
Launched in 2019, Segmentation Platform has been Grab’s one-stop platform for user segmentation and audience creation across all business verticals. User segmentation is the process of dividing passengers, driver-partners, or merchant-partners (users) into sub-groups (segments) based on certain attributes. Segmentation Platform empowers Grab’s teams to create segments using attributes available within our data ecosystem and provides APIs for downstream teams to retrieve them.
Checking whether a user belongs to a segment (Membership Check) influences many critical flows on the Grab app:
- When a passenger launches the Grab app, our in-house experimentation platform will tailor the app experience based on the segments the passenger belongs to.
- When a driver-partner goes online on the Grab app, the Drivers service calls Segmentation Platform to ensure that the driver-partner is not blacklisted.
- When launching marketing campaigns, Grab’s communications platform relies on Segmentation Platform to determine which passengers, driver-partners, or merchant-partners to send communication to.
This article peeks into the current design of Segmentation Platform and how the team optimised the way segments are stored to reduce read latency thus unlocking new segmentation use cases.
Architecture
Segmentation Platform comprises two major subsystems:
- Segment creation
- Segment serving
Segment creation
Segment creation is powered by Spark jobs. When a Grab team creates a segment, a Spark job is started to retrieve data from our data lake. After the data is retrieved, cleaned, and validated, the Spark job calls the serving sub-system to populate the segment with users.
Segment serving
Segment serving is powered by a set of Go services. For persistence and serving, we use ScyllaDB as our primary storage layer. We chose to use ScyllaDB as our NoSQL store due to its ability to scale horizontally and meet our <80ms p99 SLA. Users in a segment are stored as rows indexed by the user ID. The table is partitioned by the user ID ensuring that segment data is evenly distributed across the ScyllaDB clusters.
| User ID | Segment Name | Other metadata columns |
|---|---|---|
| 1221 | Segment_A | … |
| 3421 | Segment_A | … |
| 5632 | Segment_B | … |
| 7889 | Segment_B | … |
With this design, Segmentation Platform handles up to 12K read and 36K write QPS, with a p99 latency of 40ms.
Problems
The existing system has supported Grab, empowering internal teams to create rich and personalised experiences. However, with the increased adoption and use, certain challenges began to emerge:
- As more and larger segments are being created, the write QPS became a bottleneck leading to longer wait times for segment creation.
- Grab services requested even lower latency for membership checks.
Long segment creation times
As more segments were created by different teams within Grab, the write QPS was no longer able to keep up with the teams’ demands. Teams would have to wait for hours for their segments to be created, reducing their operational velocity.
Read latency
Further, while the platform already offers sub-40ms p99 latency for reads, this was still too slow for certain services and their use cases. For example, Grab’s communications platform needed to check whether a user belongs to a set of segments before sending out communication and incurring increased latency for every communication request was not acceptable. Another use case was for Experimentation Platform, where checks must have low latency to not impact the user experience.
Thus, the team explored alternative ways of storing the segment data with the goals of:
- Reducing segment creation time
- Reducing segment read latency
- Maintaining or reducing cost
Solution
Segments as bitmaps
One of the main engineering challenges was scaling the write throughput of the system to keep pace with the number of segments being created. As a segment is stored across multiple rows in ScyllaDB, creating a large segment incurs a huge number of writes to the database. What we needed was a better way to store a large set of user IDs. Since user IDs are represented as integers in our system, a natural solution to storing a set of integers was a bitmap.
For example, a segment containing the following user IDs: 1, 6, 25, 26, 89 could be represented with a bitmap as follows:

To perform a membership check, a bitwise operation can be used to check if the bit at the user ID’s index is 0 or 1. As a bitmap, the segment can also be stored as a single Blob in object storage instead of inside ScyllaDB.
However, as the number of user IDs in the system is large, a small and sparse segment would lead to prohibitively large bitmaps. For example, if a segment contains 2 user IDs 100 and 200,000,000, it will require a bitmap containing 200 million bits (25MB) where all but 2 of the bits are just 0. Thus, the team needed an encoding to handle sparse segments more efficiently.
Roaring Bitmaps
After some research, we landed on Roaring Bitmaps, which are compressed uint32 bitmaps. With roaring bitmaps, we are able to store a segment with 1 million members in a Blob smaller than 1 megabyte, compared to 4 megabytes required by a naive encoding.
Roaring Bitmaps achieve good compression ratios by splitting the set into fixed-size (216) integer chunks and using three different data structures (containers) based on the data distribution within the chunk. The most significant 16 bits of the integer are used as the index of the chunk, and the least significant 16 bits are stored in the containers.
Array containers
Array containers are used when data is sparse (<= 4096 values). An array container is a sorted array of 16-bit integers. It is memory-efficient for sparse data and provides logarithmic-time access.
Bitmap containers
Bitmap containers are used when data is dense. A bitmap container is a 216 bit container where each bit represents the presence or absence of a value. It is memory-efficient for dense data and provides constant-time access.
Run containers
Finally, run containers are used when a chunk has long consecutive values. Run containers use run-length encoding (RLE) to reduce the storage required for dense bitmaps. Run containers store a pair of values representing the start and the length of the run. It provides good memory efficiency and fast lookups.
The diagram below shows how a dense bitmap container that would have required 91 bits can be compressed into a run container by storing only the start (0) and the length (90). It should be noted that run containers are used only if it reduces the number of bytes required compared to a bitmap.
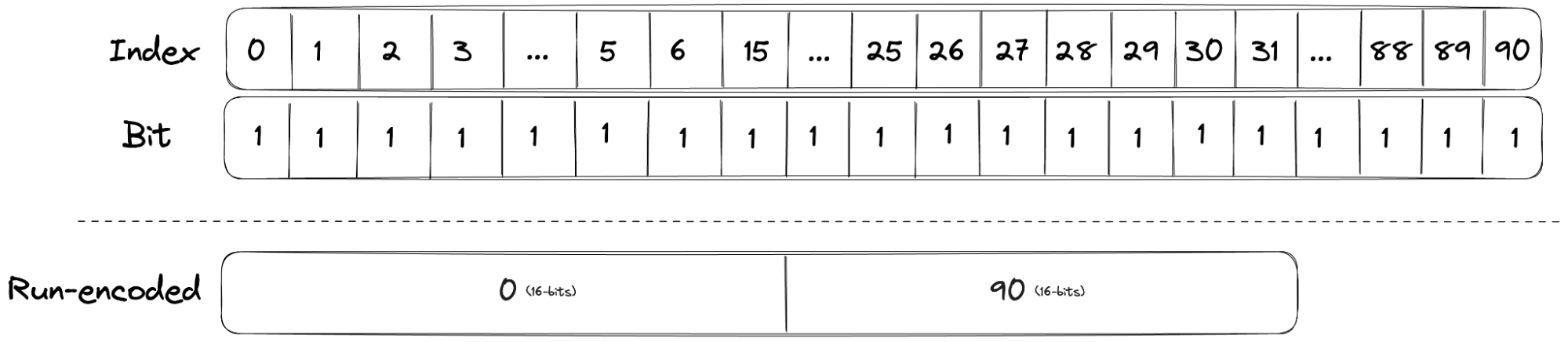
By using different containers, Roaring Bitmaps are able to achieve good compression across various data distributions, while maintaining excellent lookup performance. Additionally, as segments are represented as Roaring Bitmaps, service teams are able to perform set operations (union, interaction, and difference, etc) on the segments on the fly, which previously required re-materialising the combined segment into the database.
Caching with an SDK
Even though the segments are now compressed, retrieving a segment from the Blob store for each membership check would incur an unacceptable latency penalty. To mitigate the overhead of retrieving a segment, we developed an SDK that handles the retrieval and caching of segments.
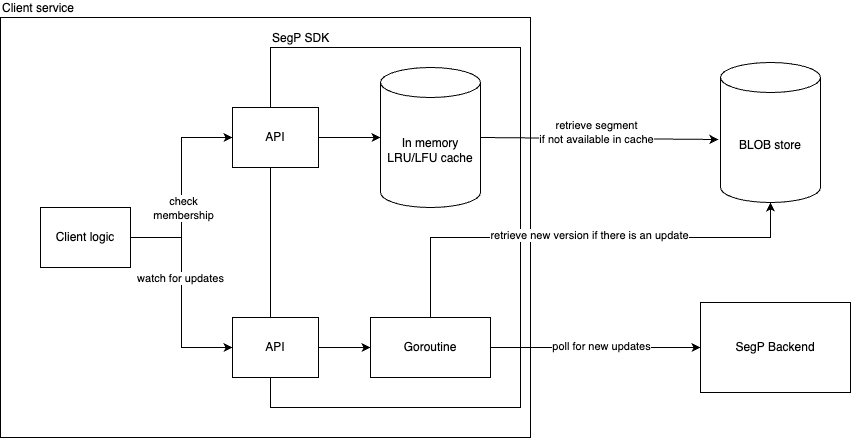
The SDK takes care of the retrieval, decoding, caching, and watching of segments. Users of the SDK are only required to specify the maximum size of the cache to prevent exhausting the service’s memory. The SDK provides a cache with a least-recently-used eviction policy to ensure that hot segments are kept in the cache. They are also able to watch for updates on a segment and the SDK will automatically refresh the cached segment when it is updated.
Hero teams
Communications Platform
Communications Platform has adopted the SDK to implement a new feature to control the communication frequency based on which segments a user belongs to. Using the SDK, the team is able to perform membership checks on multiple multi-million member segments, achieving peak QPS 15K/s with a p99 latency of <1ms. With the new feature, they have been able to increase communication engagement and reduce the communication unsubscribe rate.
Experimentation Platform
Experimentation Platform powers experimentation across all Grab services. Segments are used heavily in experiments to determine a user’s experience. Prior to using the SDK, Experimentation Platform limited the maximum size of the segments that could be used to prevent exhausting a service’s memory.
After migrating to the new SDK, they were able to lift this restriction due to the compression efficiency of Roaring Bitmaps. Users are now able to use any segments as part of their experiment without worrying that it would require too much memory.
Closing
This blog post discussed the challenges that Segmentation Platform faced when scaling and how the team explored alternative storage and encoding techniques to improve segment creation time, while also achieving low latency reads. The SDK allows our teams to easily make use of segments without having to handle the details of caching, eviction, and updating of segments.
Moving forward, there are still existing use cases that are not able to use the Roaring Bitmap segments and thus continue to rely on segments from ScyllaDB. Therefore, the team is also taking steps to optimise and improve the scalability of our service and database.
Special thanks to Axel, the wider Segmentation Platform team, and Data Technology team for reviewing the post.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!


