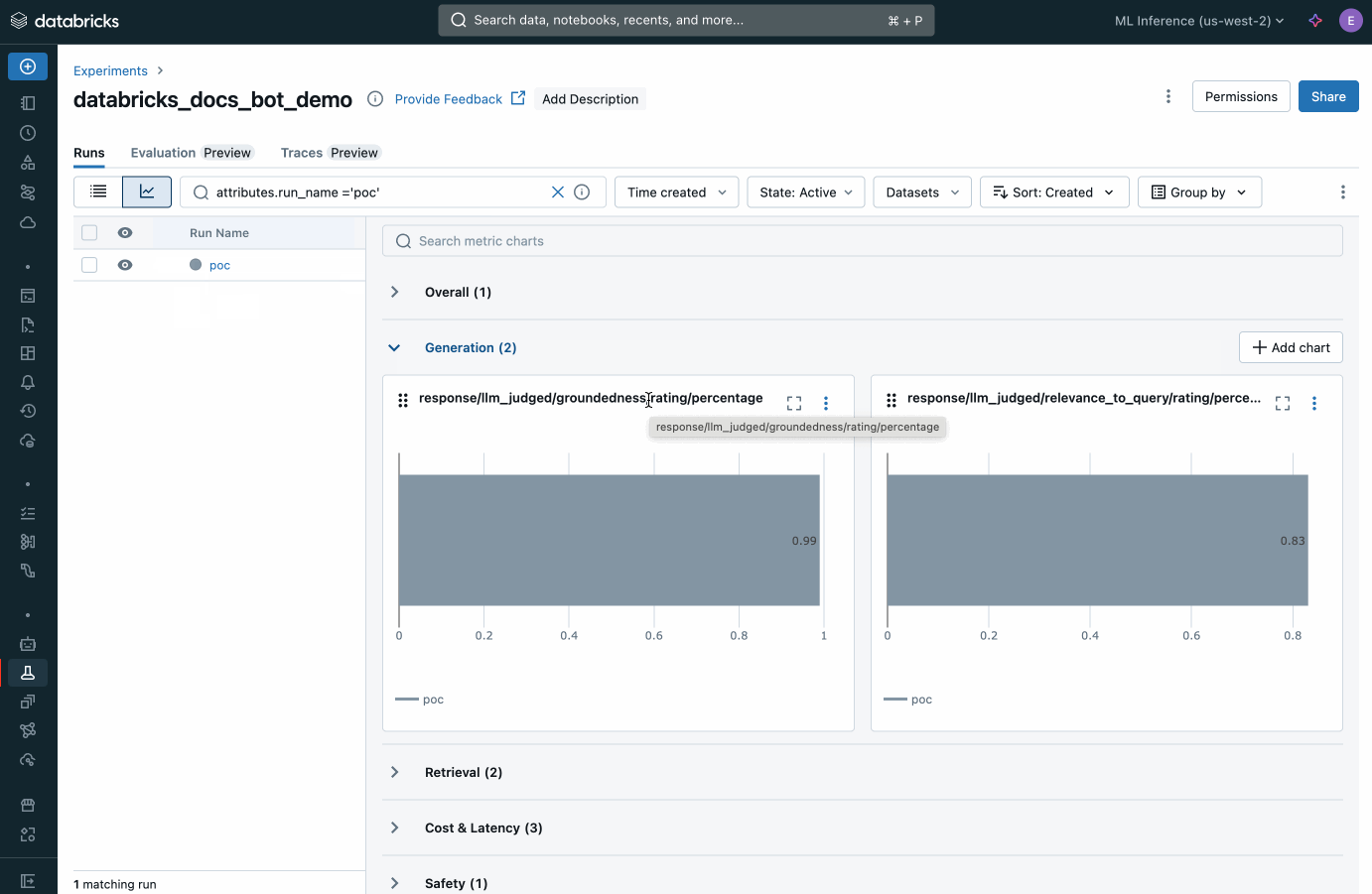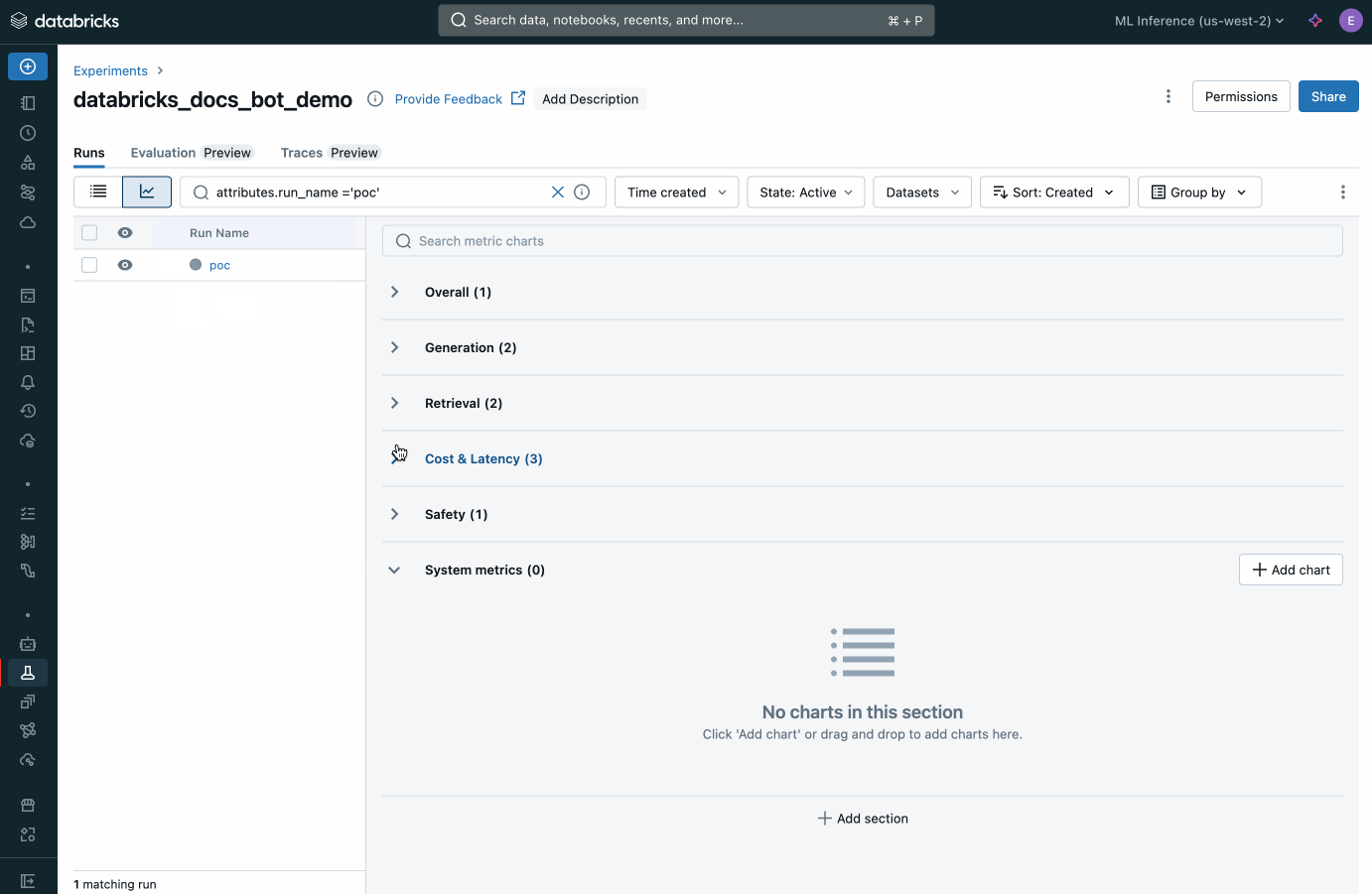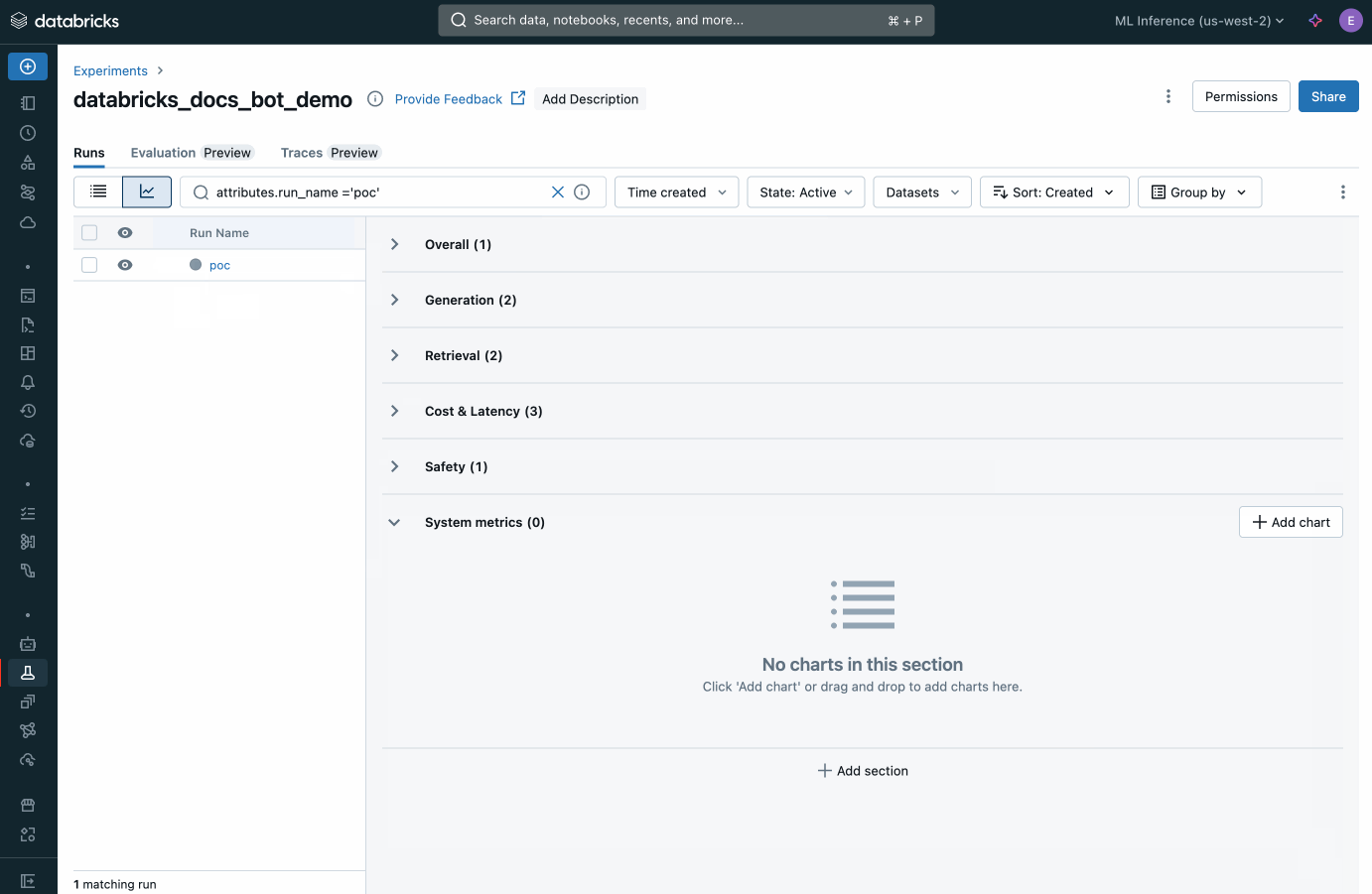
View the aggregate metrics from Agent Evaluation inside MLflow
As a leading global manufacturer, Lippert leverages data and AI to build highly-engineered products, customized solutions and the best possible experiences. Mosaic AI Agent Framework has been a game-changer for us because it allowed us to evaluate the results of our GenAI applications and demonstrate the accuracy of our outputs while maintaining complete control over our data sources. Thanks to the Databricks Data Intelligence Platform, I’m confident in deploying to production.
— Kenan Colson, VP Data & AI, Lippert
You can also inspect each individual record in your evaluation dataset to better understand what is happening or use MLflow trace to identify potential quality issues.
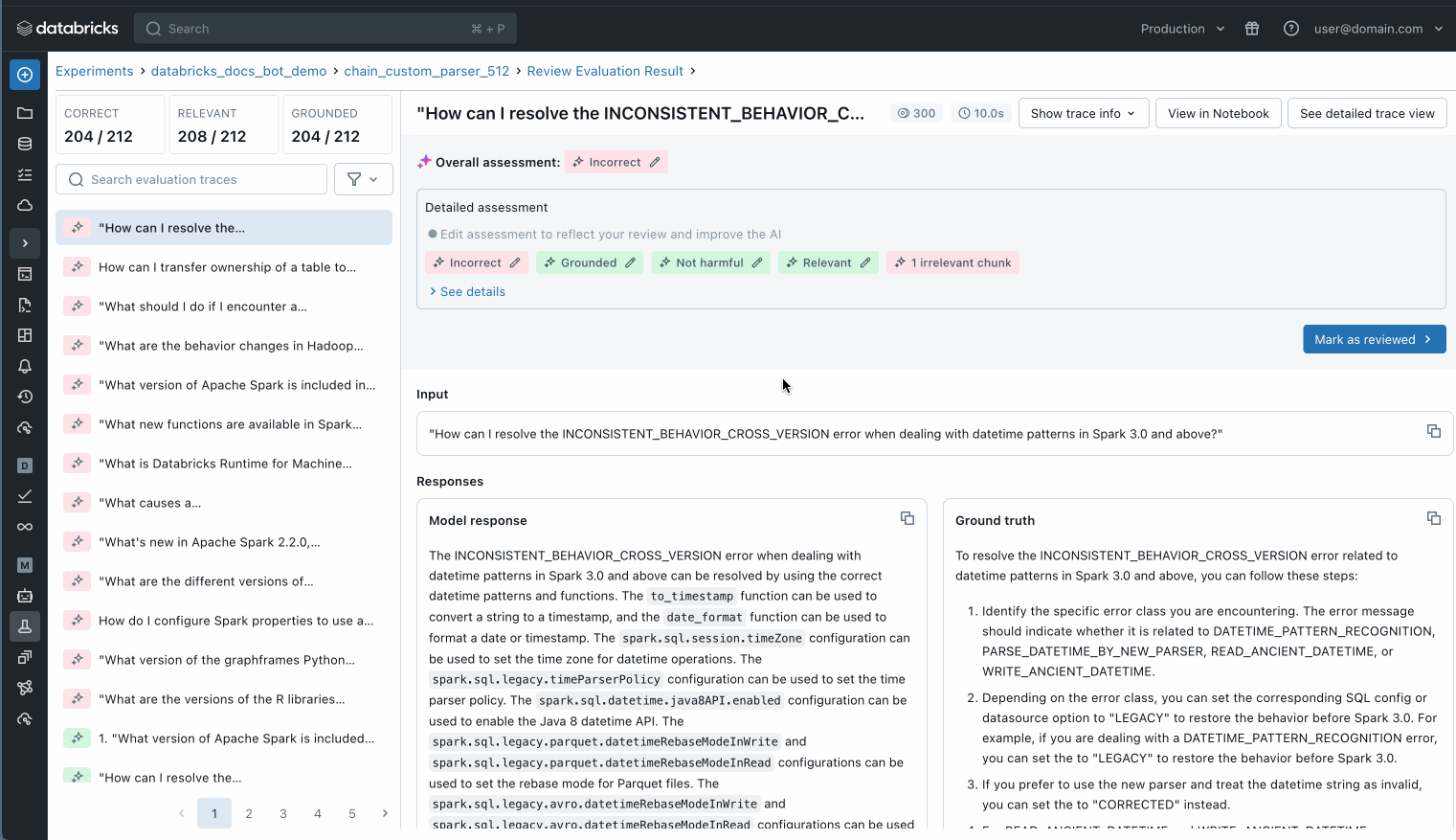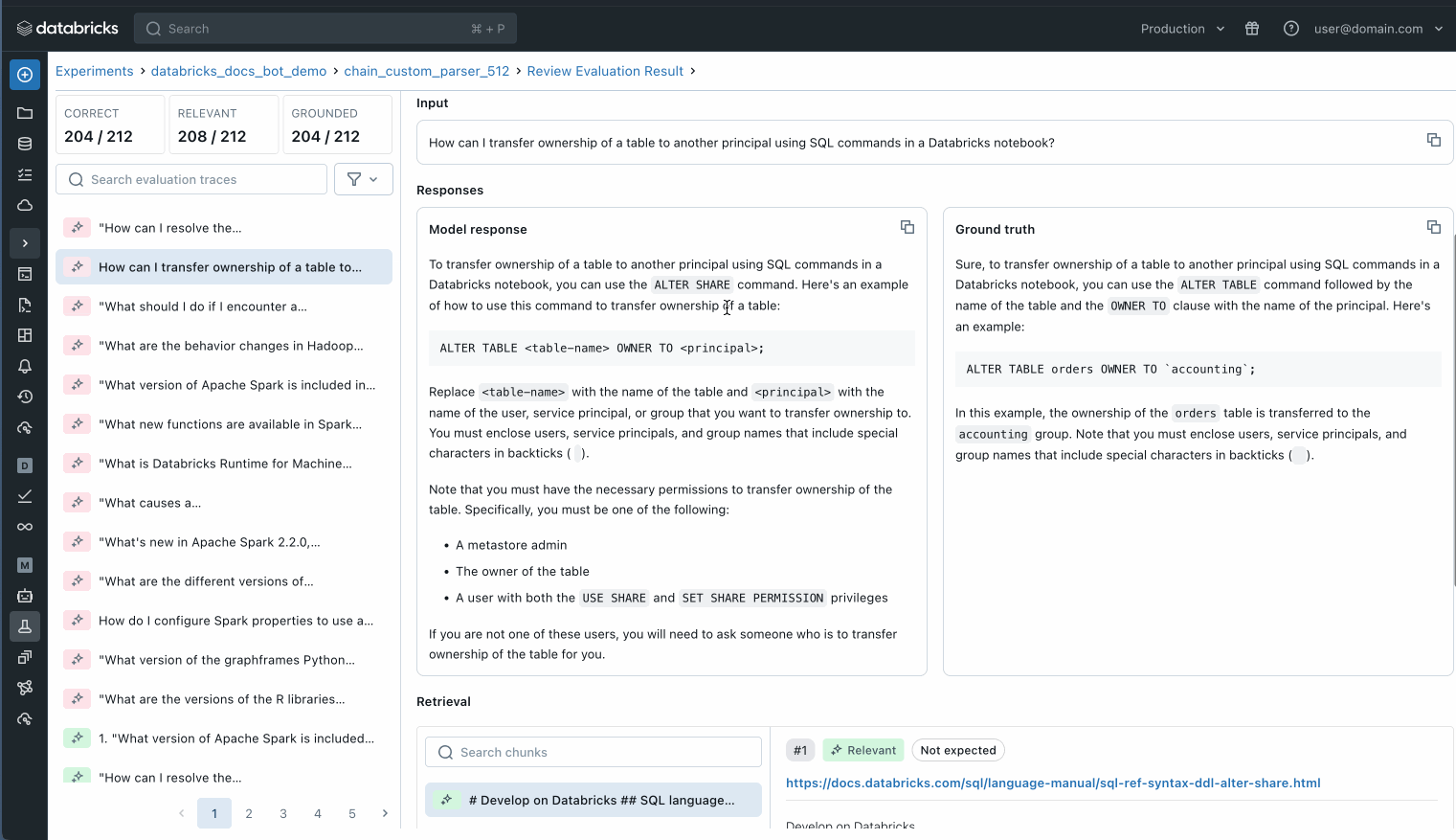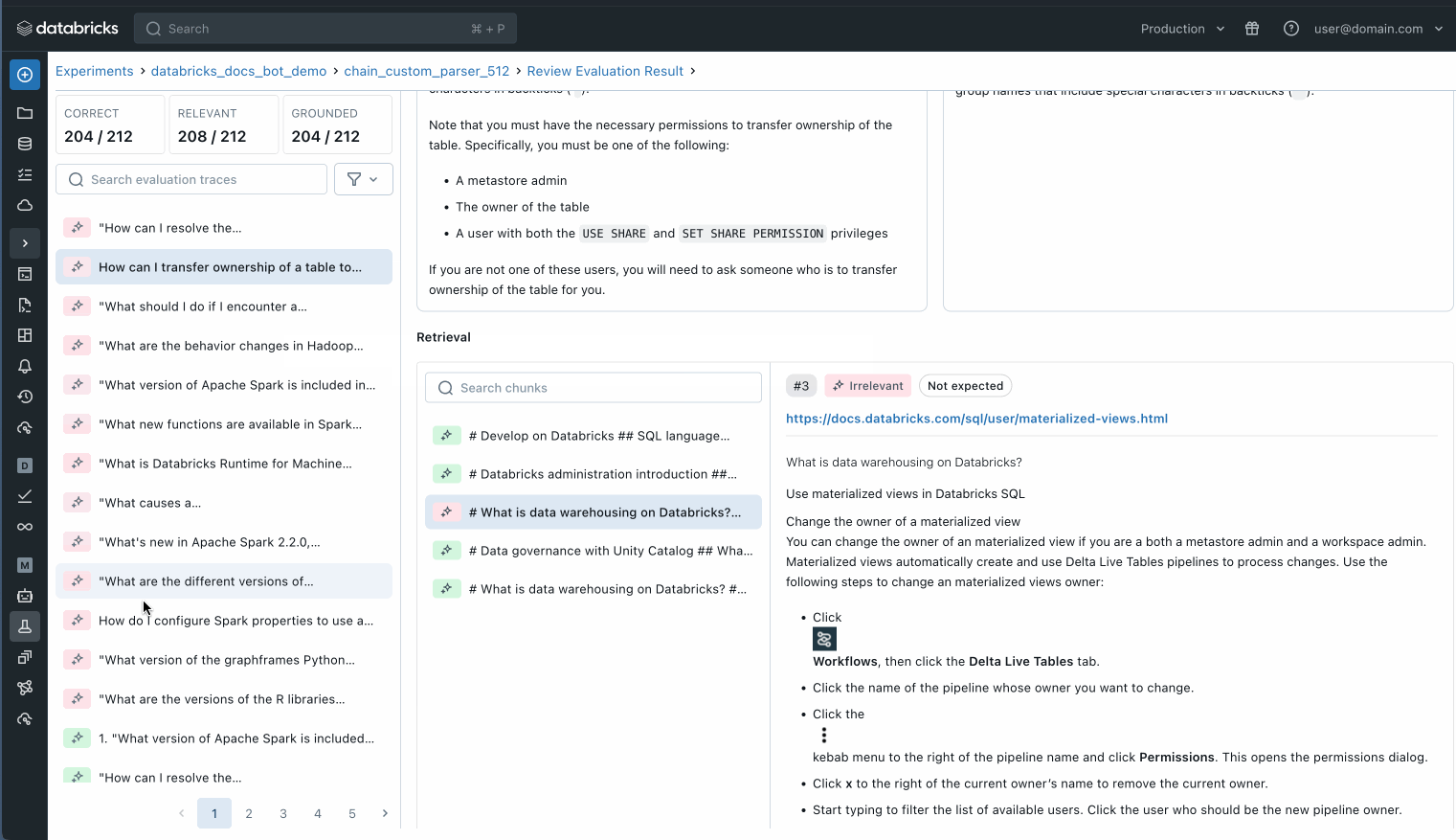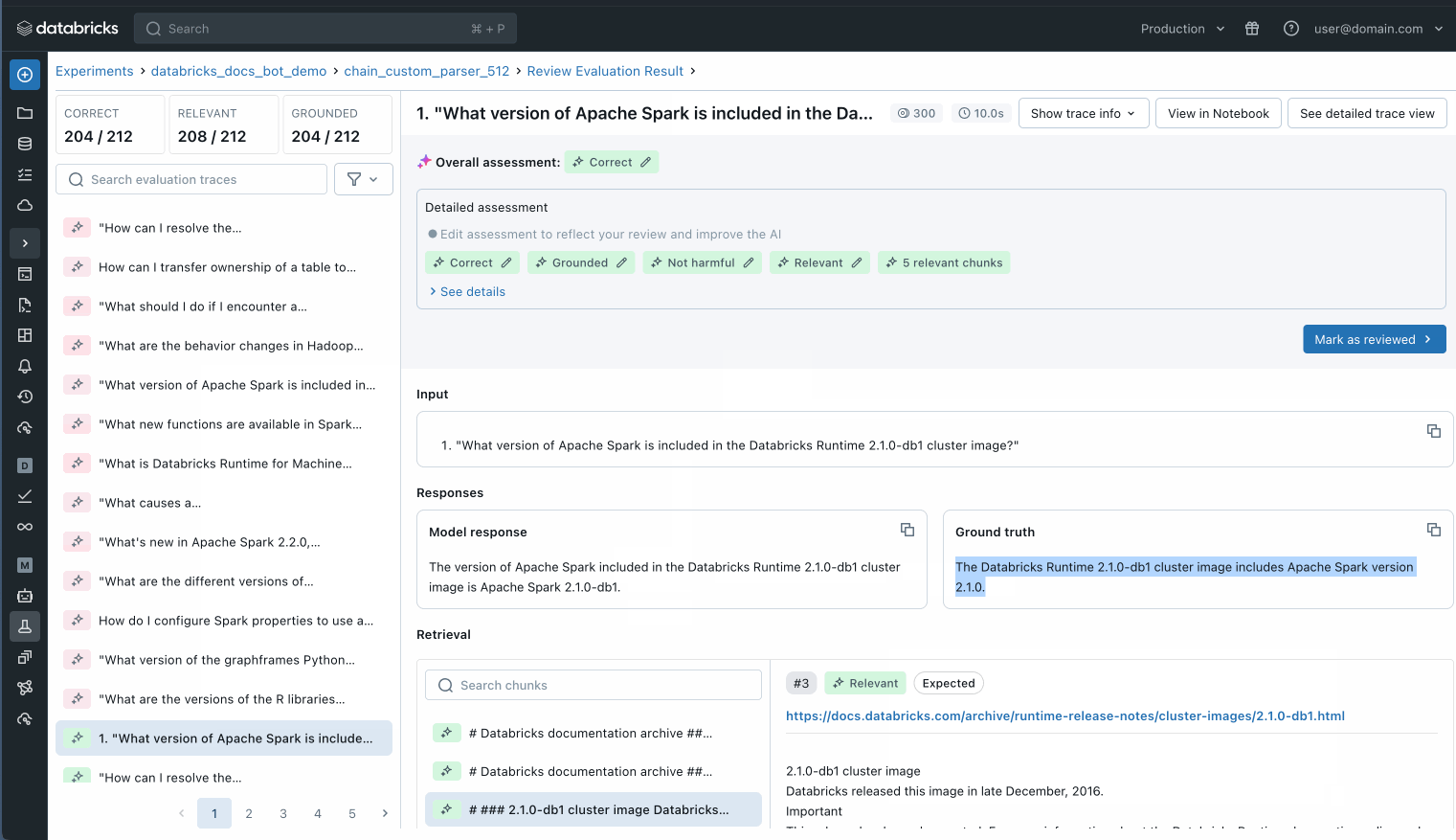
Inspect each individual record in your evaluation set to understand what is happening
Once you have iterated on the quality and satisfied with the quality, you can deploy the application in your production workspace with minimal effort since the application is already registered in Unity Catalog.
# Deploy the application in production.
# Note how this command is the same as the previous deployment - all
agents deployed with Agent Framework automatically create a
production-ready, scalable API
deployment_info = agents.deploy(model_name=UC_MODEL_NAME,
model_version=MODEL_VERSION_NUMBER)Mosaic AI Agent Framework has allowed us to rapidly experiment with augmented LLMs, safe in the knowledge any private data remains within our control. The seamless integration with MLflow and Model Serving ensures our ML Engineering team can scale from POC to production with minimal complexity.
— Ben Halsall, Analytics Director, Burberry
These capabilities are tightly integrated with Unity Catalog to provide governance, MLflow to provide lineage and metadata management, and LLM Guardrails to provide safety.
Ford Direct is on the leading edge of the digital transformation of the automotive industry. We are the data hub for Ford and Lincoln dealerships, and we needed to create a unified chatbot to help our dealers assess their performance, inventory, trends, and customer engagement metrics. Databricks Mosaic AI Agent Framework allowed us to integrate our proprietary data and documentation into our Generative AI solution that uses RAG. The integration of Mosaic AI with Databricks Delta Tables and Unity Catalog made it seamless to our vector indexes real-time as our source data is updated, without needing to touch our deployed model.
— Tom Thomas, VP of Analytics, FordDirect
Pricing
- Agent Evaluation – priced per Judge Request
- Mosaic AI Model Serving – serve agents; priced based on Mosaic AI Model Serving rates
For additional details refer to our pricing site.
Next Steps
Agent Framework and Agent Evaluation are the best ways to build production-quality Agentic and Retrieval Augmented Generation Applications. We are excited to have more customers try it and give us your feedback. To get started, see the following resources:
To help you weave these capabilities into your application, the Generative AI Cookbook provides sample code that demonstrates how to follow an evaluation-driven development workflow using Agent Framework and Agent Evaluation to take your app from POC to production. Further, the Cookbook outlines the most relevant configuration options & approaches that can increase application quality.
Try Agent Framework & Agent Evaluation today by running our demo notebook or by following the Cookbook to build an app with your data.


