On eBay, there are lots of scenarios that require a distributed system. A typical use case is when a large amount of libraries are release. There are more than 3,000 legacy libraries still built by the old build system based on Ant, which is no longer supported. These libraries are now being migrated to a mavenized source code following standard maven development experience. After code migration, a new release solution is needed to support the periodical release of all libraries, which needs to be lightweight, scalable, stable and fast. To achieve this, the following challenges should be resolved.
Challenges
The prerequisite of one library release is that all the dependencies of it must have been released already, but considering the large number of candidate libraries and the complicated dependency relationships in each other, it will cause a considerable impact on release performance if the libraries release sequence cannot be orchestrated well.
At eBay, Jenkins is the standard CI/CD tool to perform maven releases. To make the libraries release more in parallel, multiple Jenkins nodes will get involved. The challenge is to find the optimal Jenkins nodes to stably release more than 3,000 libraries in efficiency and maintain the nodes for a long term usage. So the capability of the release system should be:
- Able to provide maximized in parallel capability to do release based on dependency relationship between libraries;
- Lightweight and easy to set up, scale and maintain; and
- Stable and fault-tolerant to make the whole release process smoothly.
Solution
Prioritize libraries by dependency
As a maven library, it’s easy to get dependency relationships by analyzing the dependencies defined in pom.xml. If one library can figure out a “dependency tree” to identify the relationship then for the large number of libraries, there will be a heavy DAG (directed acyclic graph) to identify the complicated relationships between them. The following is a sample DAG that reflects the libraries relationship and each cycle represents one single library.
One library can be released if all its dependencies (child nodes) have been released. So in the diagram above numbers two, three and four can be released in parallel after number one is released. And the nodes with blue color can be released separately since it is not dependent on other branches.
The central service of the distributed release system calculates the DAG and analyzes the relationship, then sets all the nodes which can be released in parallel with the same priority and puts all of them into a queue. Then the priority decides the release sequence, so the leaf node (number one) will be the first priority which must be released first and parent nodes (numbers two, three and four) will be released secondary.
Priority Tuning
For libraries that can be released in parallel, it is not the best way to release them randomly even though it looks like they are in the same priority and ready to be released, because some nodes may slow down the whole release process. The following diagram shows the case.
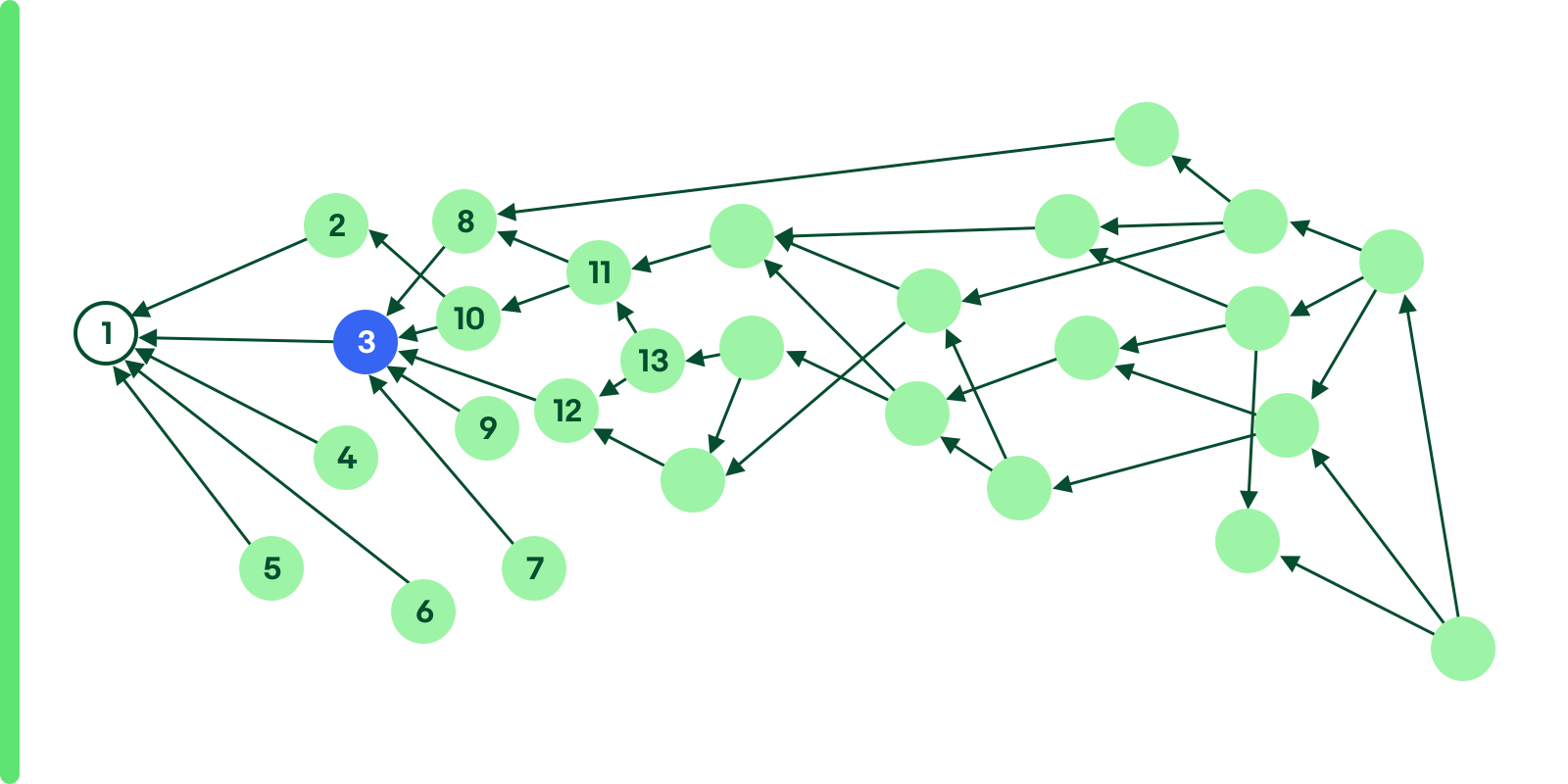
From the DAG, after node number one was released, then the parent nodes from numbers two to six can be released in parallel. In those release candidates, only node number three is dependent on other nodes. If these nodes are released by random sequence, and there are three Jenkins nodes to do the release work, it’s possible that the node number three is the last one to be released. In this scenario, the other two Jenkins nodes have to wait for the node number three to be released since from DAG, there are no other available nodes to be released until number three was released. So node number three is the key node and needs to be tuned with higher priority than the nodes numbers two through six. After number three is released first, the nodes from numbers seven to 10 can be added into the priority queue as release candidates. All of the Jenkins nodes will work with full capacity instead of being idle to wait for release candidates.
So the priority setting will follow this principle: In the nodes that can be released in parallel, the node with more parent nodes will have higher priority, and will be released first.
After all libraries are set into the release queue by priority, the central service can leverage Jenkins to perform the release.
Optimize Concurrency with Jenkins
Push Mode
An easy way to leverage Jenkins to perform the release is through the central service, which selects nodes (libraries) with the same priority from the release queue, and then triggers one Jenkins job for each node for release.
It can be called ‘push mode’. If there are more than 100 libraries with the same priority, to maximize the parallel capability, it will trigger/push almost the same amount of Jenkins jobs from multiple Jenkins servers for release. The following diagram shows this architecture.
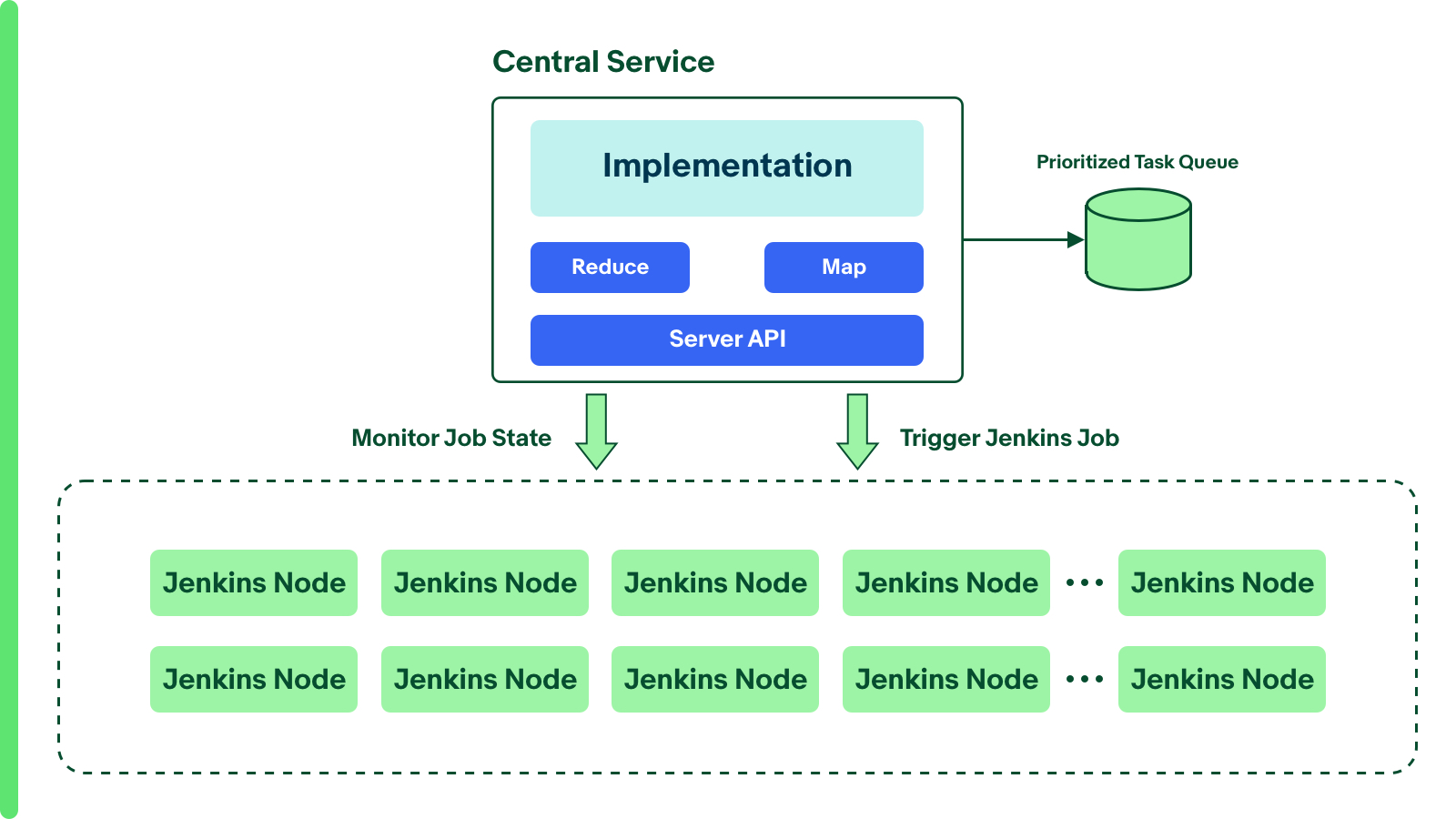
The architecture has two potential problems.
- The release system depends on lots of live Jenkins nodes before each round of release. In the release process, all of Jenkins nodes need to be well monitored about release status. Its error prone and will be huge efforts for maintenance and troubleshooting each Jenkins node for network/performance issues.
- Each library release will trigger corresponding scheduled Jenkins jobs asynchronously. It may take more time to wait for job execution than to do the release work. Considering the big numbers of libraries in the release phase, the release process will take a long time (several days) to complete.
- The maven dependencies need to be downloaded on each Jenkins node repetitively, and cannot be shared by different nodes.
So to speed up the release process and make it more lightweight and stable, the pull mode has been figured out.
Pull Mode
Since Jenkins supports Groovy well, it’s easy to use Groovy to implement some advanced features at Jenkins side. Each Jenkins job works as a pipeline with a Groovy script.Once the release starts (release queue has been filled by priority), the Jenkins nodes should be in the loop of pulling the candidate library by calling central service and releasing it then reporting results and pulling the next one until all libraries release. So the final architecture shows below.
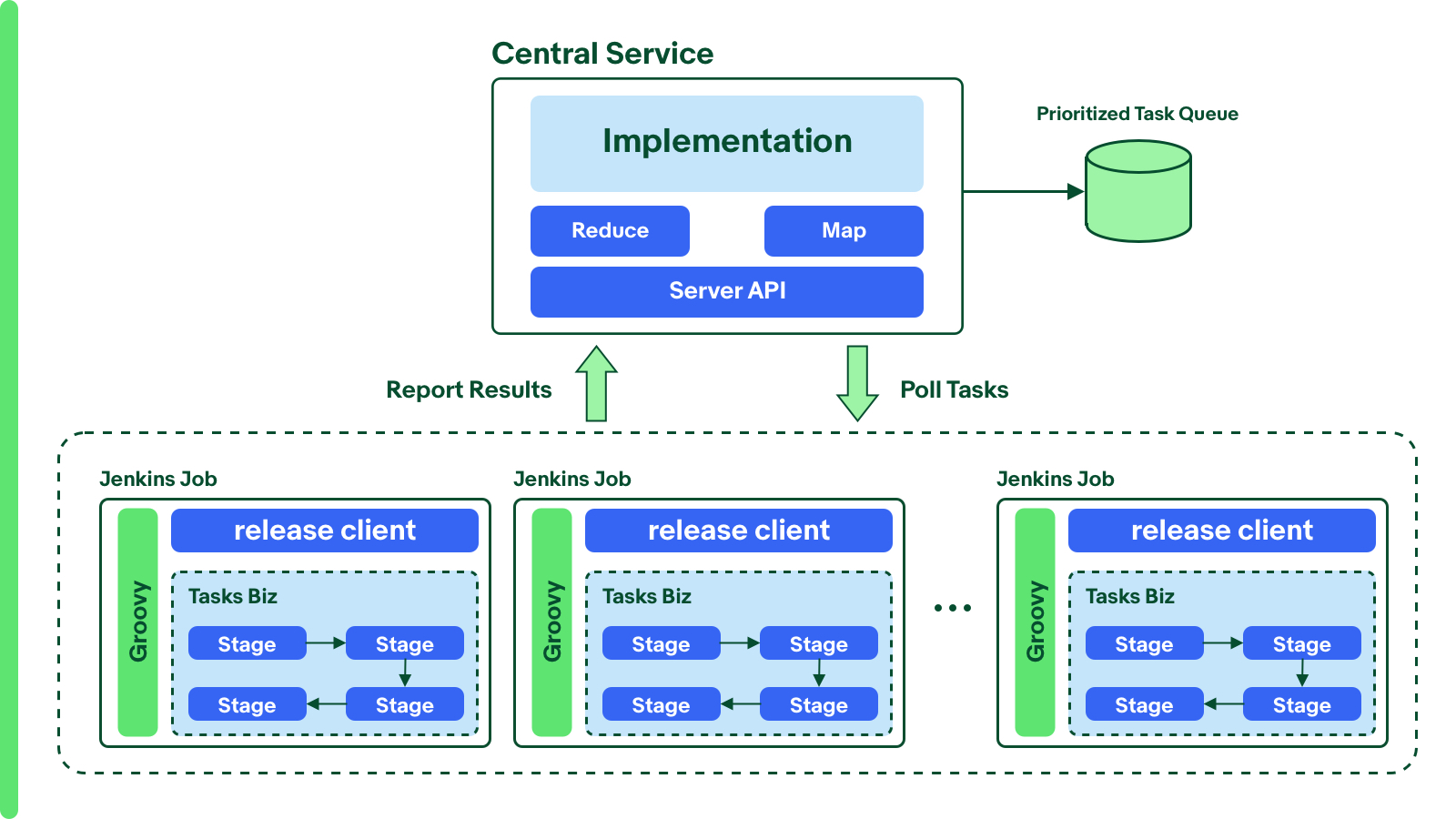
The benefits of this architecture are obvious.
- Single Jenkins node’s resources will be maximized utilization. Single Jenkins node work constantly, it avoids the time-consuming for Jenkins job scheduling and all the downloaded dependencies reside on the same node can be shared between different libraries.
- There’s no need to reserve a large number of Jenkins nodes because only one node with 20 Jenkins jobs can handle the whole release. It’s easy to set up and maintain.
Now the pull mode only takes about two hours to complete more than 3,000 library releases, which is a significant improvement given that the push mode takes 2-3 days to complete.
With the benefits and performance improvement above, the release system uses the pull mode to manage Jenkins nodes to handle all libraries release.
Summary
The lightweight distributed architecture provides a successful solution for the thousands of libraries released in eBay, which already benefits legacy libraries migration.
The central service works with a small number of Jenkins nodes in pull mode that provides a fast, scalable, stable and maintainable solution. Moreover, the distributed architecture is not limited to releasing tasks. It is a generic architecture and can be easily applied to cases where lots of subtasks are mapped to several workers to execute and summarize results once all are completed.
Below are two applicable cases that are very common in daily work.
- Distributed integration test cases running, generated summarized results once all tests run completely.
- Data collection/analysis from different channels simultaneously and generate reports.
With this architecture, it’s easy to set up the central service and workers (Jenkins nodes) to handle them with high efficiency.