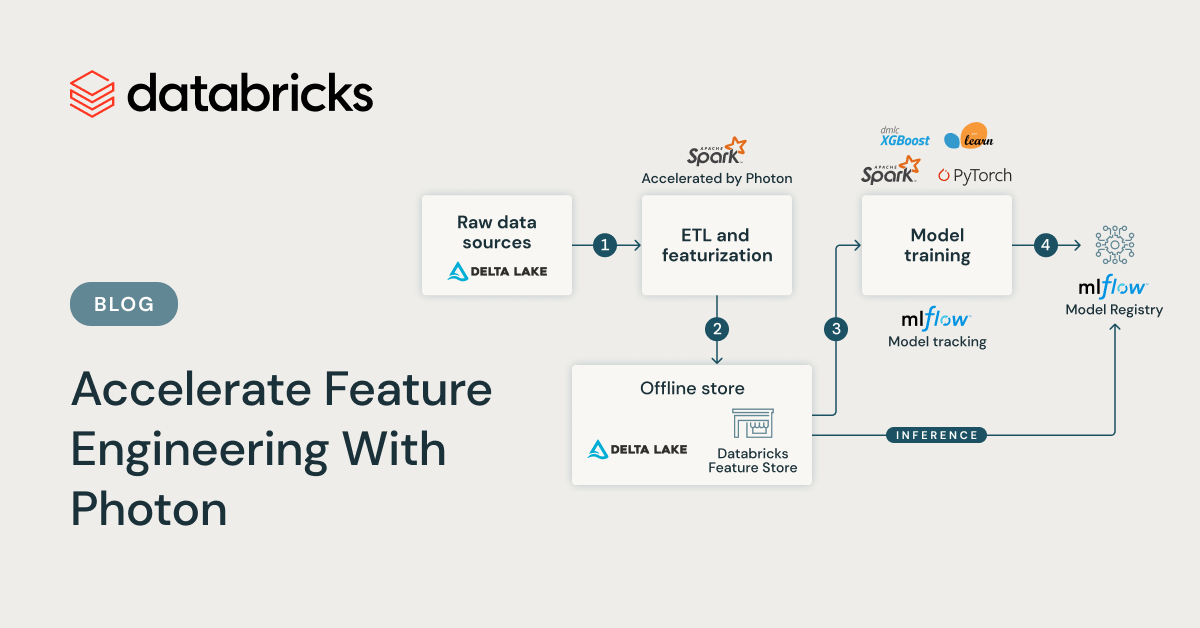
Training a high-quality machine learning model requires careful data and feature preparation. To fully utilize raw data stored as tables in Databricks, running ETL pipelines and feature engineering may be required to transform the raw data into helpful feature tables. If your table is large, this step could be very time-consuming. We are excited to announce that the Photon Engine can now be enabled in Databricks Machine Learning Runtime, capable of speeding up spark jobs and feature engineering workloads by 2x or more.
“By enabling Photon and using a new PIT join, the time required to generate the training dataset using our Feature Store was reduced by more than 20 times.” – Sem Sinchenko, Advanced Analytics Expert Data Engineer, Raiffeisen Bank International AG
What is Photon?
The Photon Engine is a high-performance query engine that can run Spark SQL and Spark DataFrame faster, reducing the total cost per workload. Under the hood, Photon is implemented with C++, and specific Spark execution units are replaced with Photon’s native engine implementation.
How does Photon help machine learning workloads?
Now that Photon can be enabled in Databricks Machine Learning Runtime, when does it make sense to integrate a Photon-enabled cluster for machine learning development workflows? Here are some of the main considerations:
- Faster ETL: Photon speeds up Spark SQL and Spark DataFrame workloads for data preparation. Early customers of Photon have observed an average speedup of 2x-4x for their SQL queries.
- Faster feature engineering: When using the Databricks Feature Engineering Python API for time series feature tables, point-in-time join becomes faster when Photon is enabled.
Faster feature engineering with Photon
The Databricks Feature Engineering library has implemented a new version of point-in-time join for time series data. The new implementation, which was inspired by a suggestion from Semyon Sinchenko of Databricks customer Raiffeisen Bank International, uses native Spark instead of the Tempo library, making it more scalable and robust than the previous version. Moreover, the native Spark implementation hugely benefits from the Photon Engine. The larger the tables, the more improvements Photon can bring.
- When joining a feature table of 10M rows (10k unique IDs, with 1000 timestamps per ID) with a label table (100k unique IDs, with 100 timestamps per ID), Photon speeds up the point-in-time join by 2.0x
- When joining a feature table of 100M rows (100k unique IDs), Photon speeds up the point-in-time join by 2.1x
- When joining a feature table of 1B rows (1M unique IDs), Photon speeds up the point-in-time join by 2.4x

The figure above compares the run time of joining feature tables of 3 different sizes with the same label table. Each experiment was performed on a Databricks AWS cluster with an r6id.xlarge instance type and one worker node. The setup was repeated five times to calculate the average run time.
Select Photon in Databricks Machine Learning Runtime cluster
The query performance of Photon and the pre-built AI infrastructure of Databricks ML Runtime make it faster and easier to build machine learning models. Starting from Databricks Machine Learning Runtime 15.2 and above, users can create an ML Runtime cluster with Photon by selecting “Use Photon Acceleration”. Meanwhile, the native Spark version of point-in-time join comes with ML Runtime 15.4 LTS and above.

To learn more about Photon and feature engineering with Databricks, consult the following documentation pages for more information.


