
We are thrilled to announce that materialized views and streaming tables are now publicly available in Databricks SQL on AWS and Azure. Streaming tables provide incremental ingest from cloud storage and message queues. Materialized views are automatically and incrementally updated as new data arrives. Together, these two capabilities enable infrastructure-free data pipelines that are simple to set up and deliver fresh data to the business. In this blog post, we will explore how these new capabilities empower analysts and analytics engineers to deliver data and analytics applications more effectively in the data warehouse.
Background
Data warehousing and data engineering are crucial for any data-driven organization. Data warehouses serve as the primary location for analytics and reporting, while data engineering involves creating data pipelines to ingest and transform data.
However, traditional data warehouses are not designed for streaming ingestion and transformation. Ingesting large volumes of data with low latency in a traditional data warehouse is expensive and complex because legacy data warehouses were designed for batch processing. As a result, teams have had to implement clumsy solutions that required configurations outside of the warehouse and needed to use cloud storage as an intermediate staging location. Managing these systems is costly, prone to errors, and complex to maintain.
The Databricks Lakehouse Platform disrupts this traditional paradigm by providing a unified solution. Delta Live Tables (DLT) is the best place to do data engineering and streaming, and Databricks SQL provides up to 12x better price/performance for analytics workloads on existing data lakes.
Additionally, now partners like dbt can integrate with these native capabilities which we describe in more detail later in this announcement.
Common challenges faced by data warehouse users
Data warehouses serve as the primary location for analytics and data delivery for internal reporting through business intelligence (BI) applications. Organizations face several challenges in adopting data warehouses:
- Self-service: SQL analysts often face the challenge of being dependent on other resources and tools to fix data issues, slowing down the pace at which business needs can be addressed.
- Slow BI dashboards: BI dashboards built with large volumes of data tend to return results slowly, hindering interactivity and usability when answering various questions.
- Stale data: BI dashboards often present stale data, such as yesterday’s data, due to ETL jobs running only at night.
Use SQL to ingest and transform data without 3rd party tools
Streaming tables and materialized views empower SQL analysts with data engineering best practices. Consider an example of continuously ingesting newly arrived files from an S3 location and preparing a simple reporting table. With Databricks SQL the analyst can quickly discover and preview the files in S3 and set up a simple ETL pipeline in minutes, using only a few lines of code as in the following example:
1- Discover and preview data in S3
/* Discover your data in an External Location */
LIST "s3://mybucket/analysis"
/* Preview your data */
SELECT * FROM read_files("s3://mybucket/analysis")2- Ingest data in a streaming fashion
/* Continuous streaming ingest at scale */
CREATE STREAMING TABLE my_bronze_table
SCHEDULE CRON ‘0 0 * ? * * *’
AS
SELECT id,event_id FROM STREAM read_files('s3://mybucket/analysis')3- Aggregate data incrementally using a materialized view
/* Create a Silver aggregate table */
CREATE MATERIALIZED VIEW my_silver_table
SCHEDULE CRON ‘0 0 * ? * * *’
AS
SELECT count(distinct event_id) as event_count from my_bronze_table;What are materialized views?
Materialized views reduce cost and improve query latency by pre-computing slow queries and frequently used computations. In a data engineering context, they are used for transforming data. But they are also valuable for analyst teams in a data warehousing context because they can be used to (1) speed up end-user queries and BI dashboards, and (2) securely share data. Built on top of Delta Live Tables, MVs reduce query latency by pre-computing otherwise slow queries and frequently used computations.
Benefits of materialized views:
- Accelerate BI dashboards. Because MVs precompute data, end users’ queries are much faster because they don’t have to re-process the data by querying the base tables directly.
- Reduce data processing costs. MVs results are refreshed incrementally avoiding the need to completely rebuild the view when new data arrives.
- Improve data access control for secure sharing. More tightly govern what data can be seen by consumers by controlling access to base tables.
What are streaming tables?
Ingestion in DBSQL is accomplished with streaming tables (STs). You can think of STs as ideal for bringing data into “bronze” tables. STs enable continuous, scalable ingestion from any data source including cloud storage, message buses (EventHub, Apache Kafka) and more.
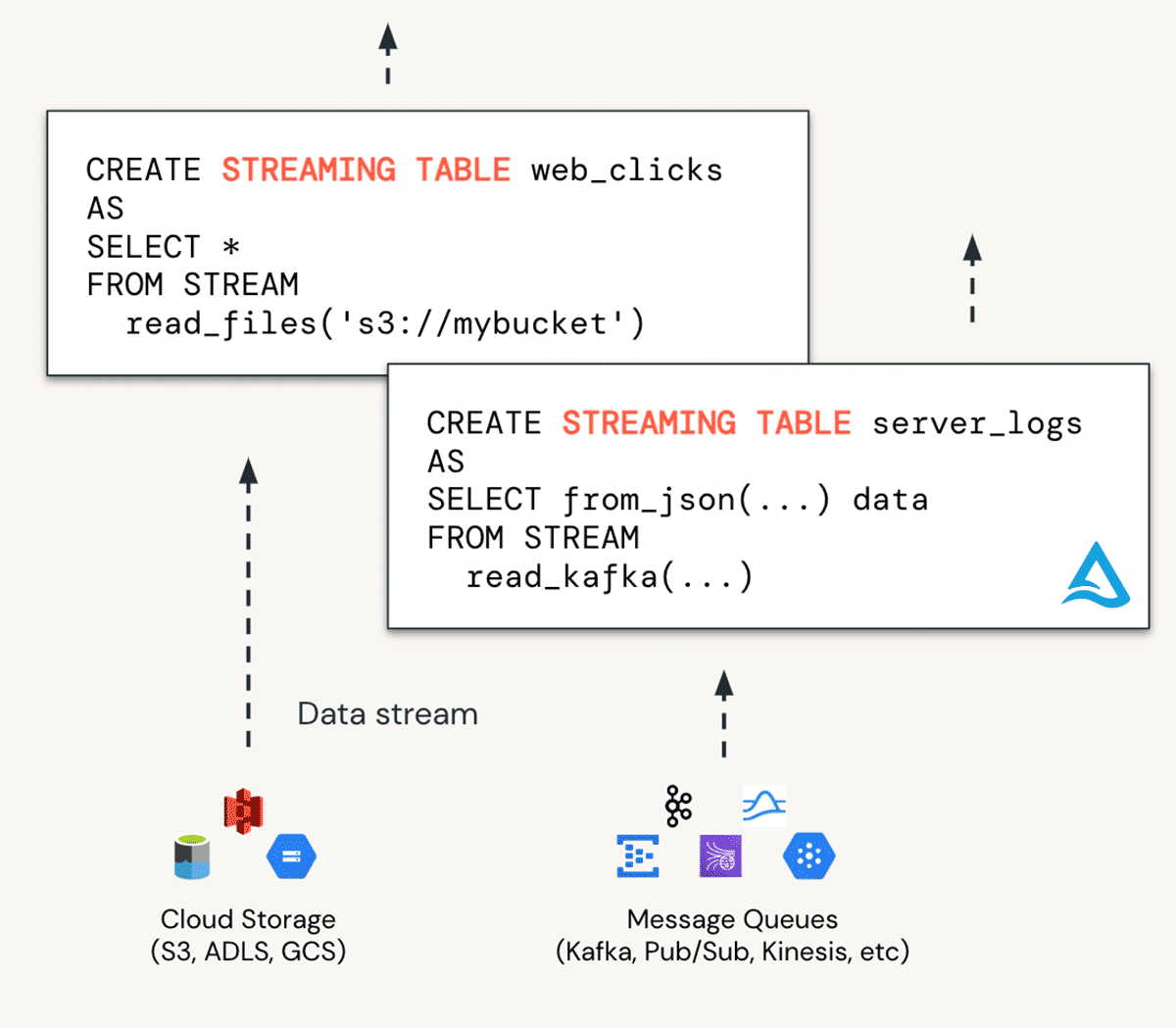
Benefits of streaming tables:
- Unlock real-time use cases. Ability to support real-time analytics/BI, machine learning, and operational use cases with streaming data.
- Better scalability. More efficiently handle high volumes of data via incremental processing vs large batches.
- Enable more practitioners. Simple SQL syntax makes data streaming accessible to all data engineers and analysts.
Customer story: how Adobe and Danske Spil accelerate dashboard queries with materialized views
Databricks SQL empowers SQL and data analysts to easily ingest, clean, and enrich data to meet the needs of the business without relying on third-party tools. Everything can be done entirely in SQL, streamlining the workflow.
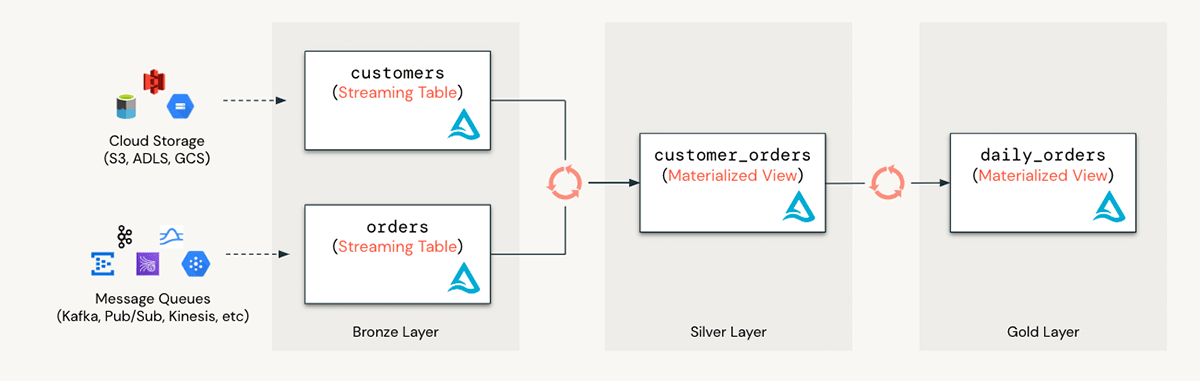
By leveraging materialized views and streaming tables, you can:
- Empower your analysts: SQL and data analysts can easily ingest, clean, and enrich data to quickly meet the needs of your business. Because everything can be done entirely in SQL, no 3rd party tools are needed.
- Speed up BI dashboards: Create MV’s to accelerate SQL analytics and BI reports by pre-computing results ahead of time.
- Move to real-time analytics: Combine MV’s with streaming tables to create incremental data pipelines for real-time use cases. You can set up streaming data pipelines to do ingestion and transformation directly in the Databricks SQL warehouse.

Adobe has an advanced approach to AI, with a mission of making the world more creative, productive, and personalized with artificial intelligence as a co-pilot that amplifies human ingenuity. As a leading preview customer of Materialized Views on Databricks SQL, they have seen enormous technical and business benefits that help them deliver on this mission:
“The conversion to Materialized Views has resulted in a drastic improvement in query performance, with the execution time decreasing from 8 minutes to just 3 seconds. This enables our team to work more efficiently and make quicker decisions based on the insights gained from the data. Plus, the added cost savings have really helped.”
— Karthik Venkatesan, Security Software Engineering Sr. Manager, Adobe

Founded in 1948, Danske Spil is Denmark’s national lottery and was one of our early preview customers for DB SQL Materialized Views. Søren Klein, Data Engineering Team Lead, shares his perspective on what makes Materialized Views so valuable for the organization:
“At Danske Spil we use Materialized Views to speed up the performance of our website tracking data. With this feature we avoid the creation of unnecessary tables and added complexity, while getting the speed of a persisted view that accelerates the end user reporting solution.”
— Søren Klein, Data Engineering Team Lead, Danske Spil
Easy streaming ingestion and transformation with dbt
Databricks and dbt Labs collaborate to simplify real-time analytics engineering on the lakehouse architecture. The combination of dbt’s highly popular analytics engineering framework with the Databricks Lakehouse Platform provides powerful capabilities:
- dbt + Streaming Tables: Streaming ingestion from any source is now built-in to dbt projects. Using SQL, analytics engineers can define and ingest cloud/streaming data directly within their dbt pipelines.
- dbt + Materialized Views: Building efficient pipelines becomes easier with dbt, leveraging Databricks’ powerful incremental refresh capabilities. Users can use dbt to build and run pipelines backed by MVs, reducing infrastructure costs with efficient, incremental computation.
Takeaways
Data warehousing and data engineering are critical components of any data-driven company. However, managing separate solutions for each aspect is costly, error-prone, and challenging to maintain. The Databricks Lakehouse Platform brings the best data engineering capabilities natively into Databricks SQL, empowering SQL users with a unified solution. Additionally, our integration with partners like dbt empowers our joint customers to leverage these unique capabilities to deliver faster insights, real-time analytics, and streamlined data engineering workflows.
Get access to Databricks SQL materialized views and streaming tables by following this link. You can also get started today with Databricks and Databricks SQL, or review the documentation for materialized views and streaming tables.


