
Every morning Susan walks straight into a storm of messages, and doesn’t know where to start! Susan is a customer success specialist at a global retailer, and her primary objective is to ensure customers are happy and receive personalised service whenever they encounter issues.
Overnight the company receives hundreds of reviews and feedback across multiple channels including websites, apps, social media posts, and email. Susan starts her day by logging into each of these systems and picking up the messages not yet collected by her colleagues. Next, she has to make sense of these messages, identify what needs to be responded to, and formulate a response for the customer. It isn’t easy because these messages are often in different formats and every customer expresses their opinions in their own unique style.
Here’s a sample of what she has to deal with (for the purposes of this article, we’re utilising extracts from Amazon’s customer review dataset)
Susan feels uneasy because she knows she isn’t always interpreting, categorizing, and responding to these messages in a consistent manner. Her biggest fear is that she may inadvertently miss responding to a customer because she didn’t properly interpret their message. Susan isn’t alone. Many of her colleagues feel this way, as do most fellow customer service representatives out there!
The challenge for retailers is how do they aggregate, analyse, and action this freeform feedback in a timely manner? A good first step is leveraging the Lakehouse to seamlessly collate all these messages across all these systems into one place. But then what?
Enter LLMs
Large language models (LLMs) are perfect for this scenario. As their name implies, they are highly capable of making sense of complex unstructured text. They are also adept at summarizing key topics discussed, determining sentiment, and even generating responses. However, not every organization has the resources or expertise to develop and maintain its own LLM models.
Luckily, in today’s world, we have LLMs we can leverage as a service, such as Azure OpenAI’s GPT models. The question then becomes: how do we apply these models to our data in the Lakehouse?
In this walkthrough, we’ll show you how you can apply Azure OpenAI’s GPT models to unstructured data that is residing in your Databricks Lakehouse and end up with well-structured queryable data. We will take customer reviews, identify topics discussed, their sentiment, and determine whether the feedback requires a response from our customer success team. We’ll even pre-generate a message for them!
The problems that need to be solved for Susan’s company include:
- Utilizing a readily available LLM that also has enterprise support and governance
- Generate consistent meaning against freeform feedback
- Determining if a next action is required
- Most importantly, allow analysts to interact with the LLM using familiar SQL skills
Walkthrough: Databricks SQL AI Functions
AI Functions simplifies the daunting task of deriving meaning from unstructured data. In this walkthrough, we’ll leverage a deployment of an Azure OpenAI model to apply conversational logic to freeform customer reviews.

Pre-requisites
We need the following to get started
- Sign up for the SQL AI Functions public preview
- An Azure OpenAI key
- Store the key in Databricks Secrets (documentation: AWS, Azure, GCP)
- A Databricks SQL Pro or Serverless warehouse
Prompt Design
To get the best out of a generative model, we need a well-formed prompt (i.e. the question we ask the model) that provides us with a meaningful answer. Furthermore, we need the response in a format that can be easily loaded into a Delta table. Fortunately, we can tell the model to return its analysis in the format of a JSON object.
Here is the prompt we use for determining entity sentiment and whether the review requires a follow-up:
A customer left a review. We follow up with anyone who appears unhappy.
Extract all entities mentioned. For each entity:
- classify sentiment as ["POSITIVE", "NEUTRAL", "NEGATIVE"]
- whether customer requires a follow-up: Y or N
- reason for requiring followup
Return JSON ONLY. No other text outside the JSON. JSON format:
{
entities: [{
"entity_name": <entity name>,
"entity_type": <entity type>,
"entity_sentiment": <entity sentiment>,
"followup": <Y or N for follow up>,
"followup_reason": <reason for followup>
}]
}
Review:
Like other users, whose reviews I wish I'd paid more attention to, the
consistent performance of these k-cups is disappointing. Attracted to the
product by its bargain price, I'm reminded you often get what you buy. While
the coffee tastes OK, it's no better than most other brands I've purchased.
This is the ONLY brand I've purchased, though, that has a defect about 50%
of the time. Coffee goes into the cup and sprays into the cup holder which
ruins the beverage. With only about half of the cups working properly that
effectively doubles the cost making it anything but a bargain. I will not
purchase again and, if asked, will recommend against purchases.Running this on its own gives us a response like
{
"entities": [
{
"entity_name": "k-cups",
"entity_type": "product",
"entity_sentiment": "NEGATIVE",
"followup": "Y",
"followup_reason": "Defect in 50% of the cups"
},
{
"entity_name": "coffee",
"entity_type": "product",
"entity_sentiment": "NEUTRAL",
"followup": "N",
"followup_reason": ""
},
{
"entity_name": "price",
"entity_type": "attribute",
"entity_sentiment": "NEGATIVE",
"followup": "N",
"followup_reason": ""
}
]
}Similarly, for generating a response back to the customer, we use a prompt like
A customer of ours was unhappy about <product name> specifically
about <entity> due to <reason>. Provide an empathetic message I can
send to my customer including the offer to have a call with the relevant
product manager to leave feedback. I want to win back their favour and
I do not want the customer to churnAI Functions
We’ll use Databricks SQL AI Functions as our interface for interacting with Azure OpenAI. Utilising SQL provides us with three key benefits:
- Convenience: we forego the need to implement custom code to interface with Azure OpenAI’s APIs
- End-users: Analysts can use these functions in their SQL queries when working with Databricks SQL and their BI tools of choice
- Notebook developers: can use these functions in SQL cells and spark.sql() commands
We first create a function to handle our prompts. We’ve stored the Azure OpenAI API key in a Databricks Secret, and reference it with the SECRET() function. We also pass it the Azure OpenAI resource name (resourceName) and the model’s deployment name (deploymentName). We also have the ability to set the model’s temperature, which controls the level of randomness and creativity in the generated output. We explicitly set the temperature to 0 to minimise randomness and maximise repeatability
-- Wrapper function to handle all our calls to Azure OpenAI
-- Analysts who want to use arbitrary prompts can use this handler
CREATE OR REPLACE FUNCTION PROMPT_HANDLER(prompt STRING)
RETURNS STRING
RETURN AI_GENERATE_TEXT(prompt,
"azure_openai/gpt-35-turbo",
"apiKey", SECRET("tokens", "azure-openai"),
"temperature", CAST(0.0 AS DOUBLE),
"deploymentName", "llmbricks",
"apiVersion", "2023-03-15-preview",
"resourceName", "llmbricks"
);Now we create our first function to annotate our review with entities (i.e. topics discussed), entity sentiments, whether a follow-up is required and why. Since the prompt will return a well-formed JSON representation, we can instruct the function to return a STRUCT type that can easily be inserted into a Delta table
-- Extracts entities, entity sentiment, and whether follow-up is required from a customer review
-- Since we're receiving a well-formed JSON, we can parse it and return a STRUCT data type for easier querying downstream
CREATE OR REPLACE FUNCTION ANNOTATE_REVIEW(review STRING)
RETURNS STRUCT<entities: ARRAY<STRUCT<entity_name: STRING, entity_type: STRING, entity_sentiment: STRING, followup: STRING, followup_reason: STRING>>>
RETURN FROM_JSON(
PROMPT_HANDLER(CONCAT(
'A customer left a review. We follow up with anyone who appears unhappy.
Extract all entities mentioned. For each entity:
- classify sentiment as ["POSITIVE","NEUTRAL","NEGATIVE"]
- whether customer requires a follow-up: Y or N
- reason for requiring followup
Return JSON ONLY. No other text outside the JSON. JSON format:
{
entities: [{
"entity_name": <entity name>,
"entity_type": <entity type>,
"entity_sentiment": <entity sentiment>,
"followup": <Y or N for follow up>,
"followup_reason": <reason for followup>
}]
}
Review:
', review)),
"STRUCT<entities: ARRAY<STRUCT<entity_name: STRING, entity_type: STRING, entity_sentiment: STRING, followup: STRING, followup_reason: STRING>>>"
);We create a similar function for generating a response to complaints, including recommending alternative products to try
-- Generate a response to a customer based on their complaint
CREATE OR REPLACE FUNCTION GENERATE_RESPONSE(product STRING, entity STRING, reason STRING)
RETURNS STRING
COMMENT "Generate a response to a customer based on their complaint"
RETURN PROMPT_HANDLER(
CONCAT("A customer of ours was unhappy about ", product,
"specifically about ", entity, " due to ", reason, ". Provide an empathetic
message I can send to my customer including the offer to have a call with
the relevant product manager to leave feedback. I want to win back their
favour and I do not want the customer to churn"));We could wrap up all the above logic into a single prompt to minimise API calls and latency. However, we recommend decomposing your questions into granular SQL functions so that they can be reused for other scenarios within your organisation.
Analysing customer review data
Now let’s put our functions to the test!
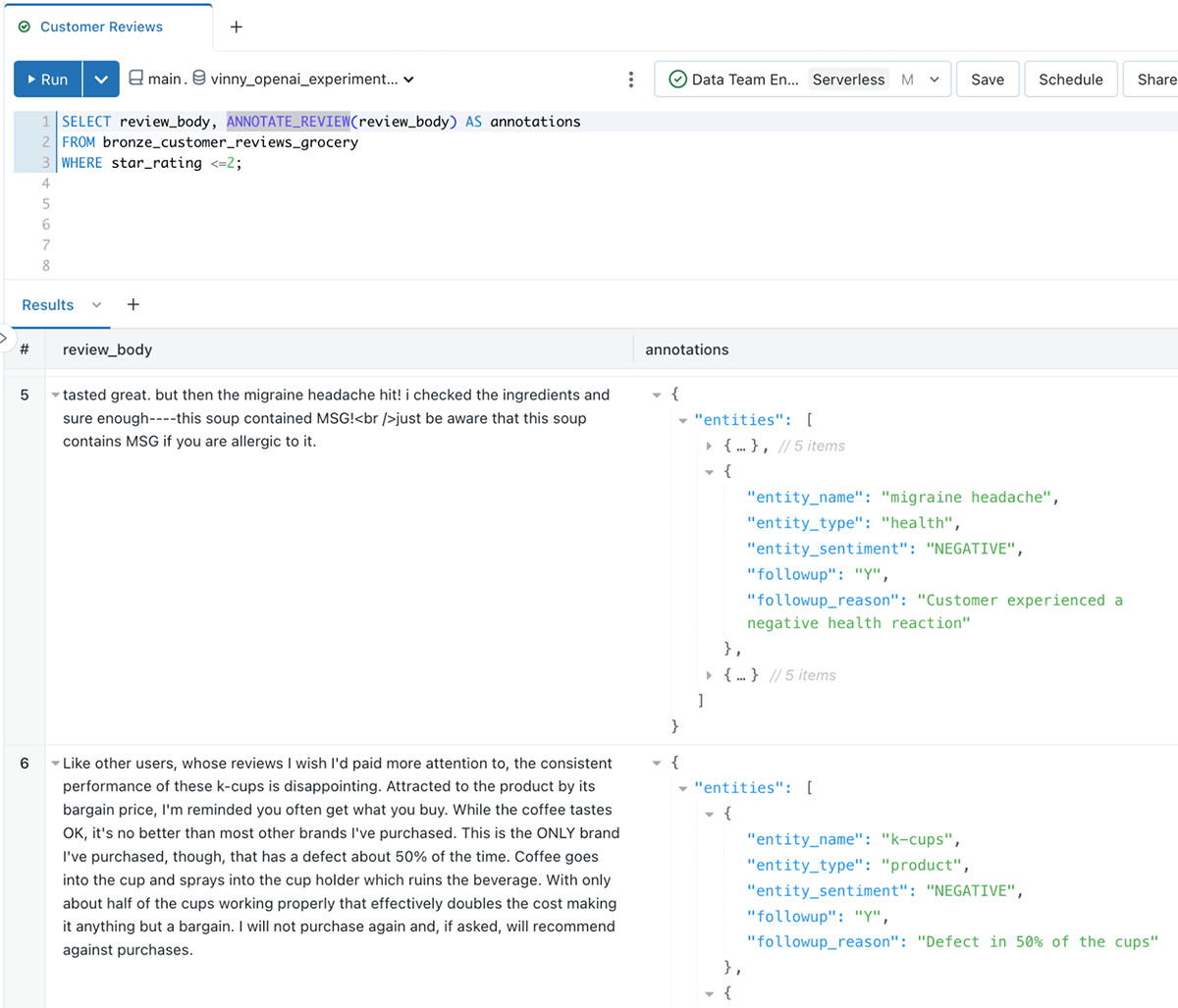
SELECT review_body, ANNOTATE_REVIEW(review_body) AS annotations
FROM customer_reviewsThe LLM function returns well-structured data that we can now easily query!
Next we’ll structure the data in a format that is more easily queried by BI tools:
CREATE OR REPLACE TABLE silver_reviews_processed
AS
WITH exploded AS (
SELECT * EXCEPT(annotations),
EXPLODE(annotations.entities) AS entity_details
FROM silver_reviews_annotated
)
SELECT * EXCEPT(entity_details),
entity_details.entity_name AS entity_name,
LOWER(entity_details.entity_type) AS entity_type,
entity_details.entity_sentiment AS entity_sentiment,
entity_details.followup AS followup_required,
entity_details.followup_reason AS followup_reason
FROM explodedNow we have multiple rows per review, with each row representing the analysis of an entity (topic) discussed in the text
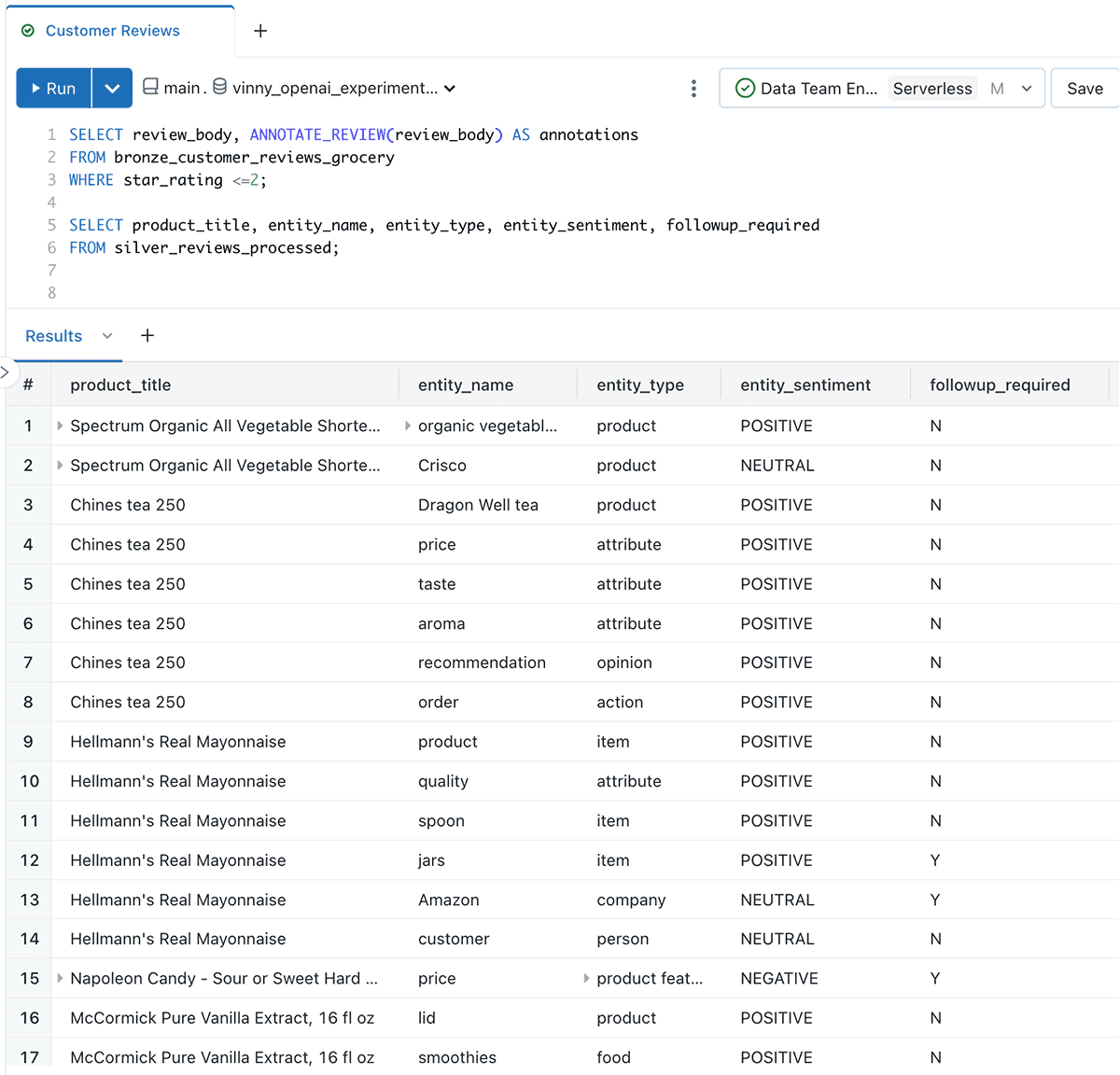
Creating response messages for our customer success team
Let’s now create a dataset for our customer success team where they can identify who requires a response, the reason for the response, and even a sample message to start them off
-- Generate a response to a customer based on their complaint
CREATE OR REPLACE TABLE gold_customer_followups_required
AS
SELECT *, GENERATE_RESPONSE(product_title, entity_name, followup_reason) AS followup_response
FROM silver_reviews_processed
WHERE followup_required = "Y"The resulting data looks like
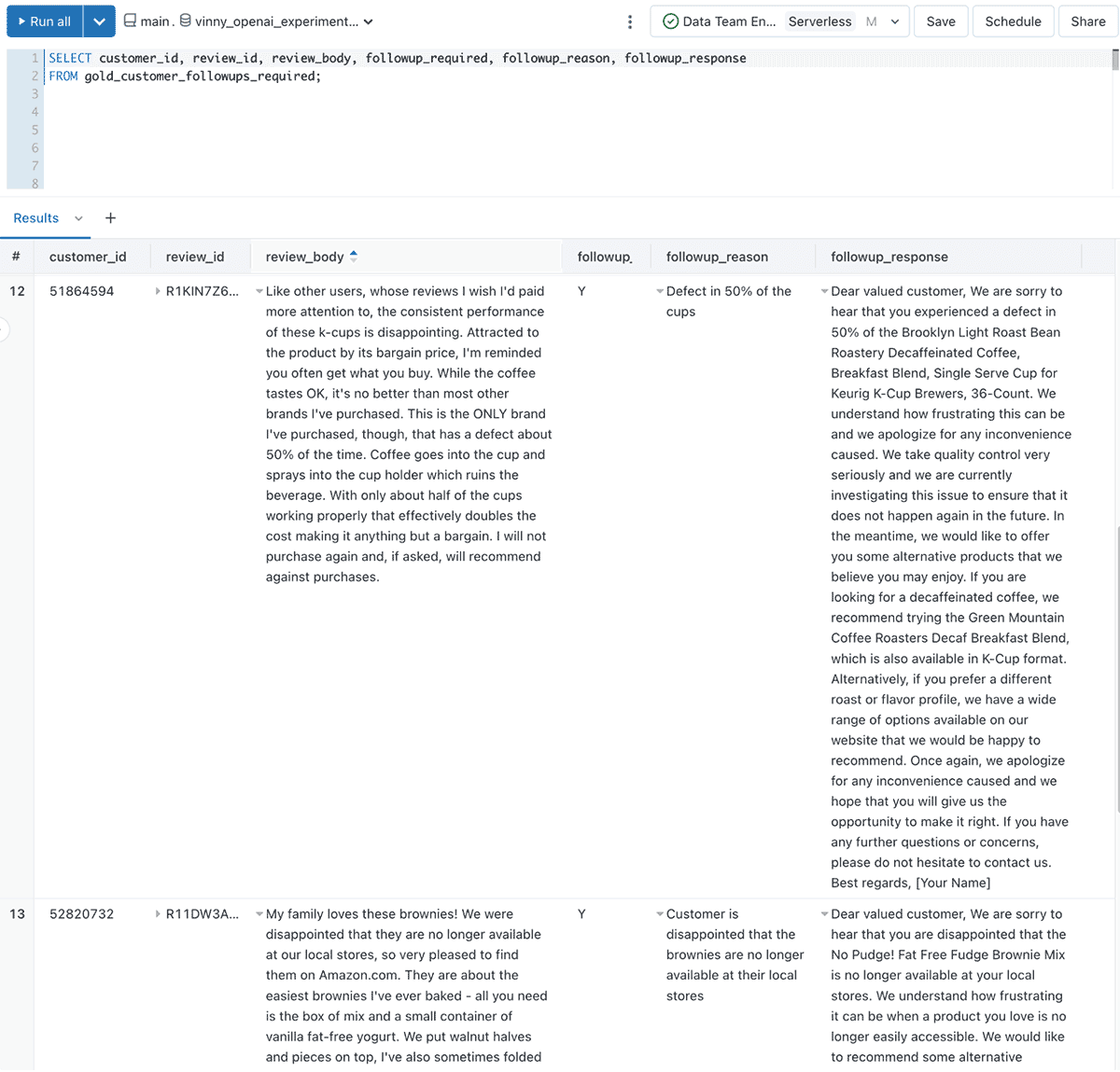
As customer reviews and feedback stream into the Lakehouse, Susan and her team foregoes the labour-intensive and error-prone task of manually assessing each piece of feedback. Instead, they now spend more time on the high-value task of delighting their customers!
Supporting ad-hoc queries
Analysts can also create ad-hoc queries using the PROMPT_HANDLER() function we created before. For example, an analyst might be interested in understanding whether a review discusses beverages:
SELECT review_id,
PROMPT_HANDLER(CONCAT("Does this review discuss beverages?
Answer Y or N only, no explanations or notes. Review: ", review_body))
AS discusses_beverages,
review_body
FROM gold_customer_reviews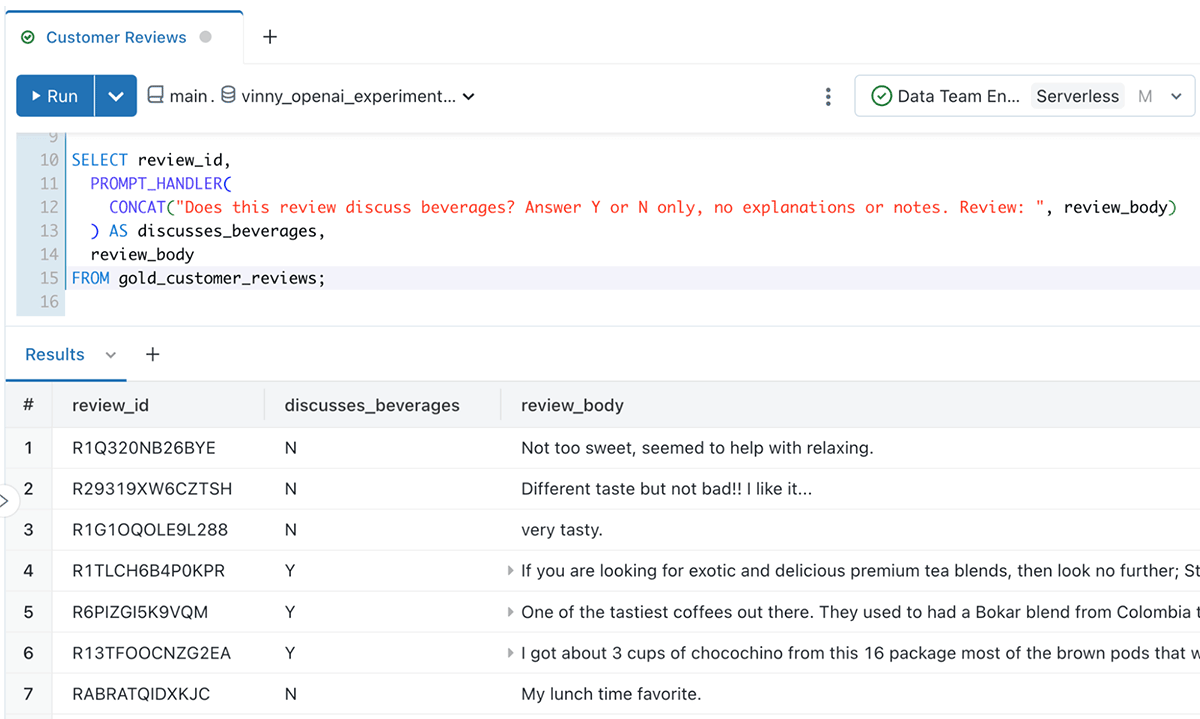
From unstructured data to analysed data in minutes!
Now when Susan arrives at work in the morning, she’s greeted with a dashboard that points her to which customers she should be spending time with and why. She’s even provided with starter messages to build upon!
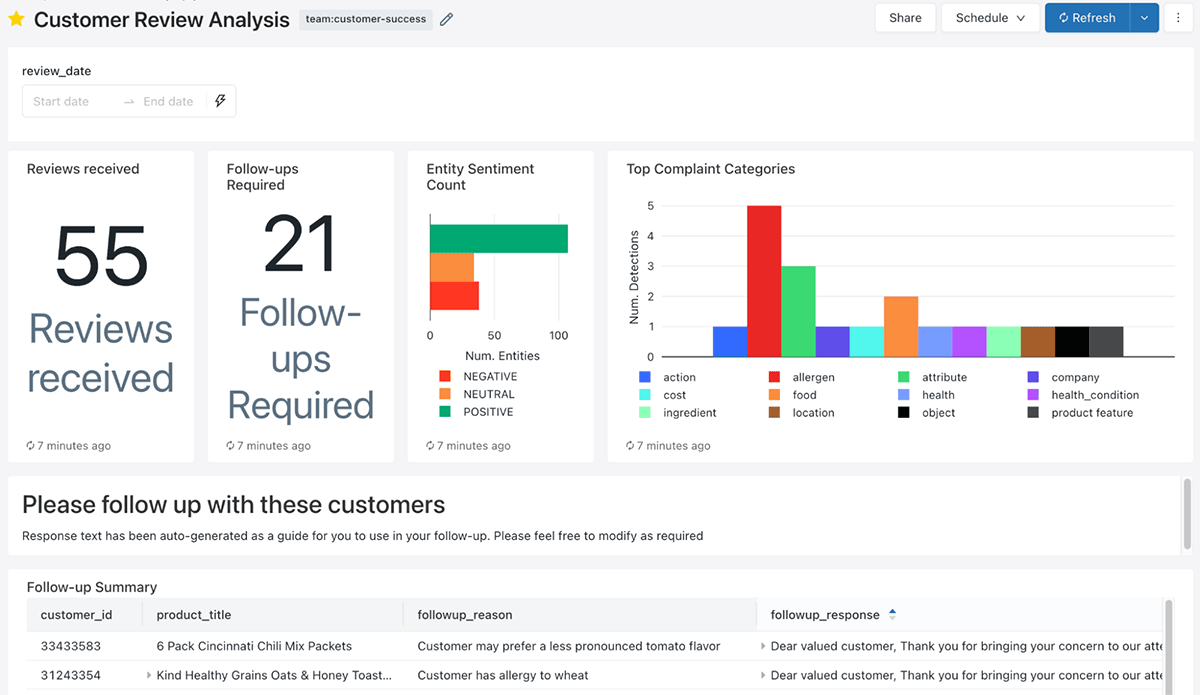
To many of Susan’s colleagues, this seems like magic! Every magic trick has a secret, and the secret here is AI_GENERATE_TEXT() and how easy it makes applying LLMs to your Lakehouse. The Lakehouse has been working behind the scenes to centralise reviews from multiple data sources, assigning meaning to the data, and recommending next best actions
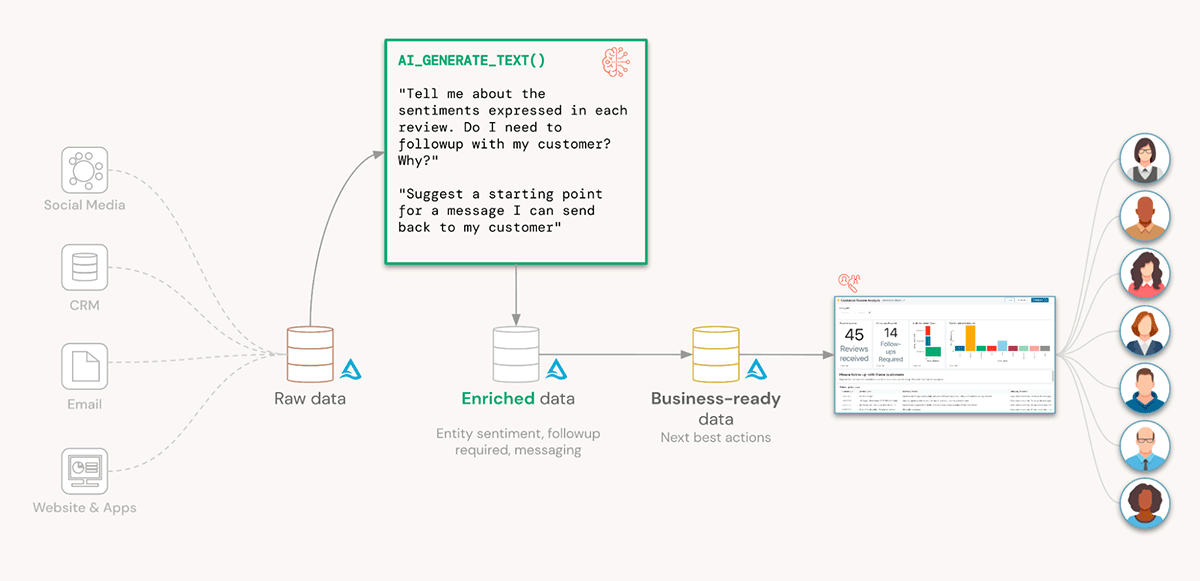
Let’s recap the key benefits for Susan’s business:
- They are immediately able to apply AI to their data without the weeks required to train, build, and operationalise a model
- Analysts and developers can interact with this model through using familiar SQL skills
You can apply these SQL functions to the entirety of your Lakehouse such as:
- Classifying data in real-time with Delta Live Tables
- Build and distribute real-time SQL Alerts to warn on increased negative sentiment activity for a brand
- Capturing product sentiment in Feature Store tables that back their real-time serving models
Areas for consideration
While this workflow brings immediate value to our data without the need to train and maintain our own models, we need to be cognizant of a few things:
- The key to an accurate response from an LLM is a well-constructed and detailed prompt. For example, sometimes the ordering of your rules and statements matters. Ensure you periodically fine-tune your prompts. You may spend more time engineering your prompts than writing your SQL logic!
- LLM responses can be non-deterministic. Setting the temperature to 0 will make the responses more deterministic, but it’s never a guarantee. Therefore, if you are reprocessing data, the output for previously processed data could differ. You can use Delta Lake’s time travel and change data feed features to identify altered responses and address them accordingly
- In addition to integrating LLM services, Databricks also makes it easy to build and operationalise LLMs that you own and are fine-tuned on your data. For example, learn how we built Dolly. You can use these in conjunction with AI Functions to create insights truly unique to your business
What next?
Every day the community is showcasing new creative uses of prompts. What creative uses can you apply to the data in your Databricks Lakehouse?
- Sign up for the Public Preview of AI Functions here
- Read the docs here
- Follow along with our demo at dbdemos.ai
- Check out our Webinar covering how to build your own LLM like Dolly here!


