Introduction
In the fast-paced world of data analytics, real-time processing has become a necessity. Modern businesses require insights not just quickly, but in real-time to make informed decisions and stay ahead of the competition. Apache Flink has emerged as a powerful tool in this domain, offering state-of-the-art stream processing capabilities. In this blog, we introduce our FlinkSQL interactive solution in accompanying productionising automation, and enhancing our users’ stream processing development journey.
Preface
Last year, we introduced Zeppelin notebooks for Flink, as detailed in our previous post Rethinking Stream Processing: Data Exploration in an effort to enhance data exploration for downstream data users. However, as our use cases evolved over time, we quickly hit a few technical roadblocks.
Flink version maintenance
Zeppelin notebook source code is maintained by a community separate from Flink’s community. As of writing, the latest Flink version supported is 1.17, whilst the latest Flink is already on version 1.20. This discrepancy in version support hinders our Flink upgrading efforts.
Cluster start up time
Our design to spin up a Zeppelin cluster per user on demand invokes a cold start delay, taking roughly around 5 minutes for the notebook to be ready. This delay is not suitable for use cases that require quick insights from production data. We quickly noticed that the user uptake of this solution was not as high as we expected.
Integration challenges
Whilst Zeppelin notebooks were useful for serving individual developers, we experienced difficulty integrating it with other internal platforms. We designed Zeppelin to empower solo data explorers, but other internal platforms like dashboards or automated pipelines needed a way to aggregate data from Kafka and Zeppelin just couldn’t keep up. The notebook setup was too isolated, requiring a workaround to share insights or plug into existing tools. For instance, if a team wanted to pull aggregated real-time metrics into a monitoring system, they had to export data manually, which is far from seamless access that we aimed for.
Introducing FlinkSQL interactive
With those considerations in mind, we decided to swap out our Zeppelin cluster with a shared FlinkSQL gateway cluster. We simplified our solution by removing some features our notebooks offered, focusing only on features that promote data democratisation.
We split our solution into 3 layers:
- Compute layer
- Integration layer
- Query layer
Users first interact with our platform portal to submit queries for data from Kafka online store using SQL (1). Upon submission, our backend orchestrator then creates a session for the user (2) and submits the SQL query to our FlinkSQL gateway using their inbuilt REST API (3). The FlinkSQL gateway then packages the SQL query into a Flink job to be submitted to our Flink session cluster (4) before collating its results. The subsequent results would be polled from the query layer to be displayed back to the user.
Compute layer
With FlinkSQL gateway acting as the main compute engine for ad-hoc queries, it is now more straightforward to perform Flink version upgrades along with our solution, since the FlinkSQL gateway is packaged along with the main Flink distribution. We do not need to maintain Flink shims for each version as adapters between the Flink compute cluster and Zeppelin notebook cluster.
Another advantage of using the shared FlinkSQL gateway was the reduced cold start time for each ad-hoc queries. Since all users share the same FlinkSQL cluster instead of having their own Zeppelin cluster, there was no need to wait for cluster startup during initialisation of their sessions. This brought the lead time to the first results displayed down from 5 minutes to 1 minute. There was still lead time involved as the tool provisions task managers on an ad-hoc basis to balance availability of such developer tools and the associated cost.
Integration layer
The Integration layer serves as the glue between the user-facing query layer and the underlying compute layer, ensuring seamless communication and security across our ecosystem. With the shift to a shared FlinkSQL gateway, we recognised the need for an intermediary that could handle authentication, authorisation, orchestration, and integration with internal platforms – all while abstracting the complexities of Flink’s native REST API.
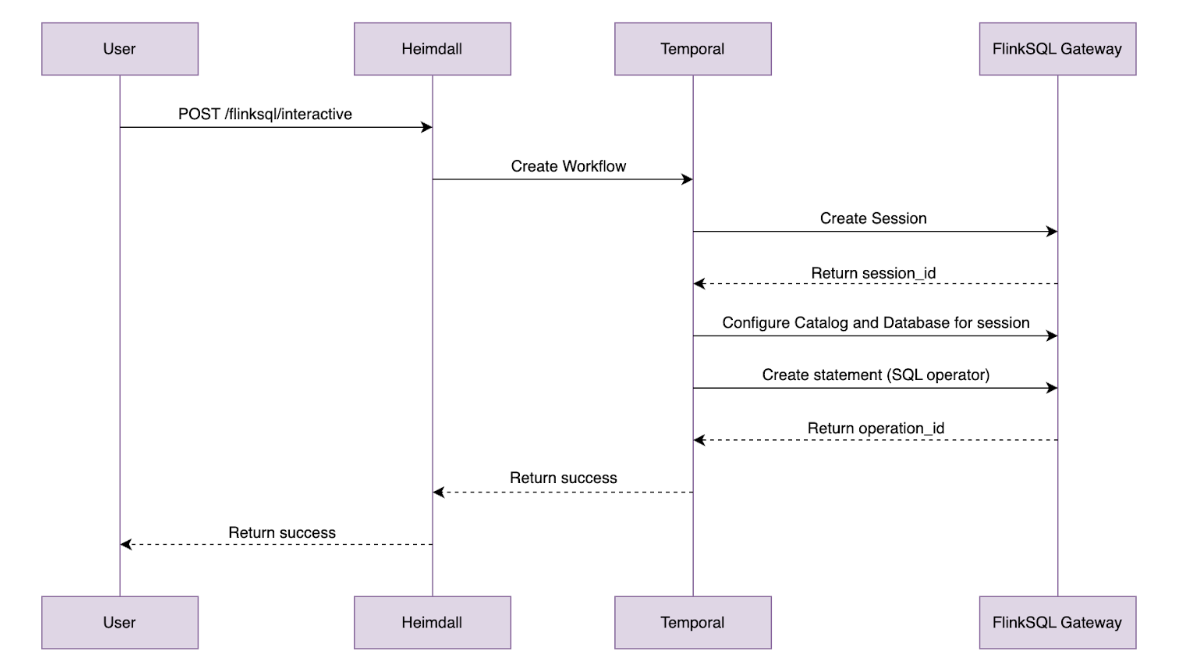
The FlinkSQL gateway’s built-in REST API gets the job done for basic query submission, but it falls short in areas like session management, requiring multiple POST requests just to fetch results. To address this, we extended a custom control plane with its own set of REST APIs, layered on top of the gateway.
We then extend these sessions and integrate them to our inhouse authentication and authorisation platform. For each query made, the control plane authenticates the user, spins up lightweight sessions and manages the communication between the caller and the Flink Session Cluster. If you are interested, check out our previous blog post, An elegant platform, for more details on the above mentioned streaming platform and its control plane.
curl --location 'https://example.com/v1/flink/flinksql/interactive'
--header 'Content-Type: application/json'
--header 'Authorization: Bearer ...'
--data '{
"environment" : "prd",
"namespace" : "flink",
"sql" : "SELECT * FROM titanicstream"}'
Example API request for running a FlinkSQL query
The integration layer also caters to B2B needs via our Headless APIs. By exposing the endpoints, developers are able to integrate real-time processing into their own tools. To run a query, programs can simply make a POST request with the SQL query and an operation ID would be returned. This operation ID could then be used in subsequent GET requests to fetch the paginated results of the unbounded query. This setup is ideal for internal platforms that need to query Kafka data programmatically. By abstracting these complexities, it ensures that users, whether individual analysts or internal platforms—can tap into Kafka data without wrestling with Flink’s raw interfaces.
Query layer
We then proceed to pair our APIs developed with an Interactive UI to build a Query layer that serves both human workflows. This is where users meet our platform.
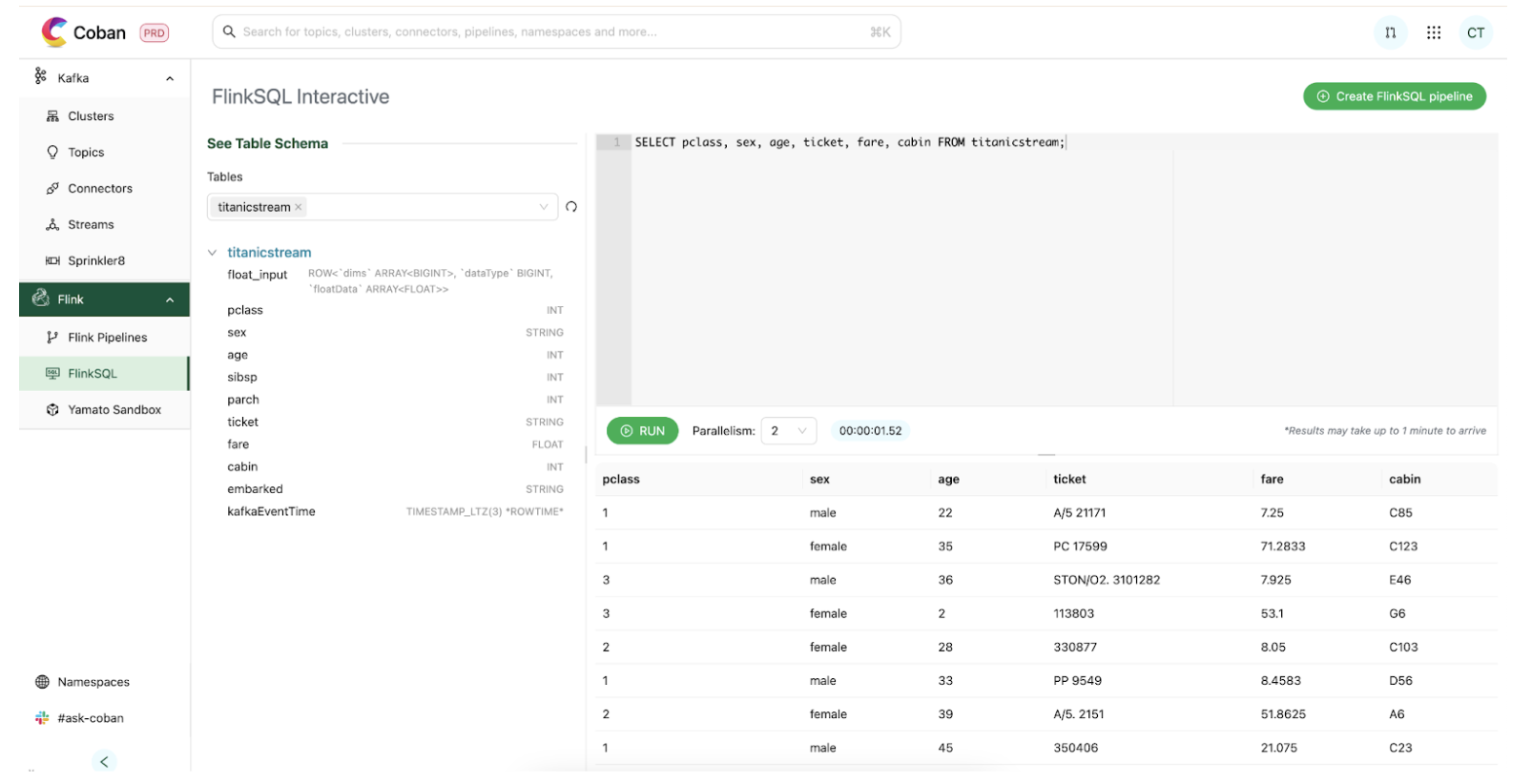
Through our platform portal, users land in a clean SQL editor. We used a Hive Metastore (HMS) catalog that translates Kafka topics into tables. Users don’t need to decode stream internals; they can jump straight into it by simply selecting a table to query on. Once a query is submitted, it is then handled by the integration layer which routes it through the control plane to the gateway. Results are then streamed back, appearing in the UI within one minute, a significant improvement from the five minute Zeppelin cold starts.
This all crystalises into the user flow demonstrated in Figure 3, where we can easily retrieve Titanic data from a Kafka stream with a short command:
SELECT COUNT(*) FROM titanicstream WHERE kafkaEventTime > NOW() - INTERVAL '1' HOUR.
This setup enables a few use cases for our teams, such as:
- Fraud analysts using the real-time data to debug and spot patterns in fraudulent transactions.
- Data scientists querying live signals to validate their prediction models.
- Engineers validating the messages sent from their system to confirm they are properly structured and accurately delivered.
Productionising FlinkSQL
With data being democratised, we see more users building use cases around our online data store and utilising the above tools to build new stream processing pipelines expressed as SQL queries. To simplify the last step of the software development lifecycle of deployment, we have also developed a tool to create a configuration based stream processing pipeline, with the business logic expressed as a SQL statement.
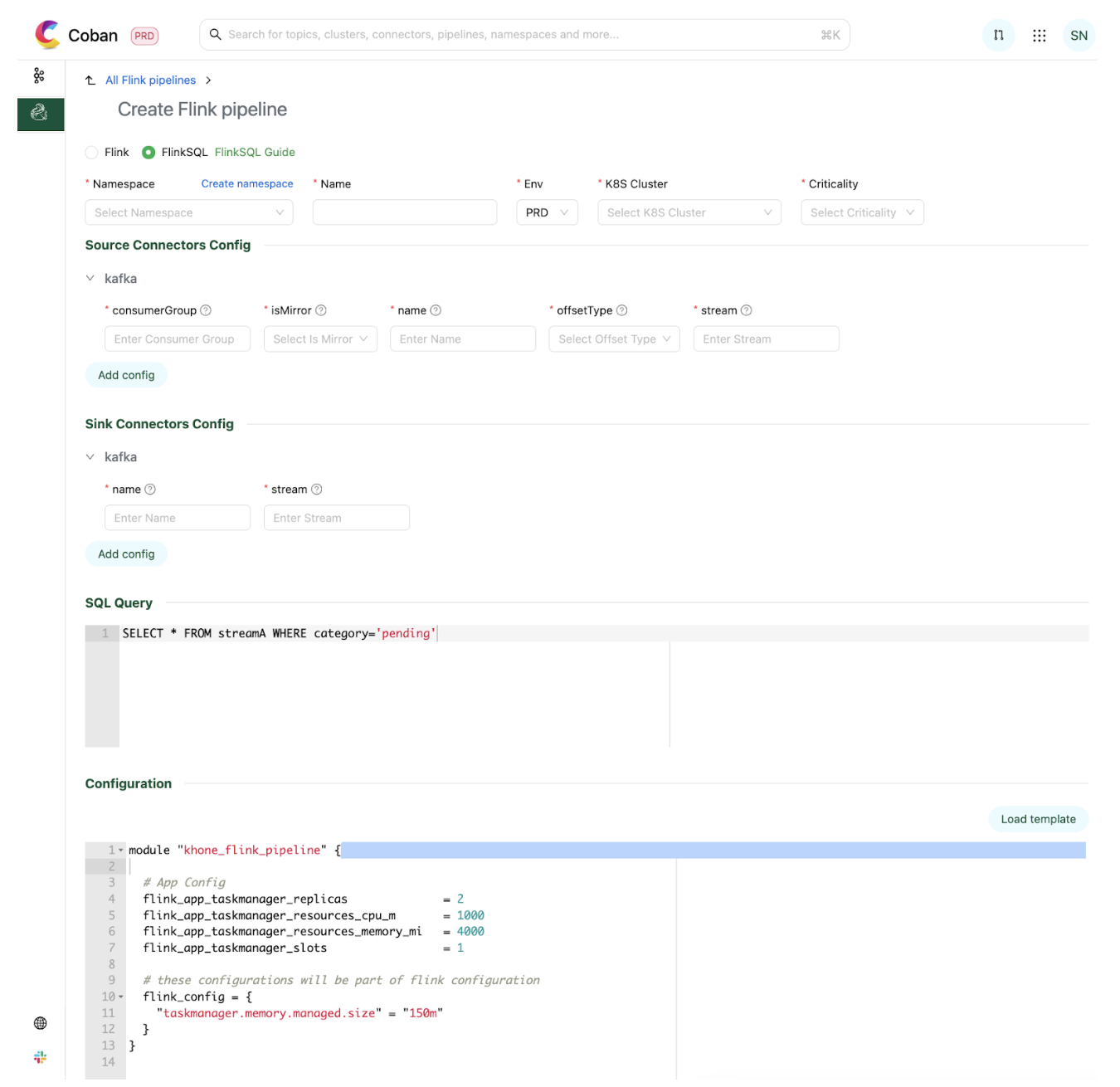
We host connectors for users to connect to other platforms within Grab, such as Kafka and our internal feature stores. Users could simply use them off-the-shelf and configure according to their needs before deploying their stream processing pipeline.
Users would then proceed to submit their streaming logic as a SQL statement. In the example illustrated in the diagram, the logic expressed is a simple filter on a Kafka stream for sinking the filtered events into a separate Kafka stream.
Users have the ability to then define the parallelism and associated resources they want to run their Flink jobs with. Upon submission, the associated resources would be provisioned and the Flink pipeline would be automatically deployed. Behind the scenes, we manage the application JAR file that is being used to run the job that dynamically parses these configurations and translates them into a proper Flink job graph to be submitted to the Flink cluster.
Within 10 minutes, users would have completed deploying their stream processing pipeline to production.
Conclusion
With our full suite of solutions for low code development via FlinkSQL, from exploration and design, to development and then deployment, we have simplified the journey for developing business use cases off online streaming stores. By offering both a user-friendly interface for low-code users and a robust API for developers, these tools empower businesses to harness the full potential of real-time data processing. Whether you are a data analyst looking for quick insights or a developer integrating real-time analytics into your applications, our tools are able to lower the barrier of entry to utilising real-time data.
After we released these solutions, we quickly saw an uptick in pipelines created as well as the number of interactive queries fired. This result was encouraging and we hope that this would gradually bring upon a paradigm shift, enabling Grab to make data-driven operational decisions on real-time signals, empowering us with the ability to react to ever-changing market conditions in the most efficient manner.
Grab is a leading superapp in Southeast Asia, operating across the deliveries, mobility and digital financial services sectors. Serving over 800 cities in eight Southeast Asian countries, Grab enables millions of people everyday to order food or groceries, send packages, hail a ride or taxi, pay for online purchases or access services such as lending and insurance, all through a single app. Grab was founded in 2012 with the mission to drive Southeast Asia forward by creating economic empowerment for everyone. Grab strives to serve a triple bottom line – we aim to simultaneously deliver financial performance for our shareholders and have a positive social impact, which includes economic empowerment for millions of people in the region, while mitigating our environmental footprint.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!