
Introduction
Often, ecommerce marketplaces provide buyers with listings similar to those previously visited by the buyer, as well as a personalized shopping experience based on profiles, past shopping histories and behavior signals such as clicks, views and additions to cart. These are vital to the shopping experience, and so it’s equally vital that we continuously improve accuracy and robustness in scalability and performance.
eBay has approximately 134 million users and 1.7 billion live listings at any given time on the marketplace, as of December 2022. Recently, the eBay CoreAI team launched an “Approximate Nearest Neighbor” (ANN) vector similarity engine that provides tooling to build use cases that match semantically similar items and personalize recommendations. More specifically, given an input listing, the similarity engine finds the most similar listings based on listing attributes (title, aspect, image) for item-to-item similarity or generates personalized listing recommendations based on a user’s past browsing activity for user-to-item objective.
This article takes a look at the architecture we constructed for vector-based similarity, meeting the scale using data sharding, partitioning and replication, and features including attribute-based features and a pluggable ANN backend based on index building, recall accuracy, latencies and memory footprint.
What is Vector Similarity?
Keyword-based retrieval methods often struggle with certain challenges. Among those are words that have a dual meaning (otherwise known as homonyms); more targeted keyword phrases in which users add a great deal of detail (long tail queries); and user intent. In addition, there are many users who are unfamiliar with the jargon of a particular category, or users who do exploratory searches to figure out what their next, more important search will be.
Vector-based similarity for deep learning (DL)models tackles these and other keyword-based retrieval pitfalls. The paradigm for building semantic matching systems is computing vector representations of the entities. These vector representations are often called embeddings. Items that are close to each other in the embedding space are more similar to each other.
Traditional nearest neighbor algorithms, like k-Nearest Neighbor Algorithm (kNN), are prohibitively computationally expensive and are not suitable for applications where a low latency response is needed. Approximate Nearest Neighbor (ANN) sacrifices perfect accuracy in exchange for executing efficiently in high dimensional embedding spaces, at scale.
eBay’s Similarity Engine uses an ANN algorithm called Hierarchical Navigable Small World Graphs (HNSW) and Scalable Nearest Neighbors (ScaNN). ANN techniques speed up the search by preprocessing the data into an efficient index, and are often tackled using data structures like inverted files, trees and neighborhood graphs.
eBay Similarity Engine
Here are some of the key features of the eBay Similarity Engine:

eBay Similarity Engine is a billion-scale vector similarity matching engine, deployed on eBay’s private cloud. It is a lightning-fast and massively scalable nearest neighbor search that can handle thousands of requests per second and returns similarity results in less than 25 milliseconds for 95 percent of the responses while searching through eBay’s entire active inventory of 1.7 billion items. It supports attribute-based filtering, which allows the user to specify attributes such as item location, item category, item attributes and more at the time of query to improve relevance. It also supports multiple distance matrices: Squared L2, Inner product, Cosine similarity, and Hamming distance. And it supports multiple ANN backends, including:
-
HNSW, a graph-based search algorithm. We use our own modified version with various improvements.
-
ScaNN, an efficient search implementation from Google based on product quantization and partitioning.
Similarity Engine Building Blocks
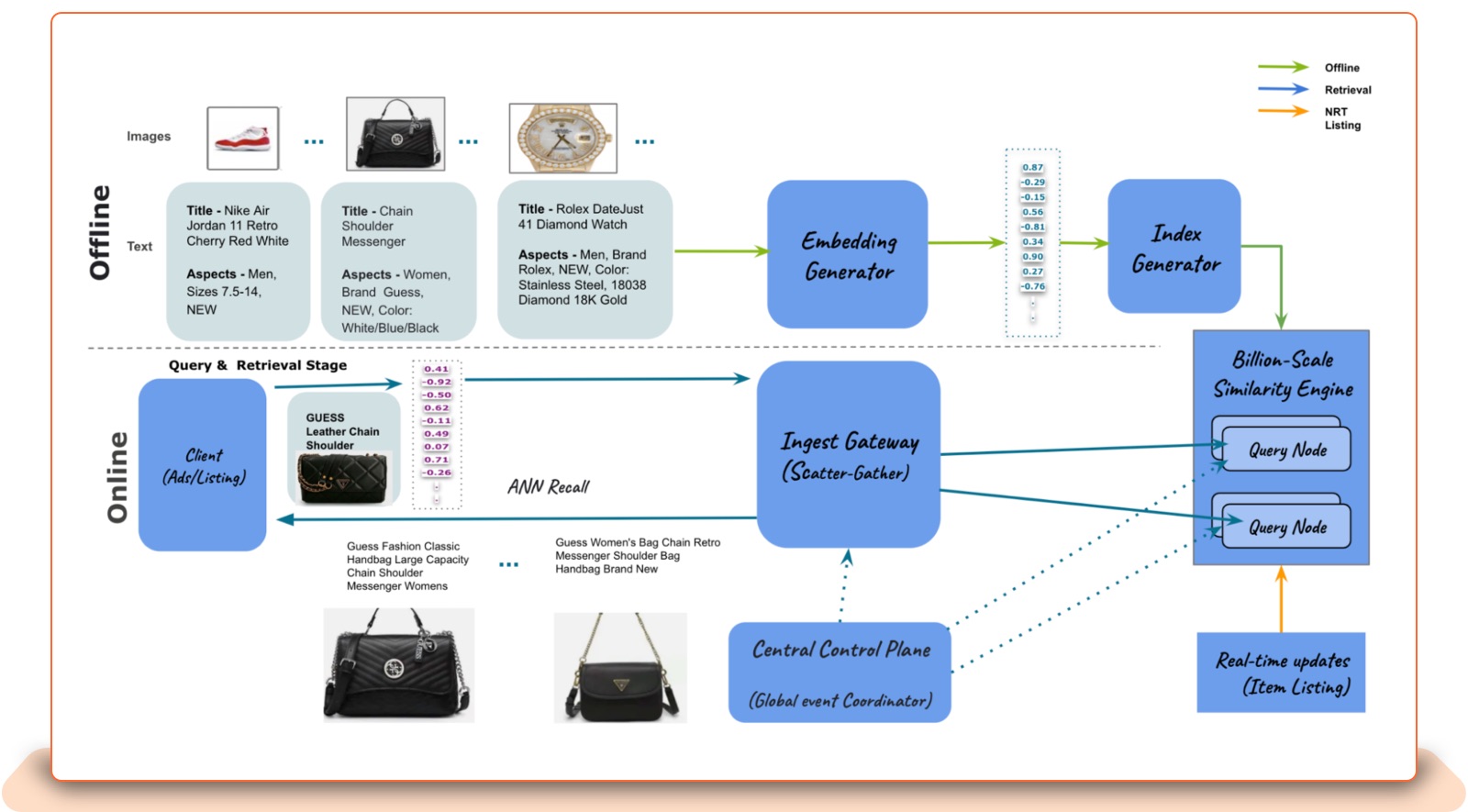
In vector similarity lookup, we build embeddings representing images, listing titles and aspects, storing them in an index (a database for embeddings), and then searching through that index with input embedding. The Similarity Engine serves tens of thousands of requests per second over a low-latency representational state transfer (REST) API to meet high-volume production traffic requirements.
Here are the key building blocks of the eBay Similarity Engine.
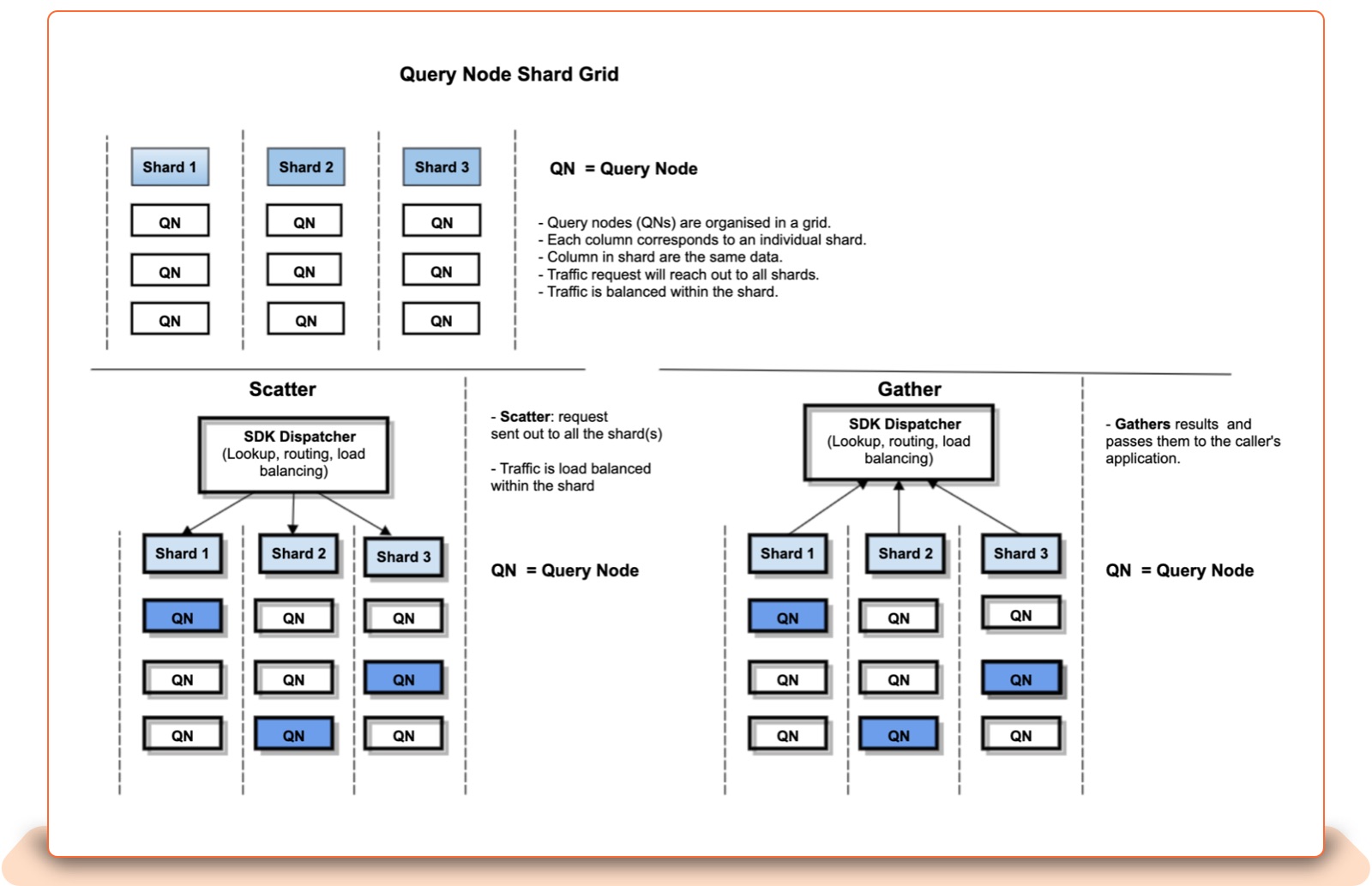
Index Builder: The index builder is a distributed process in which multiple nodes and/or executors are used to create a sharded ANN index. Shards are the basic units of scale here. Sharding allows application memory and CPU resources to be resized by partitioning data into smaller chunks that can be distributed across multiple clusters of query nodes to serve the incoming traffic.
The ingestion service will record submitted index builder requests in the job-metadata store, from which the task scheduler will pick up and manage the distributed index building.
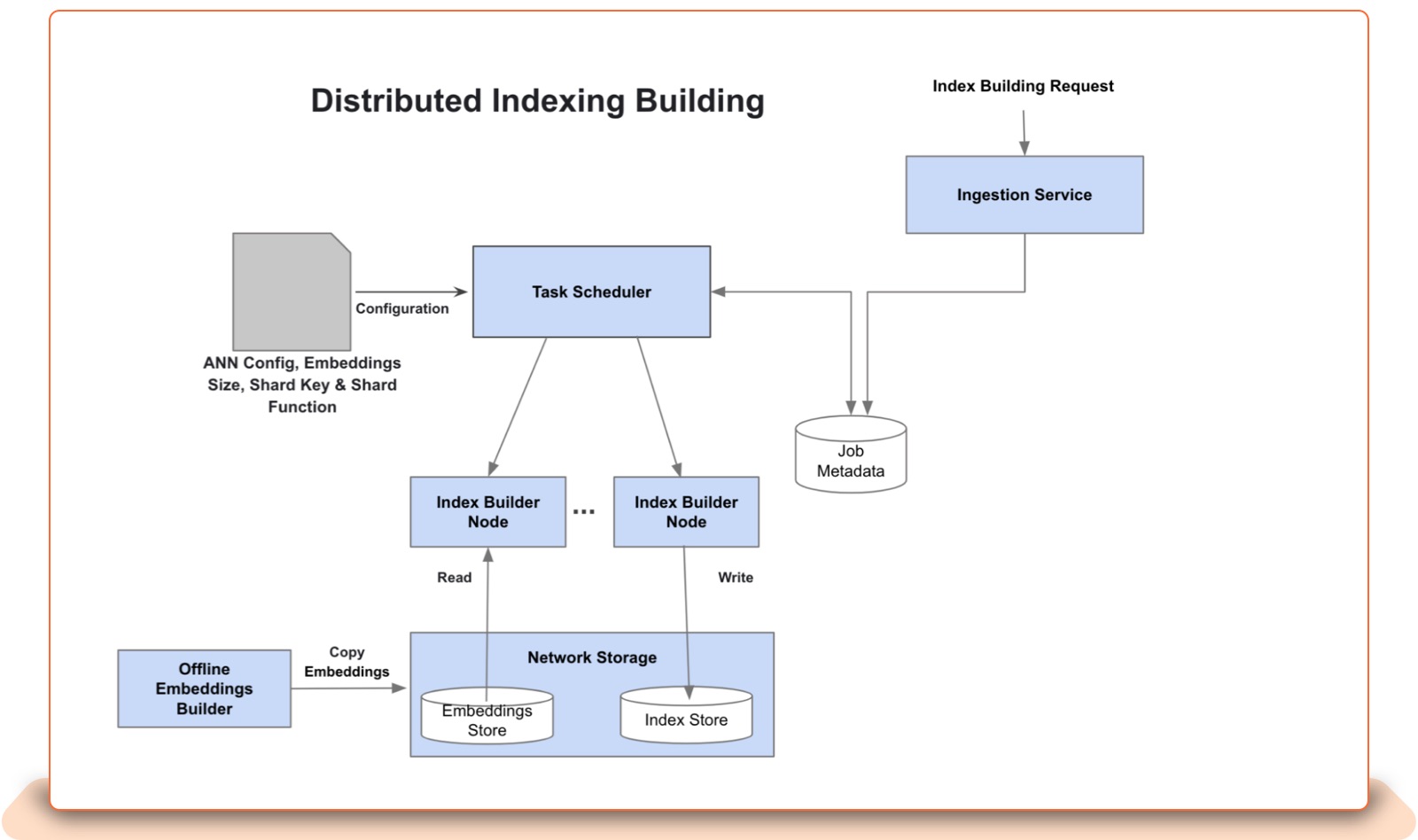
The index builder nodes will partition the input embedding files based on the shard key or clustering algorithm in a pre-processing task called a “shard,” and will build a HNSW or ScaNN index for every shard. The task scheduler will monitor distributed building processes on index builder nodes and restart or reschedule them on a different node if necessary.
Query Node: Once the index shards are created by the index builder and copied to the shared storage, the query node will automatically pick up the newest index according to its timestamp and load it into memory in the background. Following that, it performs a hot swap operation, refreshing the in-memory active index without any downtime.
In order to keep the index up-to-date for near-real-time functionality, query nodes can be configured to periodically pool the similarity engine’s delta service to get embeddings for new or modified listings. Query Node is a high-performance ANN microservice written in C++. For high availability and fault tolerance, the query nodes are replicated on several eBay clusters.
Based on the size of the embeddings files, the Similarity Engine will generate the optimal number of shards. With automatic sharding enabled, the shards will be redistributed in the background, using the least amount of data movement while not interfering with live traffic.
A single shard is replicated on multiple query nodes for load balancing and fault tolerance.
Real Time Updates
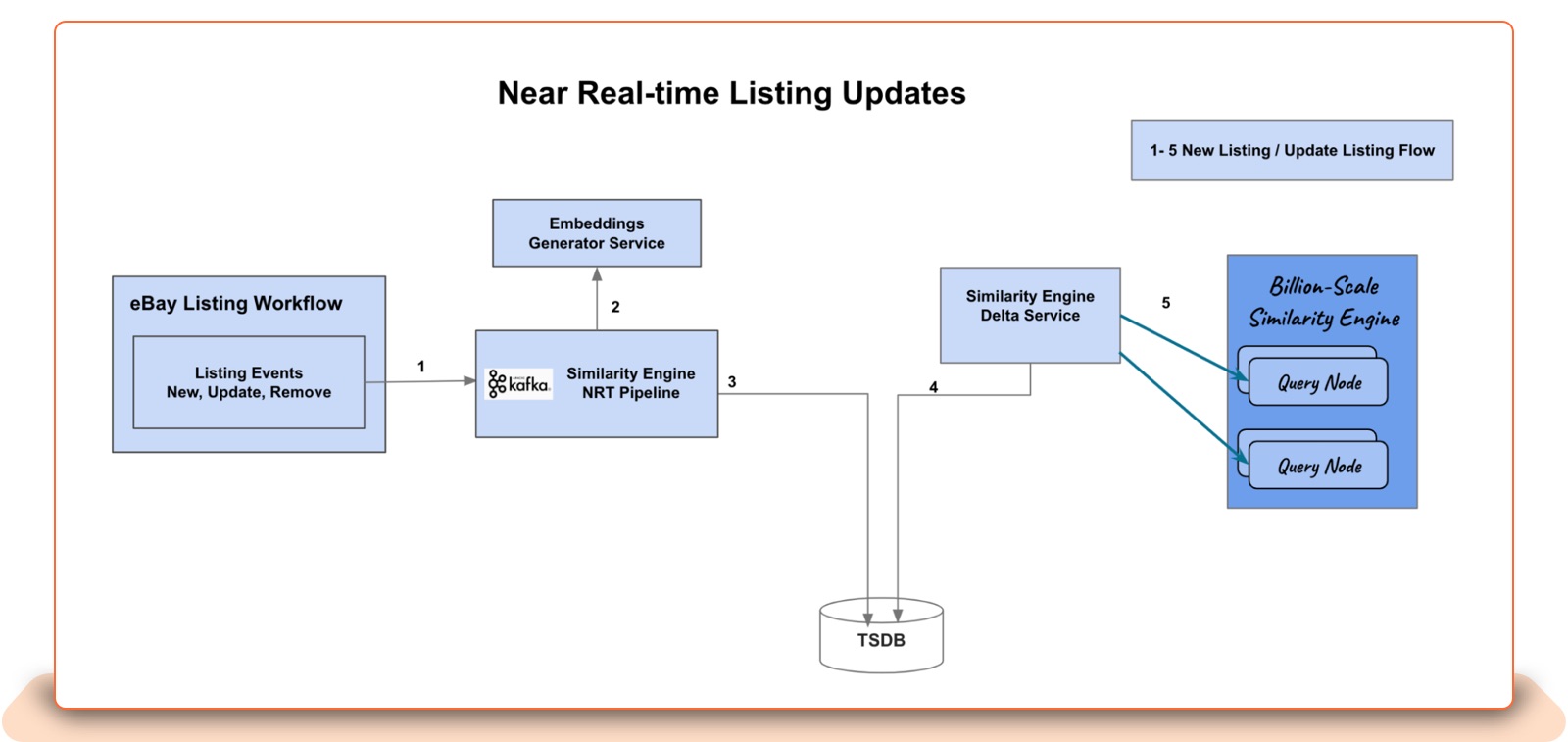
The Similarity Engine supports adding, updating, and removing eBay listings in near-real-time (NRT). eBay buyers and sellers can discover, for similarity, a new item listing or catalog product within seconds.
Add, update, and remove list events are consumed in the NRT pipeline, which will call the embeddings service and record these generated embeddings in a time series database (TSDB). These events are streamed to query nodes, which update their in-memory hnswlib index.
Central Control Plane
The central control plane (CCP) is a pure control plane service that monitors the data plane and is responsible for optimal shard allocation to query nodes. It has the following tasks:
-
It centrally coordinates operational events to orchestrate shard transitions and shard movements of query nodes.
-
It maintains the grid, i.e., the number of shards, and the query nodes (data plane) that load these shards.
-
It collects query node state changes, i.e., query nodes joining or leaving the data plane, and is responsible for redistributing shard allocation on query nodes.
-
It feeds the updated shard grid information to the Ingest Gateway for traffic routing and load balancing.
CCP has deployed multiple replicas for high availability and is not the critical path for serving the traffic, since its primary job is to have grid information available to SDK. Applications can continue to function in degraded mode with existing shard allocations if CCP goes down.
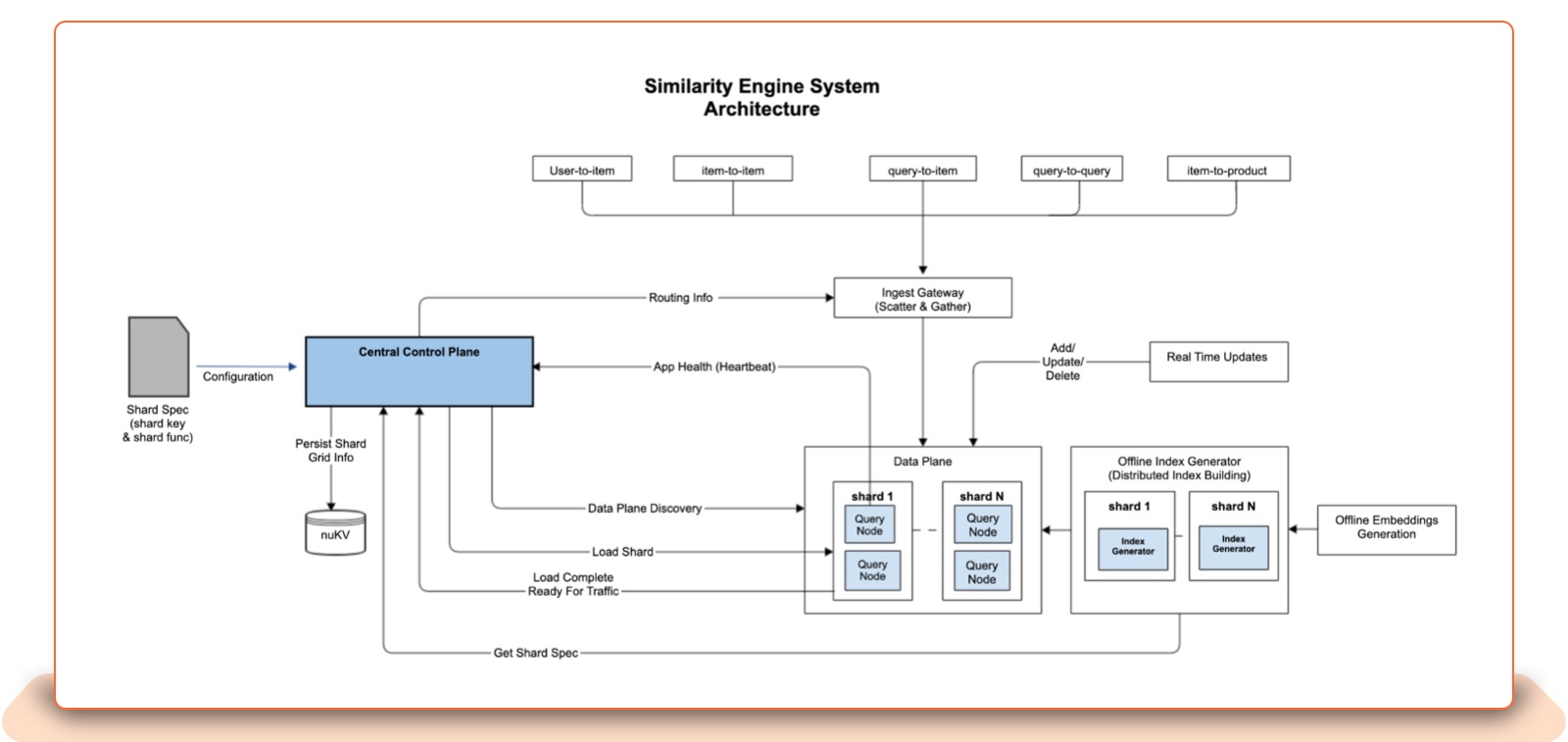
Ingest Gateway
The Ingest Gateway provides a set of simple and expressive high-level APIs to hide the low-level execution details from the listing service. It uses the shard grid configuration from the Central Control Plane (CCP) to dispatch similarity lookup requests to all shards. Each shard’s results are combined into a single response ranked by distance matrix and returned to the listing service.
The Ingest Gateway is also in charge of load-balancing the traffic between query nodes that hold the same shard index. The Ingest Gateway is required to keep the shard grid in sync with the CCP.
ANN Backend Evaluation For eBay Dataset
This section presents our benchmarks of various performance characteristics for ANN backends used in the Similarity Engine.

Before we can run a similarity lookup, we need to build an index. Index build time depends mostly on embedding size and the total number of records, but also on some backend-specific parameters. These parameters have an impact on performance characteristics such as search quality and query latency.
HNSWLib
In HNSWLib, “M” represents the number of edges for each node in the graph. Higher values improve accuracy and run time, but use more memory. We also indicate “ef /efConstruction,” which represents the size of the dynamic list for the nearest neighbors (used during the search).
ScaNN
Several parameters, like sample size or iterations used in partitioning, affect build time but aren’t presented here, as using non-default values does not change other performance characteristics significantly.
The following analysis plots show the trade-off between index size (total number of records), memory usage, and embedding size for HNSWLib and ScaNN. The plots have names that include the ANN backend name and parameters. For example, hnswlib_m16efC200_q8 means hnswlib index with M = 16, efConstruction = 200, and 8-bit data quantization. scann_d64_f32 means ScaNN index built on full precision (32-bit) data, where vectors are 64-dimensional.
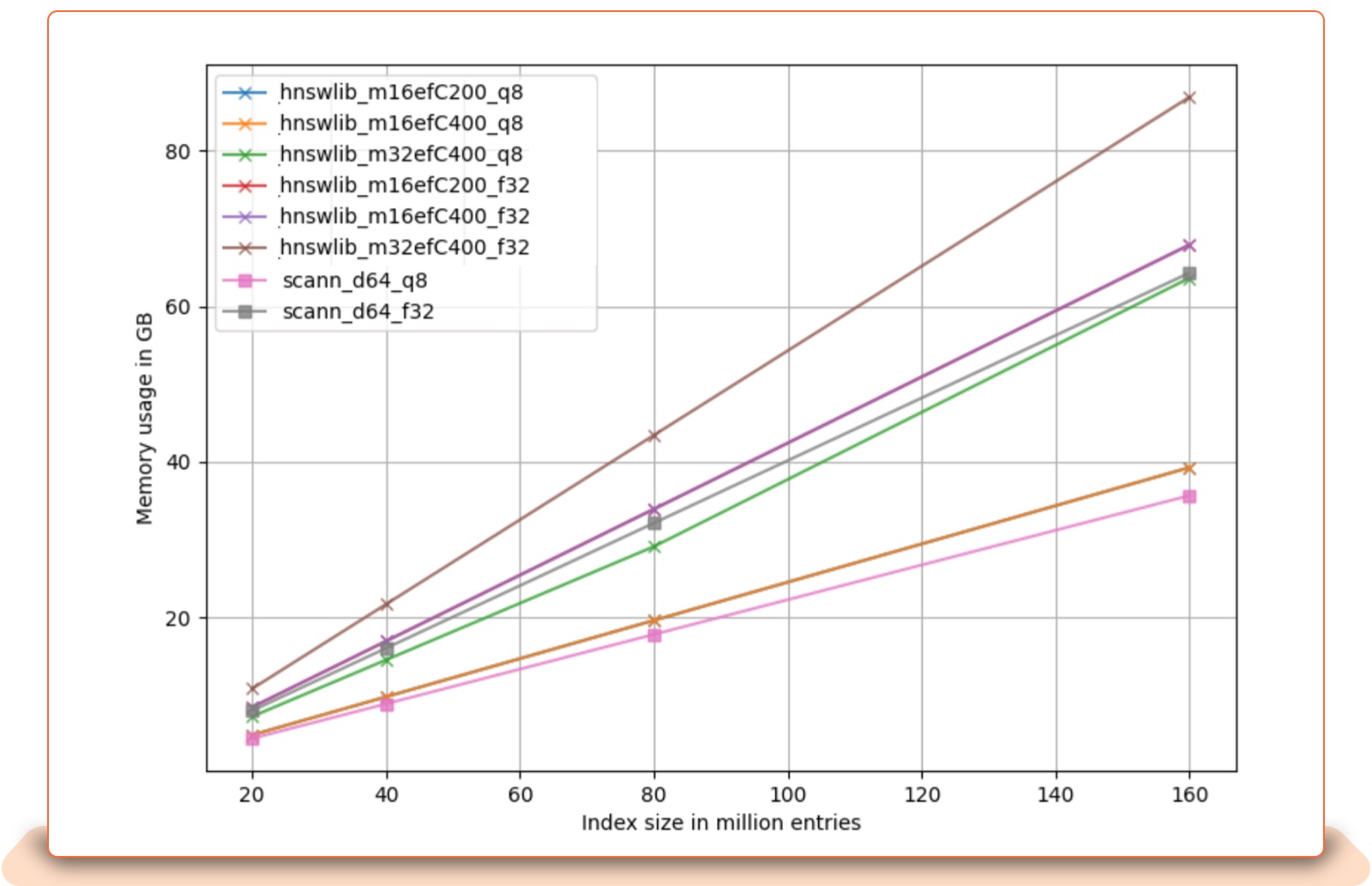
Memory usage vs index size: Memory usage grows linearly with index size. Using 8-bit quantized data uses a lot less memory than full precision (32 bits). Both ScaNN and HNSWLib use similar amounts of memory on tested index sizes.
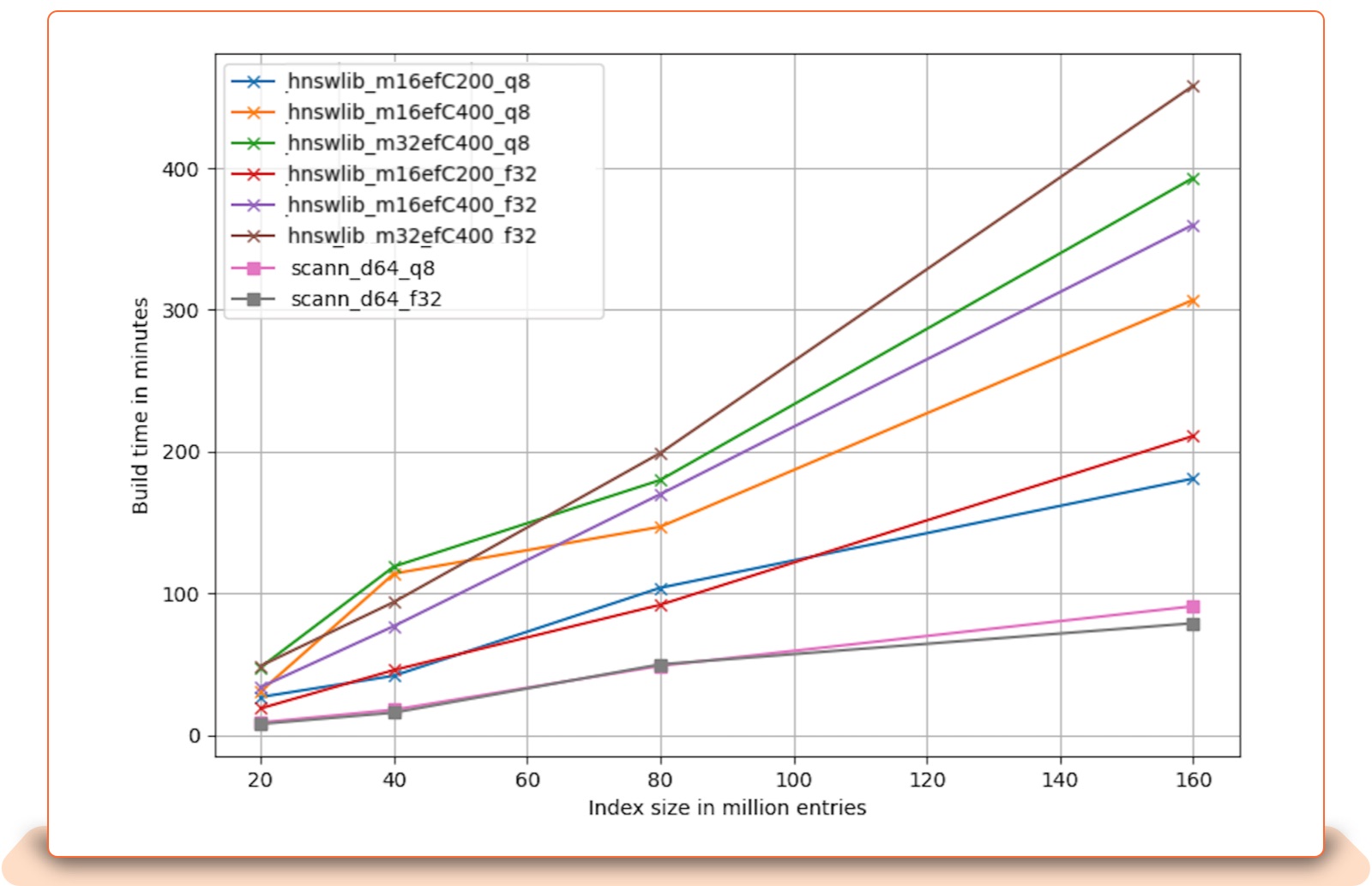
Index Size vs Index build in minutes: ScaNN usually has a faster build time for most index sizes.
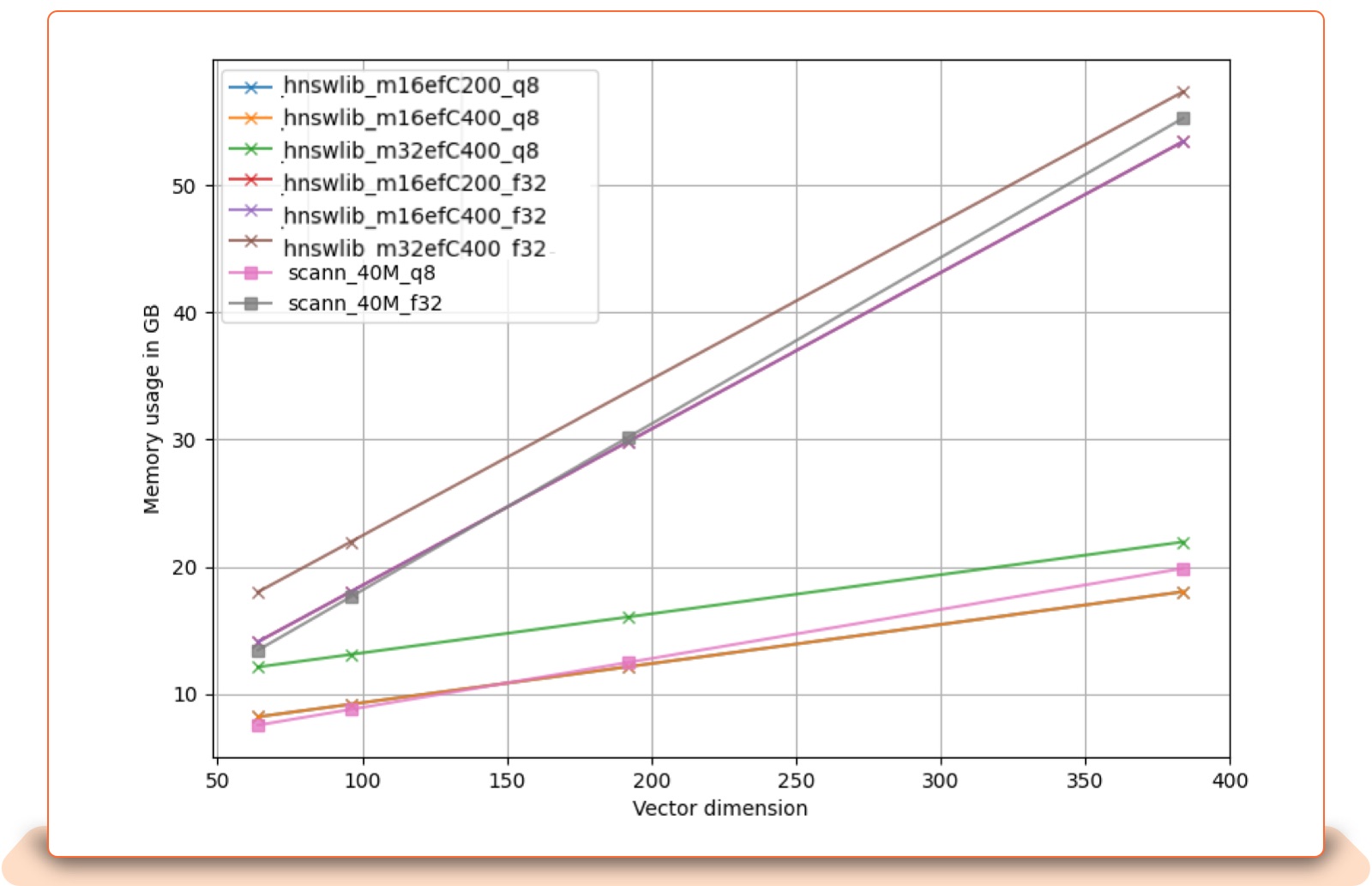
Vector Dimension vs. Memory Usage: This plot shows memory usage for a 40 million listings index against dimensionality. Memory usage grows linearly with vector dimensionality. HNSW has a better tradeoff with large vectors.
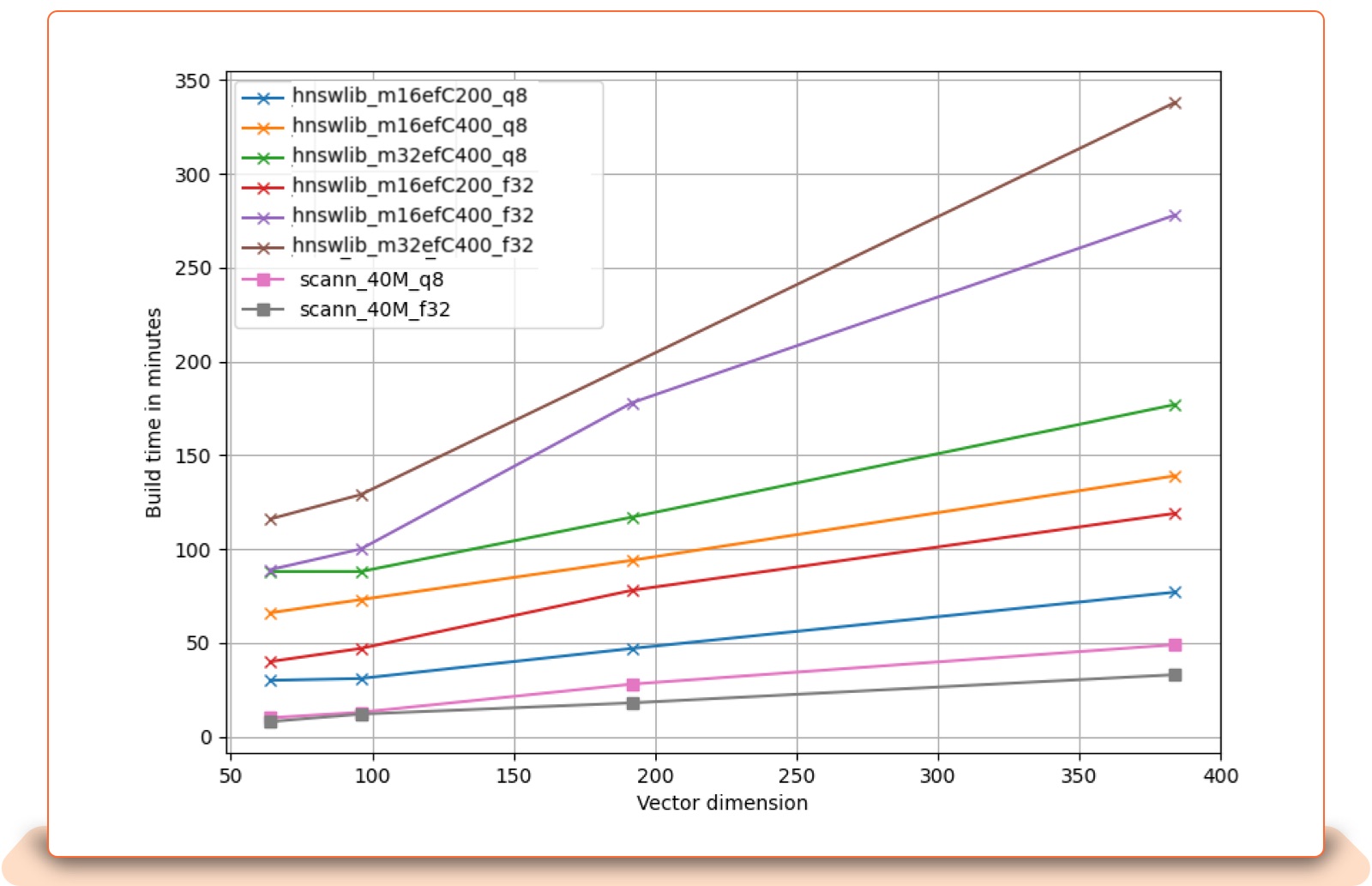
Vector Dimension vs Index Build time: Data dimensionality influences speed and quality, as well as build time and memory usage. Both memory usage and build time grow linearly with vector dimensionality. HNSW has a better tradeoff with large vectors, while ScaNN does better with index build time.
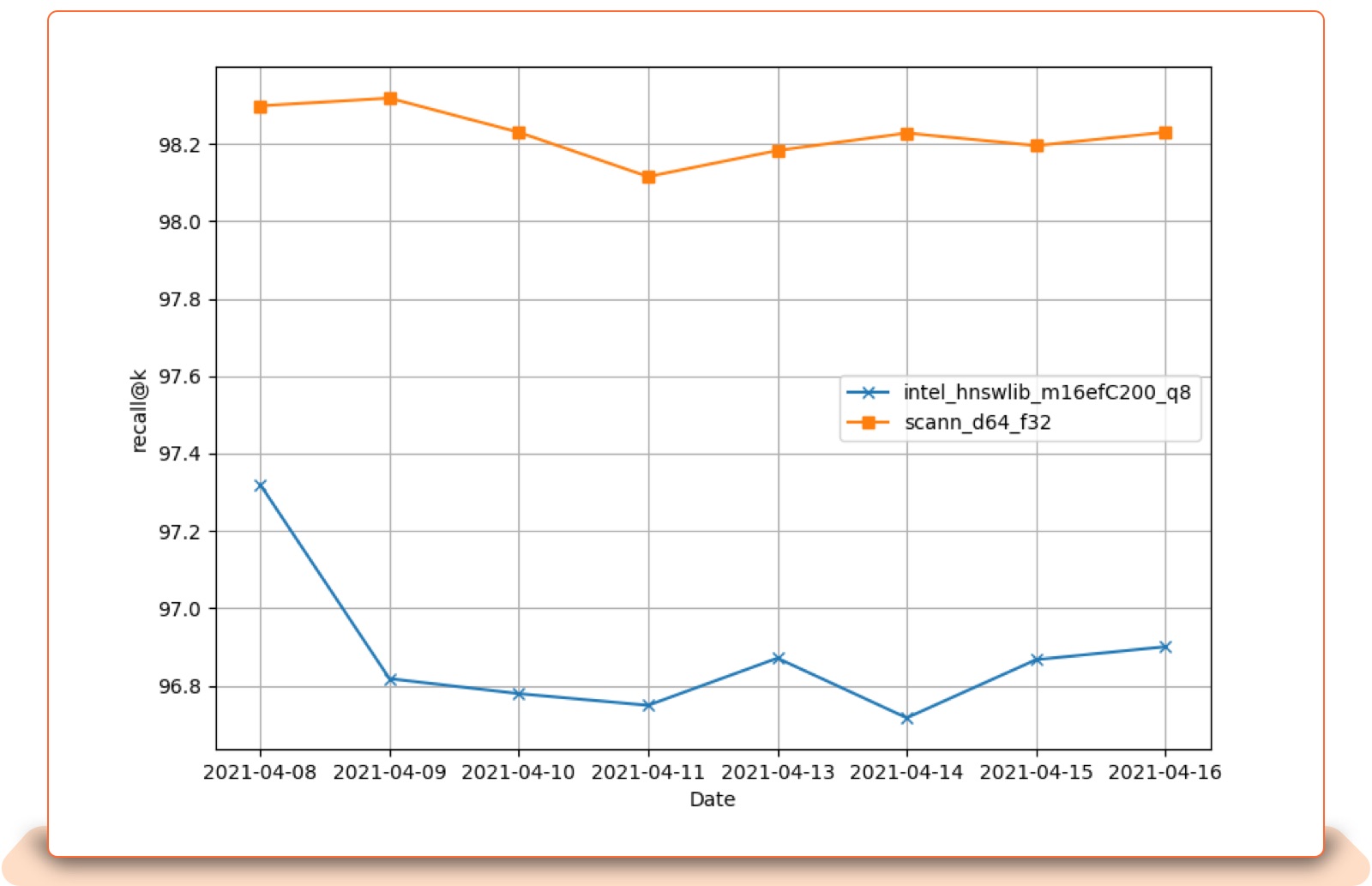
NRT Dynamic Updates to HNSWLib and ScaNN: A ScaNN index typically loses less recall over time and does not require special maintenance. HNSWLib requires periodic maintenance of the index to maintain high recall. With ScaNN, it is important to set the maximum index size in advance to avoid expensive memory reallocation.
Top k-nearest neighbors
Here we show a single core accuracy/speed tradeoff for various values of top k on an eBay 20M Listing dataset.
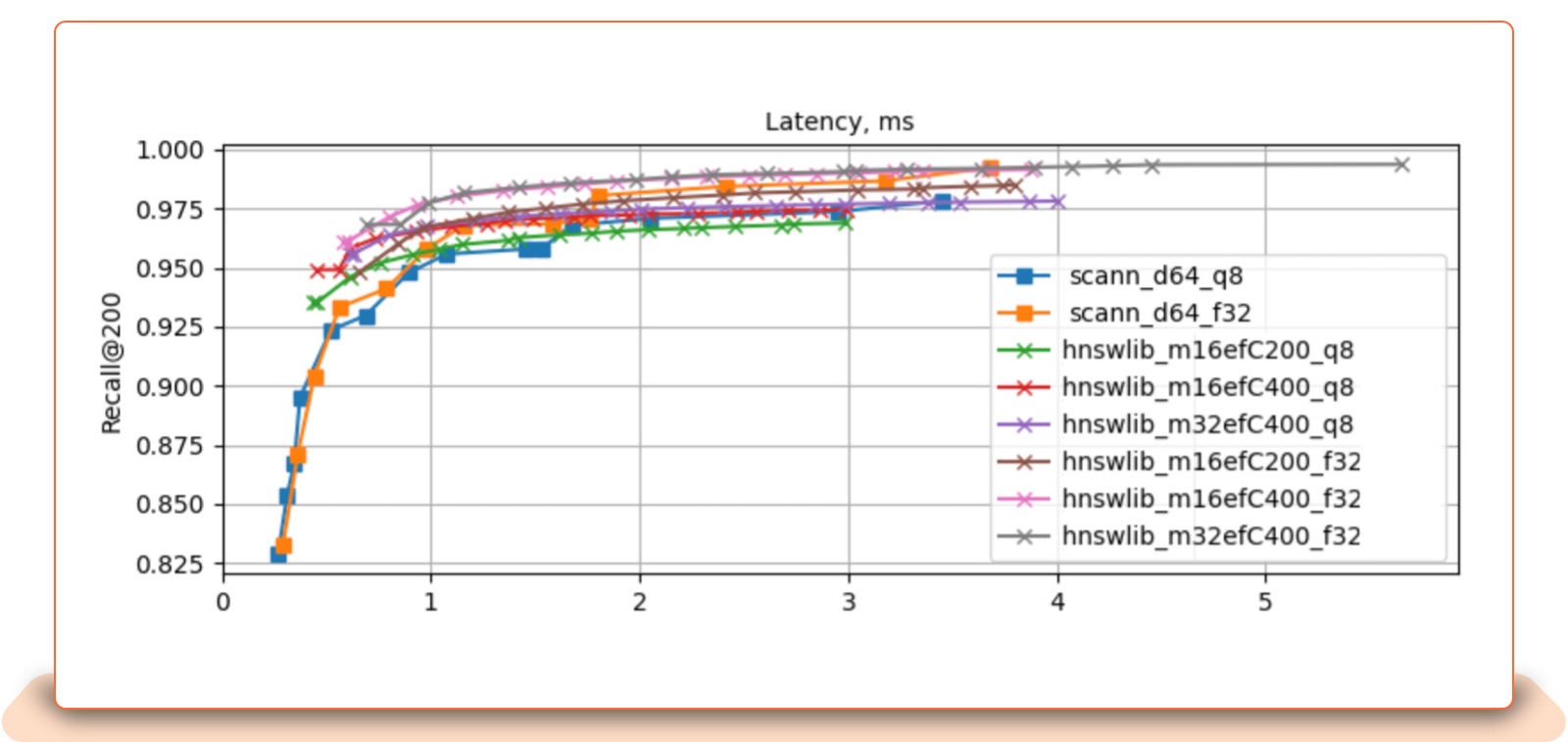
Top k Recall vs Latency: With top k increased, HNSWLib becomes slower because of efSearch (the size of the dynamic list for the nearest neighbors, used during the search), which leads to higher search accuracy at the cost of longer search time. However, it does not lose quality.
Top k Recall vs Latency: With top k increased, HNSWLib becomes slower because of efSearch (the size of the dynamic list for the nearest neighbors, used during the search), which leads to higher search accuracy at the cost of longer search time. However, it does not lose quality.
ScaNN does not have a significant slowdown; however, rescoring with full precision becomes a bottleneck with a large top k.
Similarity Engine Attribute-Based Filters
Similarity engine search techniques allow massive datasets with billions of vectors to be searched in mere tens of milliseconds. Yet despite this achievement, what seem to be the most straightforward problems are often the most difficult to solve.
Filtering has the appearance of being a simple task, but in practice it is incredibly complex. Applying fast yet accurate filters when performing a vector search (i.e., nearest-neighbor search) on massive datasets is a surprisingly stubborn problem.
Restricting the similarity scope to relevant vectors is an absolute necessity for providing a better customer experience. The simplest approach is post-filtering, which involves removing results that do not meet our filter conditions. Post-filtering is applied to top-k returned recalls. This leaves us with fewer results than the client requested. Unfortunately, with multiple filter conditions, recall suffered further, potentially returning zero results in the case of multiple strict conditions. We can eliminate the risk of returning too few (or zero) results by increasing k to a high number. But doing so increases lookup latency for excessively high-K searches.
The better solution compared to post-filtering is inline “attribute-based filtering.” This section explains the similarity engine’s “Attribute-Based Filter,” which will apply filter criteria to the nodes of the graph and use in the greedy search only those that meet these criteria.
Experiments: Filter-Aware HNSW Search
The following section covers one of the experiments we conducted on the eBay Ads dataset. Inline metadata filtering works by merging the vector and metadata indexes into a single index.
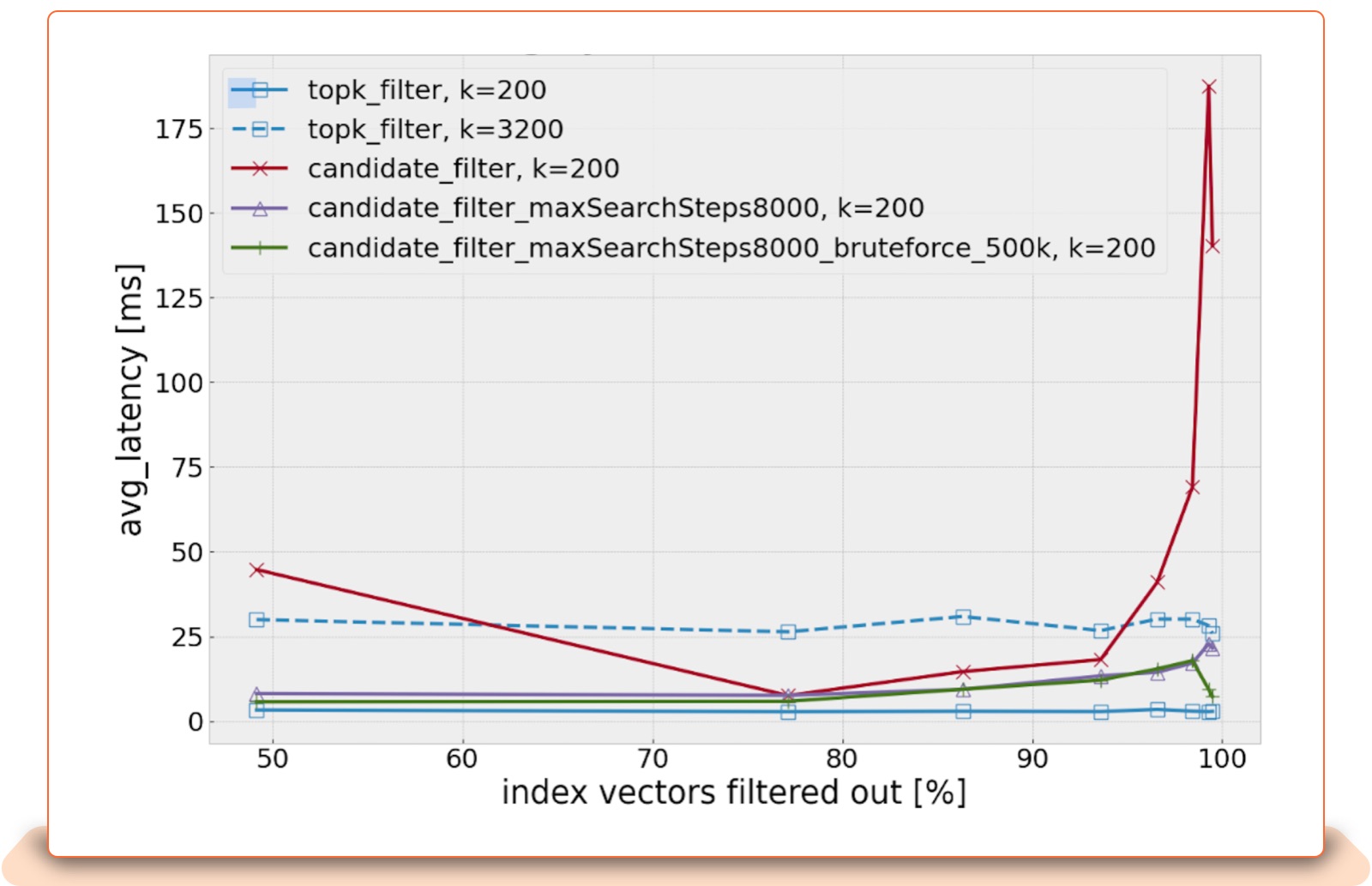



Acceptable latencies throughout: ☺
Latency Spikes
candidate_filter, k=200: With the restrictive filters, search becomes more and more exhaustive, which spikes the search latency.
candidate_filter_max_SearchSteps800, k=200: Places an upper bound on the number of search iterations which will limit exhaustive search.
candidate_filter_max_SearchSteps800_bruteforce_500k, k=200: upper bound on the number of search iterations Falling back on brute-force search for restrictive filters performs very well.
Summary
The Similarity Engine is able to solve any embedding or vector retrieval task, wherein the embeddings can represent any entity, including images, text, items, users, queries and more.
Deployment of the Similarity Engine for a specific use case requires resource scaling based on embedding size, corpus size and the number of requests per second it serves.
Attribute-based filtering allows for adding multiple conditions during the query, which improves relevance. It eliminates the risk of returning too few (or no) results and high latency from excessively high-K searches, as seen with post-filing.
The Similarity Engine’s performance can be measured in terms of latency, throughput (queries per second), build time and accuracy (recall). These four components frequently have tradeoffs, so choosing the optimal method depends on the use case.
Finally, the Similarity Engine has been successfully adopted by several product teams at eBay, generating millions of dollars in revenue per year. There are currently a total of 13 indices that the similarity engine is serving in production for item-to-item, query-to-item, query-to-query, and user-to-item (personalized recommendation) that support multiple modalities (text and image). The index consists of 1.7 billion all-active listing embeddings, making it the biggest index in terms of number of records and returning the top k=200 nearest neighbor items within 12 milliseconds at the 95 percentile for item-to-item similarity and user-to-item (personalized recommendation).
Acknowledgements
This work would not have been possible without support of Nitzan Mekel, Kopru Selcuk, Henry Saputra, Yuri Brovman, Arman Uygur, Sathish Veeraraghavan, Sriganesh Madhvanath, Zhe Wu,Suman Pain, Ashwin Raveendran, Sami Ben-Romdhane as well as eBay Ads team and Search team members.
References
[1] Yu. A. Malkov, D. A. Yashunin: Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs (https://arxiv.org/abs/1603.09320)
[2] Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, Sanjiv Kumar: Accelerating Large-Scale Inference with Anisotropic Vector Quantization (https://arxiv.org/abs/1908.10396)
[3] Y Malkov, A Ponomarenko, A Logvinov, V Krylov: Approximate nearest neighbor algorithm based on navigable small world graphs (https://www.sciencedirect.com/science/article/abs/pii/S0306437913001300)
[4] Yuri M. Brovman : Building a Deep Learning Based Retrieval System for Personalized Recommendations (https://tech.ebayinc.com/engineering/building-a-deep-learning-based-retrieval-system-for-personalized-recommendations)
[5] Qdrant: Filterable approximate nearest neighbors search (https://blog.vasnetsov.com/posts/categorical-hnsw/)
[6] git repo Hnswlib – fast approximate nearest neighbor search (https://github.com/nmslib/hnswlib)
[7] Liying Zheng, Yingji Pan, Yuri M. Brovman, Page-Wise Personalized Recommendations in an Industrial e-Commerce Setting, ORSUM Workshop at RecSys 2022 [paper]


