
Introduction
Four months ago, we shared how AMD had emerged as a capable platform for generative AI and demonstrated how to easily and efficiently train LLMs using AMD Instinct GPUs. Today, we’re excited to share that the hits keep coming!
Community adoption of AMD GPUs has exploded: AI startups such as Lamini are using AMD MI210 and MI250 systems to finetune and deploy custom LLMs, and Moreh was able to train a 221B parameter language model on their platform using 1200 AMD MI250 GPUs. Futuremore, open-source LLMs such as AI2’s OLMo are also being trained on large clusters of AMD GPUs.
Meanwhile, at AMD, the ROCm software platform has been upgraded from version 5.4 to 5.7, and the ROCm kernel for FlashAttention has been upgraded to FlashAttention-2, delivering significant performance gains.
In parallel, AMD has been making significant contributions to the Triton compiler, enabling ML engineers to write custom kernels once that run performantly on multiple hardware platforms, including NVIDIA and AMD.
Finally, at MosaicML/Databricks, we received early access to a new multi-node MI250 cluster built as part of the AMD Accelerator Cloud (AAC). This new cluster has 32 nodes, each containing 4 x AMD Instinct™ MI250 GPUs, for a total of 128 x MI250s. With a high-bandwidth 800Gbps interconnect between nodes, the cluster is perfect for testing LLM training at scale on AMD hardware.
We’re excited to share our first multi-node training results on MI250 GPUs!
- When training LLMs on MI250 using ROCm 5.7 + FlashAttention-2, we saw 1.13x higher training performance vs. our results in June using ROCm 5.4 + FlashAttention.
- On AAC, we saw strong scaling from 166 TFLOP/s/GPU at one node (4xMI250) to 159 TFLOP/s/GPU at 32 nodes (128xMI250), when we hold the global train batch size constant.
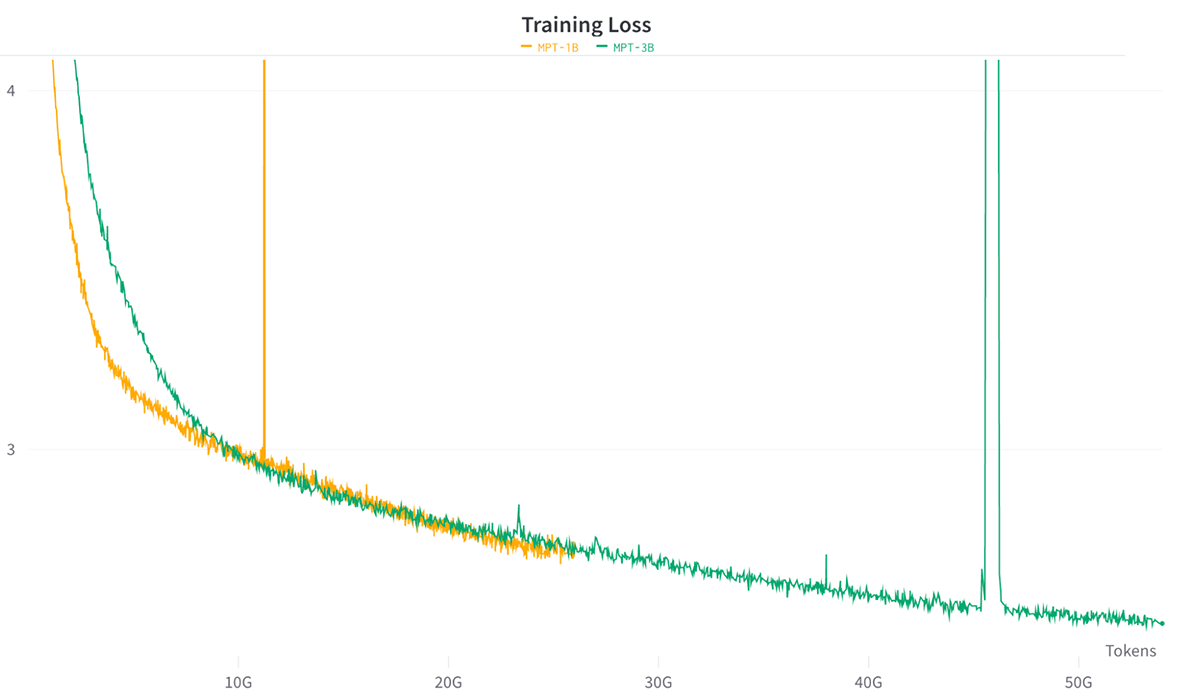
- To test convergence, we trained two MPT models with 1B and 3B params from scratch with Chinchilla-optimal token budgets, each on 64 x MI250 GPUs. We found that training was stable, and the final models had similar eval metrics to compute-matched open-source models (Cerebras-GPT-1.3B and Cerebras-GPT-2.7B).
As before, all results are measured using our open-source training library, LLM Foundry, built upon Composer, StreamingDataset, and PyTorch FSDP. Thanks to PyTorch’s support for both CUDA and ROCm, the same training stack can run on either NVIDIA or AMD GPUs with no code changes.
Looking ahead to the next-gen AMD Instinct MI300X GPUs, we expect our PyTorch-based software stack to work seamlessly and continue to scale well. We are also excited about the potential of AMD + Triton, which will make it even easier to port custom model code and kernels. For example, soon we will be able to use the same FlashAttention-2 Triton kernel on both NVIDIA and AMD systems, eliminating the need for a ROCm-specific kernel.
Read on for more details about AMD multi-node training, and ask your CSP if/when they will offer the AMD MI300X!
AMD Platform
If you aren’t familiar with the AMD platform, below is a quick overview. For a deeper dive, check out our AMD Part 1 blog.
The AMD MI250 and (future) MI300X are datacenter accelerators similar to the NVIDIA A100 and H100, with High Bandwidth Memory (HBM) and Matrix Cores that are analogous to NVIDIA’s Tensor Cores for fast matrix multiplication. When comparing GPUs within “generations”, it’s most appropriate to compare the MI250 to the A100, while the MI300X is similar to the H100. See Table 1 for details.
| AMD MI250 | NVIDIA A100-40GB | NVIDIA A100-80GB | AMD MI300X | NVIDIA H100-80GB | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Single Card | 4x MI250 | Single Card | 8x A100-40GB | Single Card | 8x A100-80GB | Single Card | 8x MI300X | Single Card | 8x H100-80GB | |
| FP16 or BF16 TFLOP/s | 362 TFLOP/s | 1448 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s | N/A | N/A | 989.5 TFLOP/s | 7916 TFLOP/s |
| HBM Memory (GB) | 128 GB | 512 GB | 40GB | 320 GB | 80GB | 640 GB | 192 GB | 1536 GB | 80GB | 640 GB |
| Memory Bandwidth | 3277 GB/s | 13.1 TB/s | 1555 GB/s | 12.4TB/s | 2039 GB/s | 16.3 TB/s | 5200 GB/s | 41.6 TB/s | 3350 GB/s | 26.8 TB/s |
| Peak Power Consumption | 560W | 3000 W | 400W | 6500 W | 400W | 6500 W | N/A | N/A | 700 W | 10200 W |
| Rack Units (RU) | N/A | 2U | N/A | 4U | N/A | 4U | N/A | N/A | N/A | 8U |
Table 1: Hardware specs for NVIDIA and AMD GPUs. Please note that only a subset of the MI300X specs have been released publicly as of Oct 2023.
On top of these accelerators, AMD has developed a collection of software and networking infrastructure:
- ROCm: A library of drivers, tools, and high-performance GPU kernels.
- RCCL: A communications library for high-performance cross-GPU operations like gather, scatter, and reduce that are used for distributed training.
- Infinity Fabric: high bandwidth networking within a node.
- Infiniband or RoCE: high bandwidth networking across nodes.
At each layer of the stack, AMD has built software libraries (ROCm, RCCL) or networking infrastructure (Infinity Fabric) or adopted existing networking infrastructure (Infiniband or RoCE) to support workloads like LLM training. If you’re familiar with NVIDIA’s platform, you’ll see that many components of AMD’s platform directly map to those of NVIDIA’s. See Figure 2 for a side-by-side comparison.
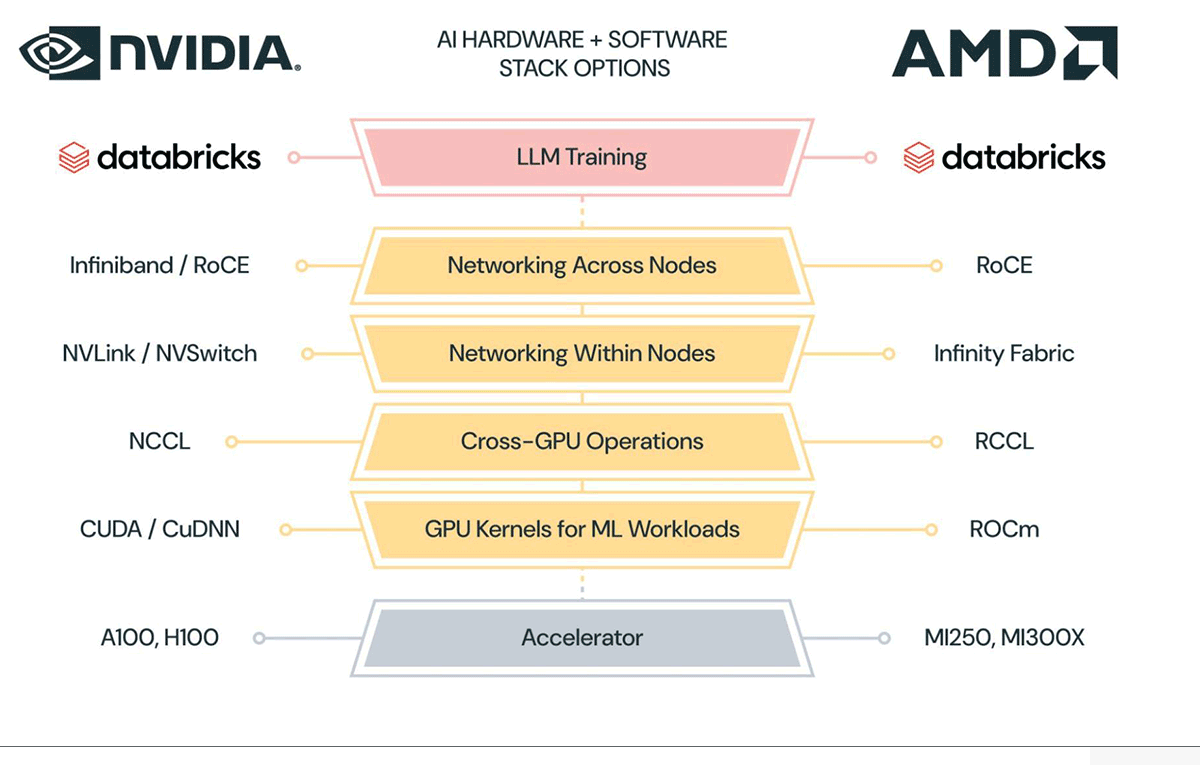
One of the most popular libraries for ML programmers is PyTorch, and as we reported in our last blog, PyTorch runs seamlessly in eager mode on AMD GPUs like MI250. Even advanced distributed training techniques like Fully-Sharded Data Parallelism (FSDP) work out of the box, so if you have a PyTorch program (like LLM Foundry) that works on NVIDIA GPUs, there is a high chance that it will also work on AMD GPUs. This is made possible by PyTorch’s internal mapping of operators like `torch.matmul(...)` to either CUDA or ROCm kernels.
Another exciting software improvement to the AMD platform is its integration with the Triton compiler. Triton is a Python-like language that allows users to write performant GPU kernels while abstracting away most of the underlying platform architecture. AMD has already added support for its GPUs as a third-party backend in Triton. And kernels for various performance critical operations, like FlashAttention-2, are available for AMD platforms, for both inference and training, with competitive performance (See Figure 3).
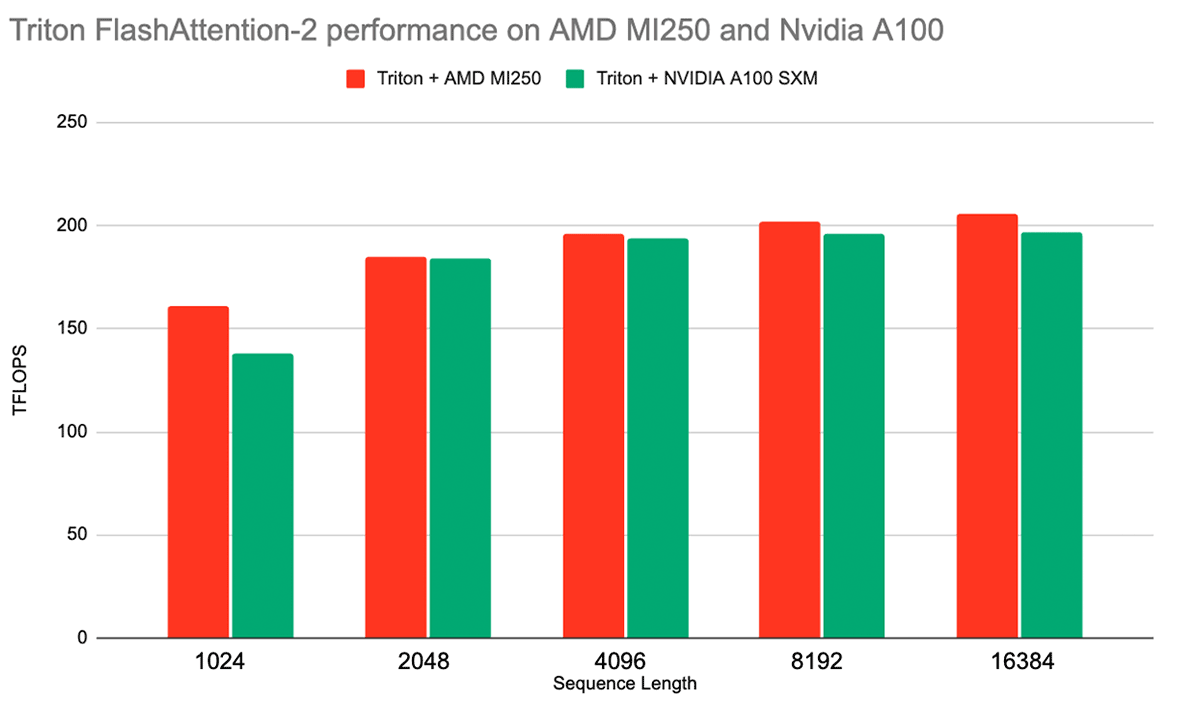
AMD’s support for Triton further increases interoperability between their platform and NVIDIA’s platform, and we look forward to upgrading our LLM Foundry to use Triton-based FlashAttention-2 for both AMD and NVIDIA GPUs. For more information on Triton support on ROCm, please see AMD’s presentation at the 2023 Triton Developer Conference.
LLM Training Performance
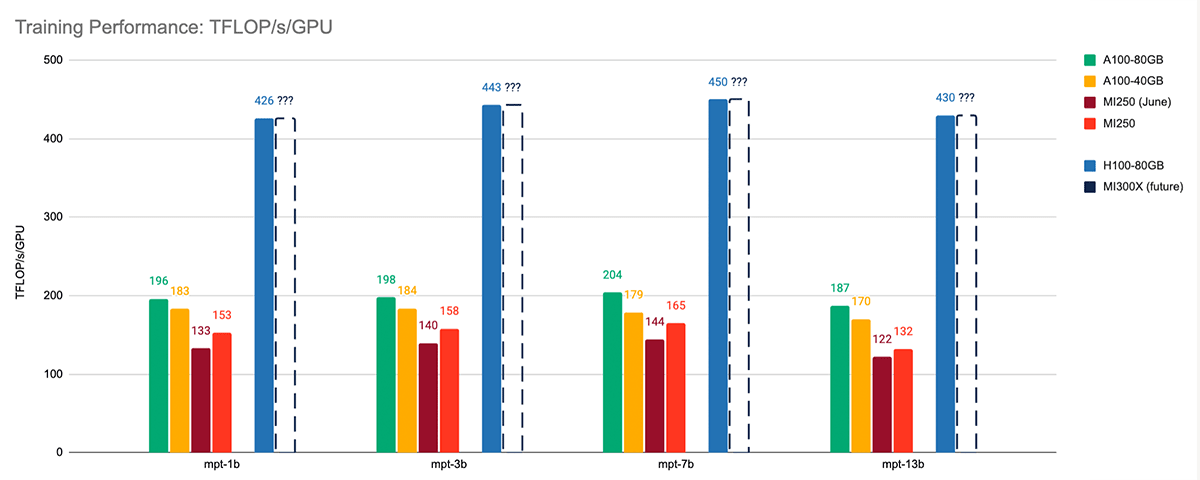
Starting with single-node LLM training performance, ROCm 5.7 + FlashAttention-2 is significantly faster than the earlier ROCm 5.4 + FlashAttention package. When training MPT models of various sizes, we saw an average speedup of 1.13x versus our training results in June. See Figure 4.
On each accelerator, we ran the same training scripts from LLM Foundry using MPT models with a sequence length of 2048, BF16 mixed precision, FlashAttention-2 (Triton-based on NVIDIA systems and ROCm-based on AMD systems today) and PyTorch FSDP with sharding_strategy: FULL_SHARD. We also tuned the microbatch size for each model on each system to achieve maximum performance. All training performance measurements are reporting model FLOPs rather than hardware FLOPs. See our benchmarking README for more details.
When comparing MI250 against the same-generation A100, we found that the two accelerators have similar performance. On average, MI250 training performance is within 85% of A100-40GB and 77% of A100-80GB.
When comparing the AMD MI250 to the new NVIDIA H100-80GB, there is a significant hill to climb. But based on public information about the upcoming MI300X, which has a memory bandwidth of 5.2TB/s vs. 3.35TB/s on H100-80GB, we expect that the MI300X will be very competitive with the H100.
Moving on to multi-node performance, the 128 x MI250 cluster shows excellent scaling performance for LLM training. See Figure 5. We trained an MPT-7B model with fixed global train batch size samples on [1, 2, 4, 8, 16, 32] nodes and found near-perfect scaling from 166 TFLOP/s/GPU at one node (4xMI250) to 159 TFLOP/s/GPU at 32 nodes (128xMI250). This is partly due to FSDP parameter sharding, which frees up GPU memory as it scales, allowing slightly larger microbatch sizes at larger device counts.
For more details about our training configs and how we measure performance, see our public LLM Foundry training benchmarking page.
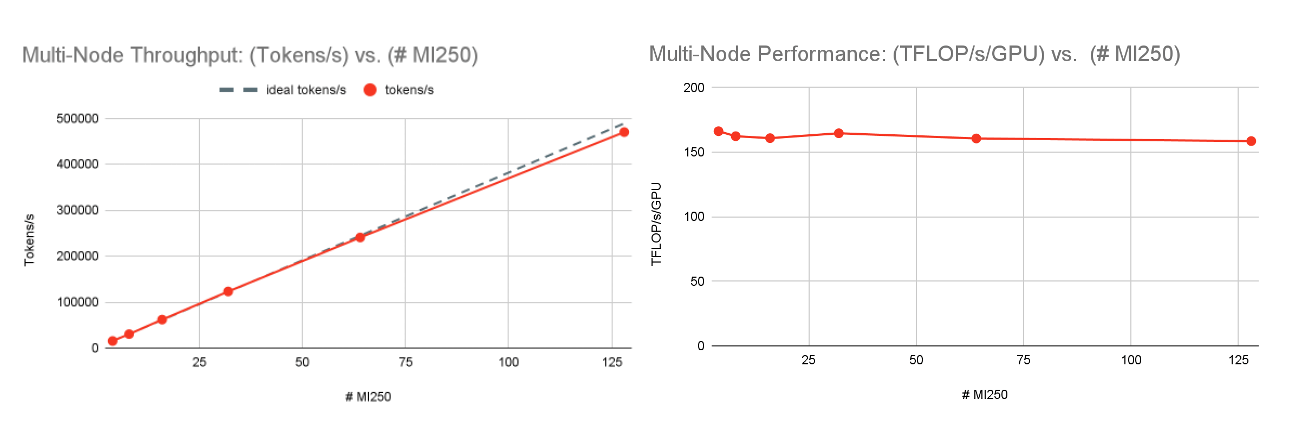
Given these results, we are very optimistic about MI250 performance at higher device counts, and we can’t wait to profile and share results on larger MI250/MI300X clusters in the future!
LLM Convergence
To test training stability on AMD MI250, we decided to train MPT-1B and MPT-3B models from scratch on the C4 dataset using Chinchilla-optimal token budgets to confirm that we could successfully train high-quality models on the AMD platform.
We trained each model on 64 x MI250 with BF16 mixed precision and FSDP. Overall, we found that training was stable and FSDP + distributed checkpointing worked flawlessly (See Figure 6).
When we evaluated the final models on standard in-context-learning (ICL) benchmarks, we found that our MPT-1B and MPT-3B models trained on AMD MI250 achieved similar results to Cerebras-GPT-1.3B and Cerebras-GPT-2.7B. These are a pair of open-source models trained with the same parameter counts and token budgets, allowing us to compare model quality directly. See Table 2 for results. All models were evaluated using the LLM Foundry eval harness and using the same set of prompts.
These convergence results give us confidence that customers can train high-quality LLMs on AMD with no significant issues due to floating point numerics vs. other hardware platforms.
| Model | Params | Tokens | ARC-c | ARC-e | BoolQ | Hellaswag | PIQA | Winograd | Winogrande | Average |
|---|---|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-1.3B | 1.3B | 26B | .245 | .445 | .583 | .380 | .668 | .630 | .522 | .496 |
| AMD-MPT-1B | 1.3B | 26B | .254 | .453 | .585 | .516 | .724 | .692 | .536 | .537 |
| Cerebras-GPT-2.7B | 2.7B | 53B | .263 | .492 | .592 | .482 | .712 | .733 | .558 | .547 |
| AMD-MPT-3B | 2.7B | 53B | .281 | .516 | .528 | .608 | .754 | .751 | .607 | .578 |
Table 2: Training details and evaluation results for MPT-[1B, 3B] vs. Cerebras-GPT-[1.3B, 2.7B]. Both pairs of models are trained with similar configurations and reach similar zero-shot accuracies on standard in-context-learning (ICL) tasks.
What’s Next?
In this blog, we’ve demonstrated that AMD MI250 is a compelling option for multi-node LLM training. Our initial results show strong linear scaling up to 128 x MI250, stable convergence, and thanks to recent software improvements, the MI250 is closing the performance gap with the A100-40GB.
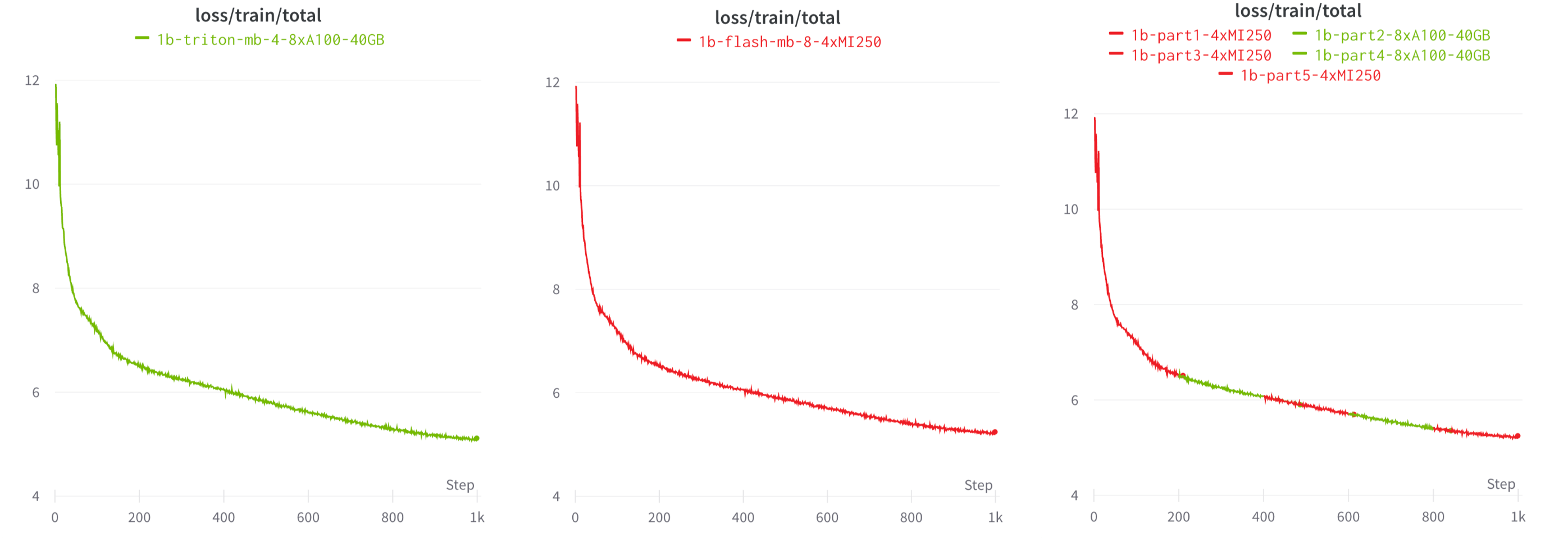
We believe these results strengthen the AI training story for AMD GPUs, and thanks to the interoperability of PyTorch, Triton, and open-source libraries (e.g., Composer, StreamingDataset, LLM Foundry), users can run the same LLM workloads on either NVIDIA or AMD or even switch between the platforms, as we demonstrate in Figure 7.
Stay tuned for future blogs on AMD MI300X and training at an even larger scale!


