
Introduction
This article introduces the GrabX Decision Engine, an internal open-source package that offers a comprehensive framework for designing and analysing experiments conducted on online experiment platforms. The package encompasses a wide range of functionalities, including a pre-experiment advisor, a post-experiment analysis toolbox, and other advanced tools. In this article, we explore the motivation behind the development of these functionalities, their integration into the unique ecosystem of Grab’s multi-sided marketplace, and how these solutions strengthen the culture and calibre of experimentation at Grab.
Background
Today, Grab’s Experimentation (GrabX) platform orchestrates the testing of thousands of experimental variants each week. As the platform continues to expand and manage a growing volume of experiments, the need for dependable, scalable, and trustworthy experimentation tools becomes increasingly critical for data-driven and evidence-based
decision-making.
In our previous article, we presented the Automated Experiment Analysis application, a tool designed to automate data pipelines for analyses. However, during the development of this application for Grab’s experimenter community, we noticed a prevailing trend: experiments were predominantly analysed on a one-by-one, manual basis. While such a federated approach may be needed in a few cases, it presents numerous challenges at
the organisational level:
- Lack of a contextual toolkit: GrabX facilitates executing a diverse range of experimentation designs, catering to the varied needs and contexts of different tech teams across the organisation. However, experimenters may often rely on generic online tools for experiment configurations (e.g. sample size calculations), which were not specifically designed to cater to the nuances of GrabX experiments or the recommended evaluation method, given the design. This is exacerbated by the fact
that most online tutorials or courses on experimental design do not typically address the nuances of multi-sided marketplaces, and cannot consider the nature or constraints of specific experiments. - Lack of standards: In this federated model, the absence of standardised and vetted practices can lead to reliability issues. In some cases, these can include poorly designed experiments, inappropriate evaluation methods, suboptimal testing choices, and unreliable inferences, all of which are difficult to monitor and rectify.
- Lack of scalability and efficiency: Experimenters, coming from varied backgrounds and possessing distinct skill sets, may adopt significantly different approaches to experimentation and inference. This diversity, while valuable, often impedes the transferability and sharing of methods, hindering a cohesive and scalable experimentation framework. Additionally, this variance in methods can extend the lifecycle of experiment analysis, as disagreements over approaches may give rise to
repeated requests for review or modification.
Solution
To address these challenges, we developed the GrabX Decision Engine, a Python package open-sourced internally across all of Grab’s development platforms. Its central objective is to institutionalise best practices in experiment efficiency and analytics, thereby ensuring the derivation of precise and reliable conclusions from each experiment.
In particular, this unified toolkit significantly enhances our end-to-end experimentation processes by:
- Ensuring compatibility with GrabX and Automated Experiment Analysis: The package is fully integrated with the Automated Experiment Analysis app, and provides analytics and test results tailored to the designs supported by GrabX. The outcomes can be further used for other downstream jobs, e.g. market modelling, simulation-based calibrations, or auto-adaptive configuration tuning.
- Standardising experiment analytics: By providing a unified framework, the package ensures that the rationale behind experiment design and the interpretation of analysis results adhere to a company-wide standard, promoting consistency and ease of review across different teams.
- Enhancing collaboration and quality: As an open-source package, it not only fosters a collaborative culture but also upholds quality through peer reviews. It invites users to tap into a rich pool of features while encouraging contributions that refine and expand the toolkit’s capabilities.
The package is designed for everyone involved in the experimentation process, with data scientists and product analysts being the primary users. Referred to as experimenters in this article, these key stakeholders can not only leverage the existing capabilities of the package to support their projects, but can also contribute their own innovations. Eventually, the experiment results and insights generated from the package via the Automated Experiment Analysis app have an even wider reach to stakeholders across all functions.
In the following section, we go deeper into the key functionalities of the package.
Feature details
The package comprises three key components:
- An experimentation trusted advisor
- A comprehensive post-experiment analysis toolbox
- Advanced tools
These have been built taking into account the type of experiments we typically run at Grab. To understand their functionality, it’s useful to first discuss the key experimental designs supported by GrabX.
A note on experimental designs
While there is a wide variety of specific experimental designs implemented, they can be bucketed into two main categories: a between-subject design and a within-subject design.
In a between-subject design, participants — like our app users, driver-partners, and merchant-partners — are split into experimental groups, and each group gets exposed to a distinct condition throughout the experiment. One challenge in this design is that each participant may provide multiple observations to our experimental analysis sample, causing a high within-subject correlation among observations and deviations between the randomisation and session unit. This can affect the accuracy of
pre-experiment power analysis, and post-experiment inference, since it necessitates adjustments, e.g. clustering of standard errors when conducting hypothesis testing.
Conversely, a within-subject design involves every participant experiencing all conditions. Marketplace-level switchback experiments are a common GrabX use case, where a timeslice becomes the experimental unit. This design not only faces the aforementioned challenges, but also creates other complications that need to be accounted for, such as spillover effects across timeslices.
Designing and analysing the results of both experimental approaches requires careful nuanced statistical tools. Ensuring proper duration, sample size, controlling for confounders, and addressing potential biases are important considerations to enhance the validity of the results.
Trusted Advisor
The first key component of the Decision Engine is the Trusted Advisor, which provides a recommendation to the experimenter on key experiment attributes to be considered when preparing the experiment. This is dependent on the design; at a minimum, the experimenter needs to define whether the experiment design is between- or within-subject.
The between-subject design: We strongly recommend that experimenters utilise the “Trusted Advisor” feature in the Decision Engine for estimating their required sample size. This is designed to account for the multiple observations per user the experiment is expected to generate and adjusts for the presence of clustered errors (Moffatt, 2020; List, Sadoff, & Wagner, 2011). This feature allows users to input their data, either as a PySpark or Pandas dataframe. Alternatively, a function is
provided to extract summary statistics from their data, which can then be inputted into the Trusted Advisor. Obtaining the data beforehand is actually not mandatory; users have the option to directly query the recommended sample size based on common metrics derived from a regular data pipeline job. These functionalities are illustrated in the flowchart below.
Furthermore, the Trusted Advisor feature can identify the underlying characteristics of the data, whether it’s passed directly, or queried from our common metrics database. This enables it to determine the appropriate power analysis for the experiment, without further guidance. For instance, it can detect if the target metric is a binary decision variable, and will adapt the power analysis to the correct context.
The within-subject design: In this case, we instead provide a best practices guideline to follow. Through our experience supporting various Tech Families running switchback experiments, we have observed various challenges highly dependent on the use case. This makes it difficult to create a one-size-fits-all solution.
For instance, an important factor affecting the final sample size requirement is how frequently treatments switch, which is also tied to what data granularity is appropriate to use in the post-experiment analysis. These considerations are dependent on, among other factors, how quickly a given treatment is expected to cause an effect. Some treatments may take effect relatively quickly (near-instantly, e.g. if applied to price checks), while others may take significantly longer (e.g. 15-30 minutes because they may require a trip to be completed). This has further consequences, e.g. autocorrelation between observations within a treatment window, spillover effects between different treatment windows, requirements for cool-down windows when treatments switch, etc.
Another issue we have identified from analysing the history of experiments on our platform is that a significant portion is prone to issues related to sample ratio mismatch (SRM). We therefore also heavily emphasise the post-experiment analysis corrections and robustness checks that are needed in switchback experiments, and do not simply rely on pre-experiment guidance such as power analysis.
Post-experiment analysis
Upon completion of the experiment, a comprehensive toolbox for post-experiment analysis is available. This toolbox consists of a wide range of statistical tests, ranging from normality tests to non-parametric and parametric tests. Here is an overview of the different types of tests included in the toolbox for different experiment setups:
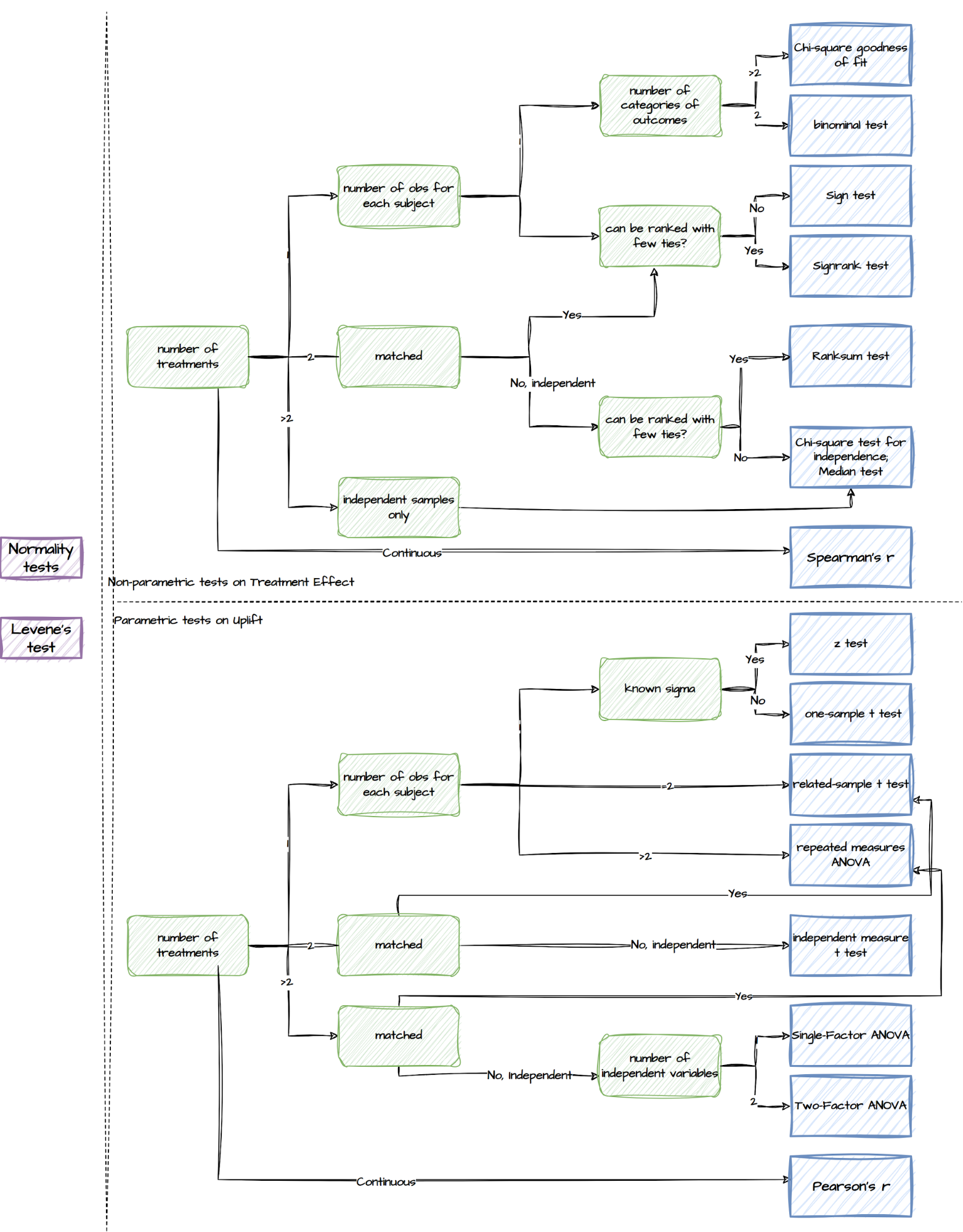
Though we make all the relevant tests available, the package sets a default list of output. With just two lines of code specifying the desired experiment design, experimenters can easily retrieve the recommended results, as summarised in the following table.
| Types | Details |
|---|---|
| Basic statistics | The mean, variance, and sample size of Treatment and Control |
| Uplift tests | Welch’s t-test; Non-parametric tests, such as Wilcoxon signed-rank test and Mann-Whitney U Test |
| Misc tests | Normality tests such as the Shapiro-Wilk test, Anderson-Darling test, and Kolmogorov-Smirnov test; Levene test which assesses the equality of variances between groups |
| Regression models | A standard OLS/Logit model to estimate the treatment uplift; Recommended regression models |
| Warning | Provides a warning or notification related to the statistical analysis or results, for example: – Lack of variation in the variables – Sample size is too small – Too few randomisation units which will lead to under-estimated standard errors |
Recommended regression models
Besides reporting relevant statistical test results, we adopt regression models to leverage their flexibility in controlling for confounders, fixed effects and heteroskedasticity, as is commonly observed in our experiments. As mentioned in the section “A note on experimental design”, each approach has different implications on the achieved randomisation, and hence requires its own customised regression models.
Between-subject design: the observations are not independent and identically distributed (i.i.d) but clustered due to repeated observations of the same experimental units. Therefore, we set the default clustering level at the participant level in our regression models, considering that most of our between-subject experiments only take a small portion of the population (Abadie et al., 2022).
Within-subject design: this has further challenges, including spillover effects and randomisation imbalances. As a result, they often require better control of confounding factors. We adopt panel data methods and impose time fixed effects, with no option to remove them. Though users have the flexibility to define these themselves, we use hourly fixed effects as our default as we have found that these match the typical seasonality we observe in marketplace metrics. Similar to between-subject
designs, we use standard error corrections for clustered errors, and small number of clusters, as the default. Our API is flexible for users to include further controls, as well as further fixed effects to adapt the estimator to geo-timeslice designs.
Advanced tools
Apart from the pre-experiment Trusted Advisor and the post-experiment Analysis Toolbox, we have enriched this package by providing more advanced tools. Some of them are set as a default feature in the previous two components, while others are ad-hoc capabilities which the users can utilise via calling the functions directly.
Variance reduction
We bring in multiple methods to reduce variance and improve the power and sensitivity of experiments:
- Stratified sampling: recognised for reducing variance during assignment
- Post stratification: a post-assignment variance reduction technique
- CUPED: utilises ANCOVA to decrease variances
- MLRATE: an extension of CUPED that allows for the use of non-linear / machine learning models
These approaches offer valuable ways to mitigate variance and improve the overall effectiveness of experiments. The experimenters can directly access these ad hoc capabilities via the package.
Multiple comparisons problem
A multiple comparisons problem occurs when multiple hypotheses are simultaneously tested, leading to a higher likelihood of false positives. To address this, we implement various statistical correction techniques in this package, as illustrated below.
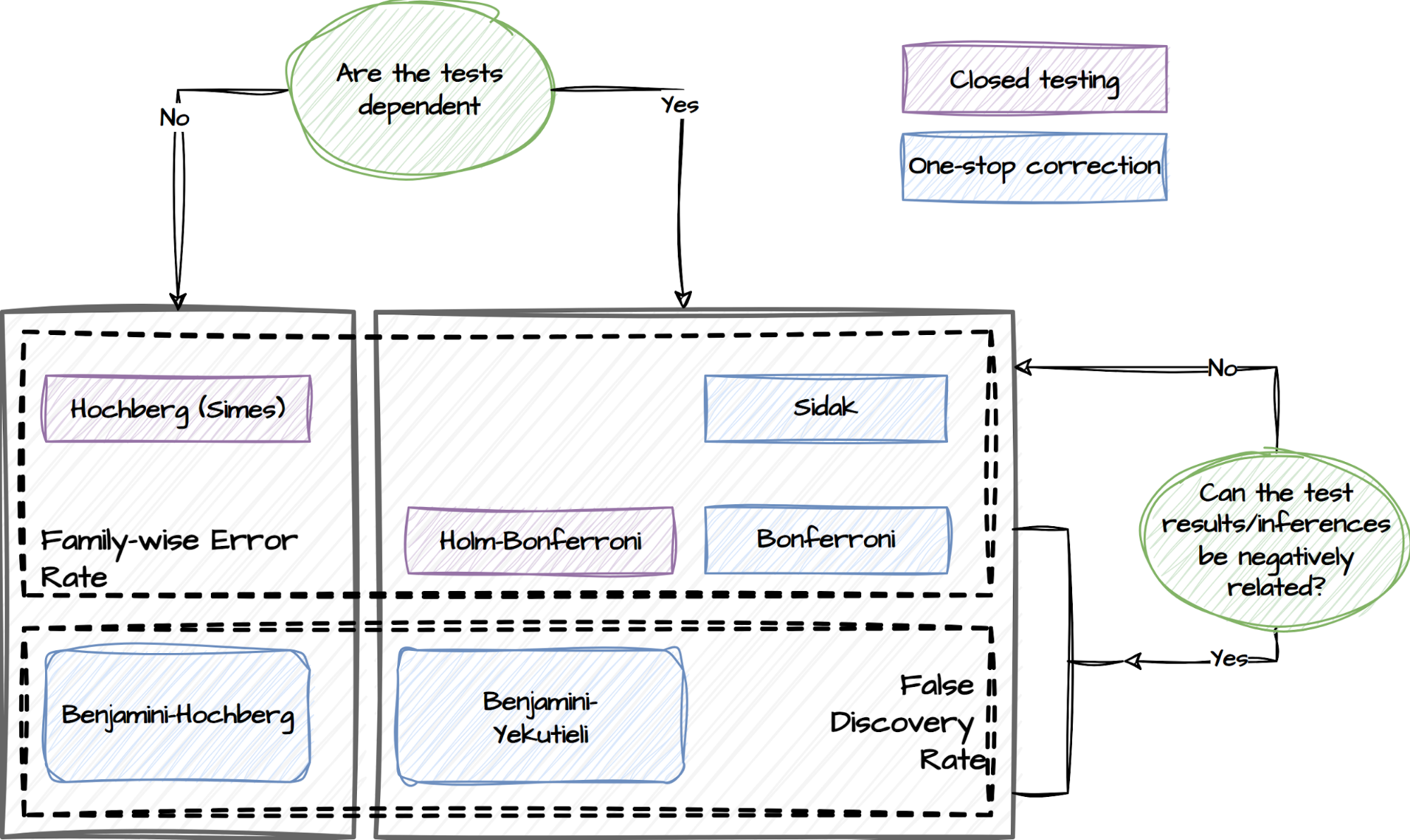
Experimenters can specify if they have concerns about the dependency of the tests and whether the test results are expected to be negatively related. This capability will adopt the following procedures and choose the relevant tests to mitigate the risk of false positives accordingly:
- False Discovery Rate (FDR) procedures, which control the expected rate of false discoveries.
- Family-wise Error Rate (FWER) procedures, which control the probability of making at least one false discovery within a set of related tests referred to as a family.
Multiple treatments and unequal treatment sizes
We developed a capability to deal with experiments where there are multiple treatments. This capability employs a conservative approach to ensure that the size reaches a minimum level where any pairwise comparison between the control and treatment groups has a sufficient sample size.
Heterogeneous treatment effects
Heterogeneous treatment effects refer to a situation where the treatment effect varies across different groups or subpopulations within a larger population. For instance, it may be of interest to examine treatment effects specifically on rainy days compared to non-rainy days. We have incorporated this functionality into the tests for both experiment designs. By enabling this feature, we facilitate a more nuanced analysis that accounts for potential variations in treatment effects based on different factors or contexts.
Maintenance and support
The package is available across all internal DS/Machine Learning platforms and individual local development environments within Grab. Its source code is openly accessible to all developers within Grab and its release adheres to a semantic release standard.
In addition to the technical maintenance efforts, we have introduced a dedicated committee and a workspace to address issues that may extend beyond the scope of the package’s current capabilities.
Experiment Council
Within Grab, there is a dedicated committee known as the ‘Experiment Council’. This committee includes data scientists, analysts, and economists from various functions. One of their responsibilities is to collaborate to enhance and maintain the package, as well as guide users in effectively utilising its functionalities. The Experiment Council plays a crucial role in enhancing the overall operational excellence of conducting experiments and deriving meaningful insights from them.
GrabCausal Methodology Bank
Experimenters frequently encounter challenges regarding the feasibility of conducting experiments for causal problems. To address this concern, we have introduced an alternative workspace called GrabCausal Methodology Bank. Similar to the internal open-source nature of this project, the GrabCausal Methodology bank is open to contributions from all users within Grab. It provides a collaborative space where users can readily share their code, case studies, guidelines, and suggestions related to
causal methodologies. By fostering an open and inclusive environment, this workspace encourages knowledge sharing and promotes the advancement of causal research methods.
The workspace functions as a platform, which now exhibits a wide range of commonly used methods, including Diff-in-Diff, Event studies, Regression Discontinuity Designs (RDD), Instrumental Variables (IV), Bayesian structural time series, and Bunching. Additionally, we are dedicated to incorporating more, such as Synthetic control, Double ML (Chernozhukov et al. 2018), DAG discovery/validation, etc., to further enhance our offerings in this space.
Learnings
Over the past few years, we have invested in developing and expanding this package. Our initial motivation was humble yet motivating – to contribute to improving the quality of experimentation at Grab, helping it develop from its initial start-up modus operandi to a more consolidated, rigorous, and guided approach.
Throughout this journey, we have learned that prioritisation holds the utmost significance in open-source projects of this nature; the majority of user demands can be met through relatively small yet pivotal efforts. By focusing on these core capabilities, we avoid spreading resources too thinly across all areas at the initial stage of planning and development.
Meanwhile, we acknowledge that there is still a significant journey ahead. While the package now focuses solely on individual experiments, an inherent challenge in online-controlled experimentation platforms is the interference between experiments (Gupta, et al, 2019). A recent development in the field is to embrace simultaneous tests (Microsoft, Google, Spotify and booking.com and Optimizely), and to carefully consider the tradeoff between accuracy and velocity.
The key to overcoming this challenge will be a close collaboration between the community of experimenters, the teams developing this unified toolkit, and the GrabX platform engineers. In particular, the platform developers will continue to enrich the experimentation SDK by providing diverse assignment strategies, sampling mechanisms, and user interfaces to manage potential inference risks better. Simultaneously, the community of experimenters can coordinate among themselves effectively to
avoid severe interference, which will also be monitored by GrabX. Last but not least, the development of this unified toolkit will also focus on monitoring, evaluating, and managing inter-experiment interference.
In addition, we are committed to keeping this package in sync with industry advancements. Many existing tools in this package, despite being labelled as “advanced” in the earlier discussions, are still relatively simplified. For instance,
- Incorporating standard errors clustering based on the diverse assignment and sampling strategies requires attention (Abadie, et al, 2023).
- Sequential testing will play a vital role in detecting uplifts earlier and safely, avoiding p-hacking. One recent innovation is the “always valid inference” (Johari, et al., 2022)
- The advancements in investigating heterogeneous effects, such as Causal Forest (Athey and Wager, 2019), have extended beyond linear approaches, now incorporating nonlinear and more granular analyses.
- Estimating the long-term treatment effects observed from short-term follow-ups is also a long-term objective, and one approach is using a Surrogate Index (Athey, et al 2019).
- Continuous effort is required to stay updated and informed about the latest advancements in statistical testing methodologies, to ensure accuracy and effectiveness.
This article marks the beginning of our journey towards automating the experimentation and product decision-making process among the data scientist community. We are excited about the prospect of expanding the toolkit further in these directions. Stay tuned for more updates and posts.
References
-
Abadie, Alberto, et al. “When should you adjust standard errors for clustering?.” The Quarterly Journal of Economics 138.1 (2023): 1-35.
-
Athey, Susan, et al. “The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely.” No. w26463. National Bureau of Economic Research, 2019.
-
Athey, Susan, and Stefan Wager. “Estimating treatment effects with causal forests: An application.” Observational studies 5.2 (2019): 37-51.
-
Chernozhukov, Victor, et al. “Double/debiased machine learning for treatment and structural parameters.” (2018): C1-C68.
-
Facure, Matheus. Causal Inference in Python. O’Reilly Media, Inc., 2023.
-
Gupta, Somit, et al. “Top challenges from the first practical online controlled experiments summit.” ACM SIGKDD Explorations Newsletter 21.1 (2019): 20-35.
-
Huntington-Klein, Nick. The Effect: An Introduction to Research Design and Causality. CRC Press, 2021.
-
Imbens, Guido W. and Donald B. Rubin. Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press, 2015.
-
Johari, Ramesh, et al. “Always valid inference: Continuous monitoring of a/b tests.” Operations Research 70.3 (2022): 1806-1821.
-
List, John A., Sally Sadoff, and Mathis Wagner. “So you want to run an experiment, now what? Some simple rules of thumb for optimal experimental design.” Experimental Economics 14 (2011): 439-457.
-
Moffatt, Peter. Experimetrics: Econometrics for Experimental Economics. Bloomsbury Publishing, 2020.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!


