Founded in 2017, Logically is a leader in using AI to augment clients’ intelligence capability. By processing and analyzing vast amounts of data from websites, social platforms, and other digital sources, Logically identifies potential risks, emerging threats, and critical narratives, organizing them into actionable insights that cybersecurity teams, product managers, and engagement leaders can act on swiftly and strategically.
GPU acceleration is a key component in Logically’s platform, enabling the detection of narratives to meet the requirements of highly regulated entities. By using GPUs, Logically has been able to significantly reduce training and inference times, allowing for data processing at the scale required to combat the spread of false narratives on social media and the internet more broadly. The current scarcity of GPU resources also means that optimizing their utilization is key for achieving optimal latency and the overall success of AI projects.
Logically observed their inference times increasing steadily as their data volumes grew, and therefore had a need to better understand and optimize their cluster usage. Bigger GPU clusters ran models faster but were underutilized. This observation led to the idea of taking advantage of the distribution power of Spark to perform GPU model inference in the most optimal way and to determine whether an alternate configuration was required to unlock a cluster’s full potential.
By tuning concurrent tasks per executor and pushing more tasks per GPU, Logically was able to reduce the runtime of their flagship complex models by up to 40%. This blog explores how.
The key levers used were:
1. Fractional GPU Allocation: Controlling the GPU allocation per task when Spark schedules GPU resources allows for splitting it evenly across the tasks on each executor. This allows overlapping I/O and computation for optimal GPU utilization.
The default spark configuration is one task per GPU, as presented below. This means that unless a lot of data is pushed into each task, the GPU will likely be underutilized.
By setting spark.task.resource.gpu.amount to values below 1, such as 0.5 or 0.25, Logically achieved a better distribution of each GPU across tasks. The largest improvements were seen by experimenting with this setting. By reducing the value of this configuration, more tasks can run in parallel on each GPU, allowing the inference job to finish faster.

Experimenting with this configuration is a good initial step and often has the most impact with the least tweaking. In the following configurations, we will go a bit deeper into how Spark works and the configurations we tweaked.
2. Concurrent Task Execution: Ensuring that the cluster runs more than one concurrent task per executor enables better parallelization.
In standalone mode, if spark.executor.cores is not explicitly set, each executor will use all available cores on the worker node, preventing an even distribution of GPU resources.
The spark.executor.cores setting can be set to correspond to the spark.task.resource.gpu.amount setting. For instance, spark.executor.cores=2 allows two tasks to run on each executor. Given a GPU resource splitting of spark.task.resource.gpu.amount=0.5, these two concurrent tasks would run on the same GPU.
Logically achieved optimal results by running one executor per GPU and evenly distributing the cores among the executors. For instance, a cluster with 24 cores and four GPUs would run with six cores (--conf spark.executor.cores=6) per executor. This controls the number of tasks that Spark puts on an executor at once.

3. Coalesce: Merging existing partitions into a smaller number reduces the overhead of managing a large number of partitions and allows for more data to fit into each partition. The relevance of coalesce() to GPUs revolves around data distribution and optimization for efficient GPU utilization. GPUs excel at processing large datasets due to their highly parallel architecture, which can execute many operations simultaneously. For efficient GPU utilization, we need to understand the following:
- Larger partitions of data are often better because GPUs can handle massive parallel workloads. Larger partitions also lead to better GPU memory utilization, as long as they fit into the available GPU memory. If this limit is exceeded, you may run into OOMs.
- Under-utilized GPUs (due to small partitions or small workloads, for simple reads, Spark aims for a partition size of 128MB) may lead to inefficiencies, with many GPU cores remaining idle.
In these cases, coalesce() can help by reducing the number of partitions, ensuring that each partition contains more data, which is often preferable for GPU processing. Larger data chunks per partition mean that the GPU can be better utilized, leveraging its parallel cores to process more data at once.
Coalesce combines existing partitions to create a smaller number of partitions, which can improve performance and resource utilization in certain scenarios. When possible, partitions are merged locally within an executor, avoiding a full shuffle of data across the cluster.
It is worth noting that coalesce does not guarantee balanced partitions, which may lead to skewed data distribution. In case you know that your data contains skew, then repartition() is preferred, as it performs a full shuffle that redistributes the data evenly across partitions. If repartition() works better for your use case, make sure you turn Adaprite Query Execution (AQE) off with the setting spark.conf.set("spark.databricks.optimizer.adaptive.enabled","false). AQE can dynamically coalesce partitions which may interfere with the optimal partition we are trying to achieve with this exercise.
By controlling the number of partitions, the Logically team was able to push more data into each partition. Setting the number of partitions to a multiple of the number of GPUs available resulted in better GPU utilization.
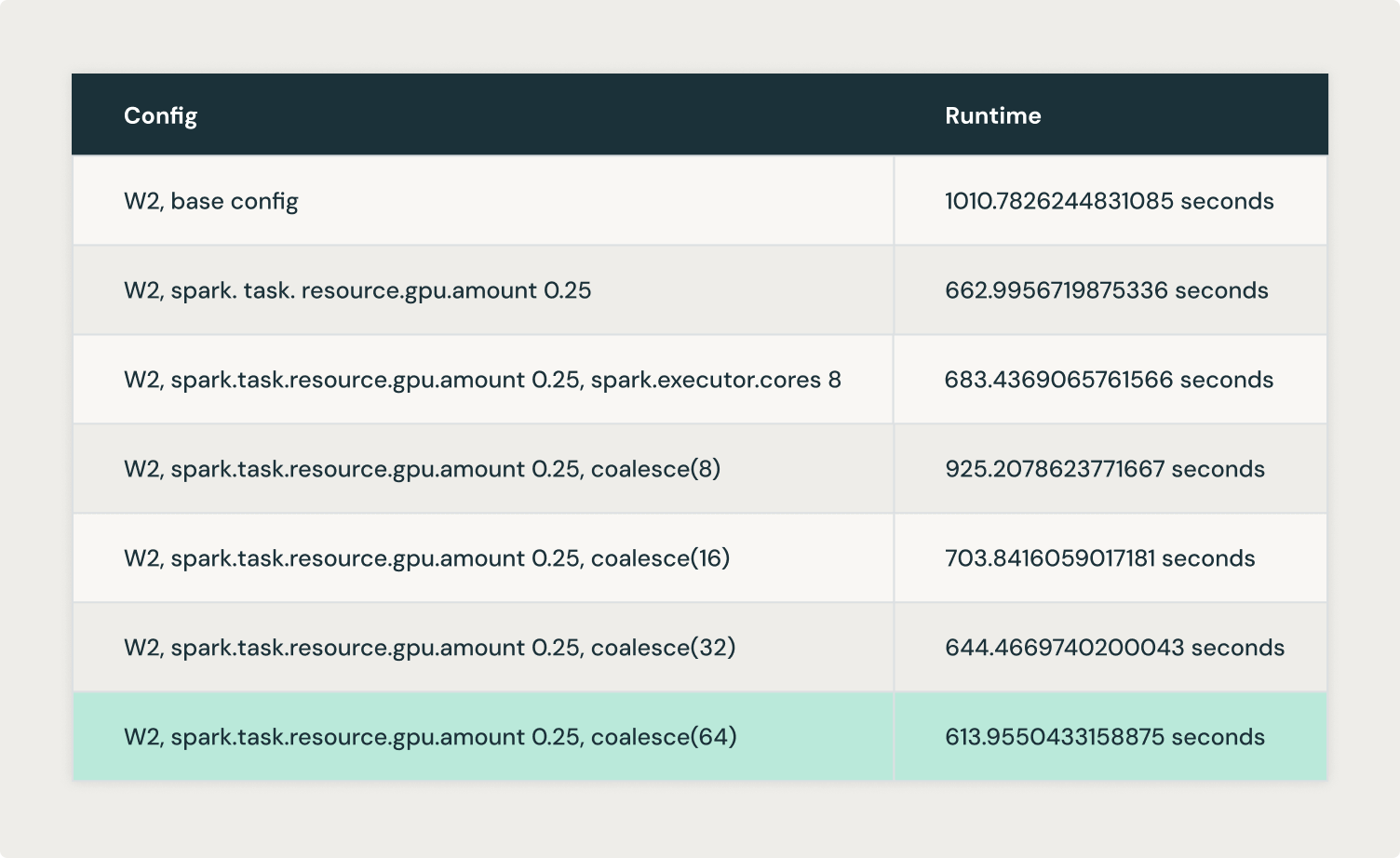
Logically experimented with coalesce(8), coalesce(16), coalesce(32) and coalesce(64) and achieved optimal results with coalesce(64).
From the above experiments, we understood that there is a balance between how big or small the partitions should be in terms of size to achieve better GPU utilization. So, we tested the maxPartitionBytes configuration, aiming to create bigger partitions from the start instead of having to create them later on with coalesce() or repartition().
maxPartitionBytes is a parameter that determines the maximum size of each partition in memory when data is read from a file. By default, this parameter is typically set to 128MB, but in our case, we set it to 512MB aiming for bigger partitions. This prevents Spark from creating excessively large partitions that could overwhelm the memory of an executor or GPU. The idea is to have manageable partition sizes that fit into available memory without causing performance degradation due to excessive disk spilling or memory errors.

These experimentations have opened the door to further optimizations across the Logically platform. This includes leveraging Ray to create distributed applications while benefiting from the breadth of the Databricks ecosystem, enhancing data processing and machine learning workflows. Ray can help maximize the parallelism of the GPU resources even further, for example through its built-in GPU auto scaling capabilities and GPU utilization monitoring. This represents an opportunity to increase value from GPU acceleration, which is key to Logically’s continued mission of protecting institutions from the spread of harmful narratives.
For more information: