
One of eBay’s consistent struggles, one common to all ecommerce platforms, is catching cyber attacks. These include, but are certainly not limited to, account take-overs, collusions, money laundering and more. Violations like these can cause financial or non-material loss to our buyers and sellers, as well as to eBay as a company. For this reason, real-time data-driven risk control has been a vital part of the eBay platform for over two decades.
From a tech perspective, risk control is a comprehensive system consisting of many components that extend to and integrate with virtually all business processes, such as item listing, item viewing, checkout and payment processing. From a business perspective, risk control involves not only engineers who build such capabilities, but also analytics teams who investigate risk incidents, analyze risk trends, design risk policies and deploy rules and configurations using the infrastructure.
At the core of this infrastructure is our “Decision Engine.” It acts like a judge in a legal system to determine whether certain user behaviors are risky or not according to prescribed rules, and then sends out “pass” or “block” actions for execution. Technically, its function is similar to what a CPU contributes to a computer: it evaluates risk policy rules (like CPU instructions) prescribed by analytics teams (like software programmers) with various input data (like i/o read) integrated, and executes actions (like i/o write).
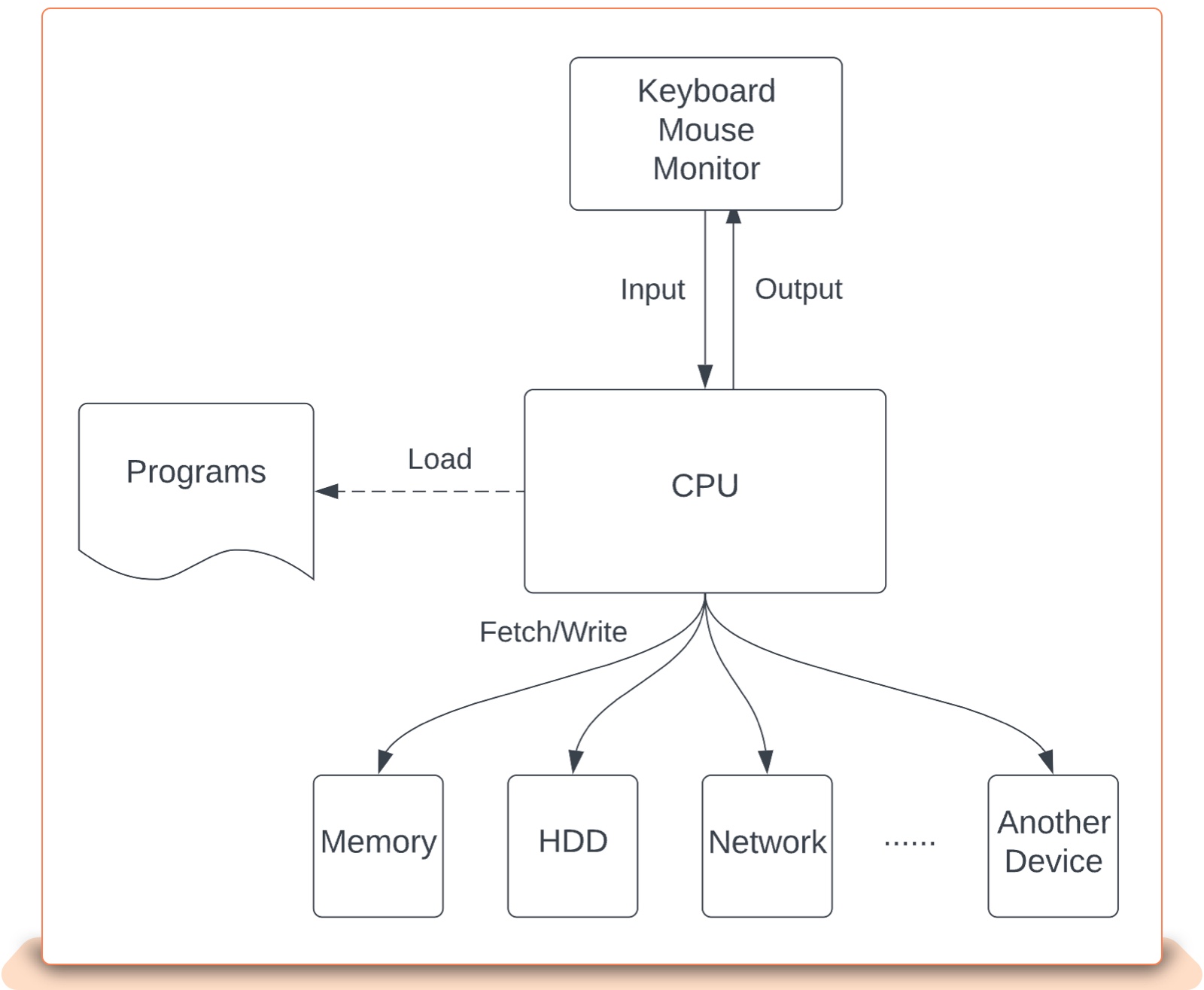
Fig. 2: Computer system architecture from a user’s perspective
As a result, the risk decision engine architecture (Fig. 1) is similar to that of computers (Fig. 2). A major difference, though, is that risk data source integration is far more complex than a computer. There are only a few types of I/O devices (memory, SATA devices, PCI devices, that kind of thing) with standardized access protocols. However, risk data sources are vast: There are hundreds of databases with various data structures and schema, and thousands of business domain services with arbitrary request/response payload structures. All such disparate data, at the granularity level of data fields, need to be integrated with and understood by the decision engine. For this reason, a per-source integration is needed, in order to make sure each data source can work correctly.
On the other hand, the performance requirement of data integration is very strict. Typically, a risk evaluation request from an upstream business application needs to be processed and completed within a few hundred milliseconds. On average, a risk evaluation request will kick off the execution of hundreds of rules. Each rule will take in between five and around 20 variables (the standard data unit in decision engine) from various data sources through the data integration mechanism. Even if we subtract duplicate variables across multiple rules, the net number of total variables needed for a risk evaluation request can still exceed 100. This means, we need to complete data fetching for the 100-plus variables from various data sources within a few hundred milliseconds. We cannot, though, simply fetch these 100-plus variables all at once in parallel, due to multiple limitations of thread resource, inter-variable dependencies, rule execution sequence and more. All this means is that an efficient and performant data integration is critical to the success of risk decisioning.
For simplicity’s sake, the data integration mechanism has long been embedded inside the decision engine as a big Java package called Rule Business Objects, or RBOs. As illustrated in Fig. 3, variables are encapsulated in hundreds of concrete RBO classes as getter methods. Each RBO class typically integrates in a dedicated way with a data source, containing all necessary code and dependency packages, for purposes like initialization, network connection management, threading, serialization/deserialization, payload parsing and more.

Fig. 3 Decision data integration mechanism
This direct embedded integration pattern served its purpose well when risk rule policies were relatively stable and new variables were introduced gradually. However, as eBay’s risk policies started to accelerate, especially since the launch of eBay managed payment, more and more variables began to need to be integrated, with more stringent time requirements. We started to see a series of significant challenges:
-
Introducing a new variable or data source implies code change in the RBO, and thus a full development cycle of the decision engine, including design, coding, QA, review, deployment, monitoring and more. This can take anywhere from a few weeks to a few months, consuming a substantial amount of development effort. As a result, our risk analytics team cannot deploy their new rules in time to stop risky activities sooner.
-
Making code changes can introduce bugs. The dependency packages pulled in as a result of code changes can also cause conflict or other unexpected problems. A serious production issue, such as memory leak or thread leak, can even halt the rule execution core, causing downtime of the entire decision engine. As a result, the entire decision engine becomes more and more fragile.
Aside from these productivity-related challenges, governance problems also emerge. With thousands of variables integrated over years, it becomes difficult to search and identify the specific ones that users need. Over time, we lose track of each variable’s profile, which includes details like why it was introduced, what the data source is, what cleansing is applied and more. Nor is it easy to rebuild the profiles, since most of the facts about the variables were baked into the RBO Java code, often in a convoluted way that is hard to understand.
Refactor: Variable Hub as Data Access Layer
In order to address the aforementioned challenges, and for the long term scalability of the risk decision platform, we decided to refactor it. The direction we chose involves decoupling data access/integration from the decision’s rule execution core. Fig. 4 illustrates the idea.
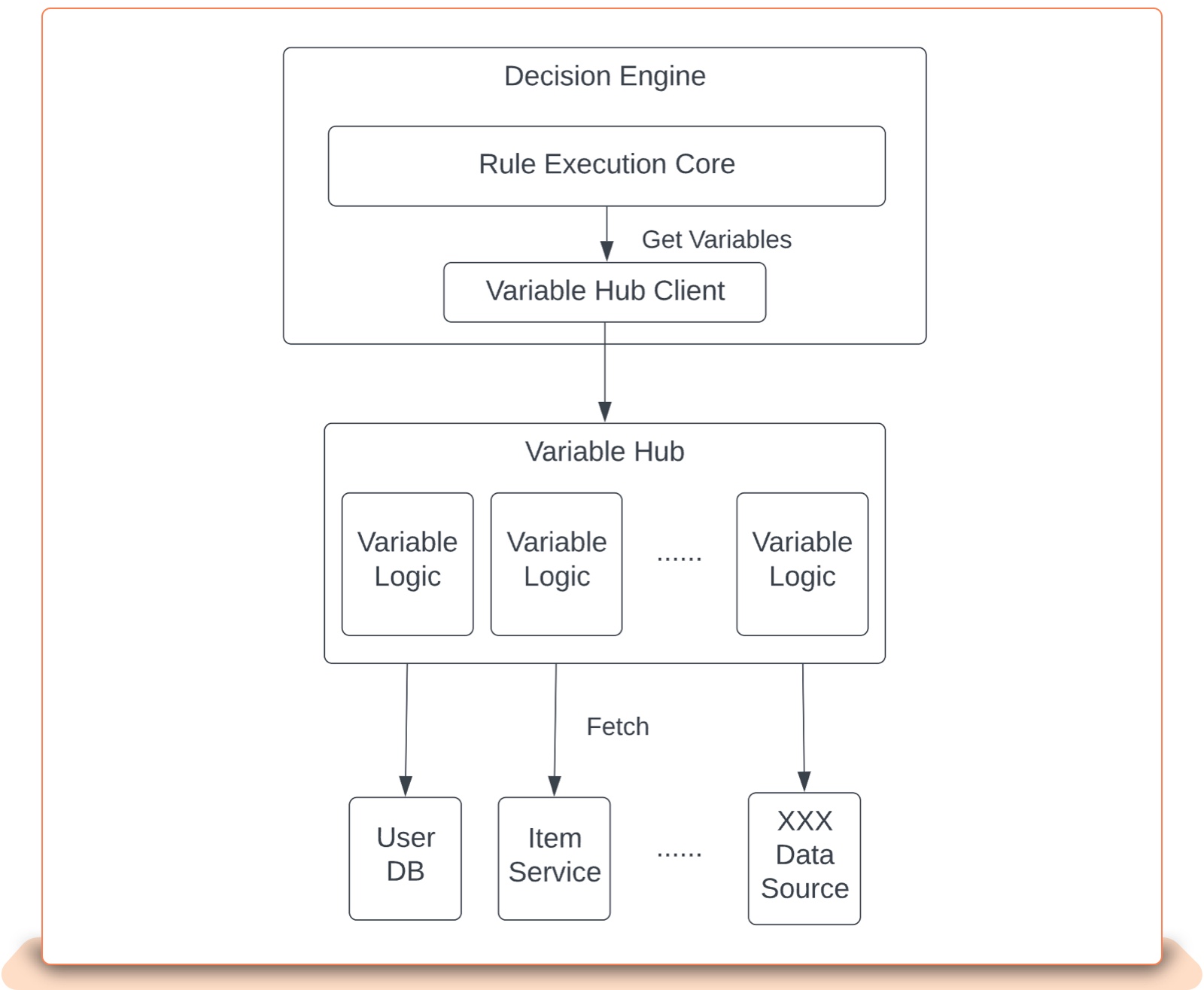
Fig. 4 Decoupling data access from decision engine
By moving out the heavy-duty data integration part from the decision engine, and placing it in a dedicated application which we call Variable Hub, we can address several challenges:
-
Introducing new variables or new data sources only needs to make changes on Variable Hub, but not on the Decision Engine. This can avoid the complex and time-consuming upgrades of the decision engine. Variable Hub only contains integration related code, so it is much lighter and easier to upgrade. This certainly can reduce development effort as well as time-to-market to a great extent. Essentially, we are splitting the all-in-one application into two separate ones with independent maintenance paths.
-
Any potential production bugs introduced by new variables will only affect Variable Hub and will not spread to the Decision Engine. This, although it cannot eliminate all issues, does minimize impacts whenever some system exception occurs. A lighter application also means a lower cost to reinforce and maintain.
This is a good starting point to make the decision ecosystem more scalable. However, refactoring is like shifting from a lower gear to a higher one. As we keep adding new variables’ Java code, the overall complexity of the Variable Hub application will still keep growing. Sooner or later, we will reach a point where we will encounter the same challenges again.
To prevent us from falling victim to this persistent pitfall, we need a fundamentally different approach.
Variable Integration Pattern
If we look back at the history of computer application software, especially those more relevant to our daily lives, we’ve seen a major migration from offline software to online. What used to be a Windows desktop application, for example a personal contact manager or even a rich-text word processor, can now be replaced with a web application powered by HTML and Javascript technologies. After all, most applications do not require fancy visual effects nor extreme performance. Dynamic languages like HTML and Javascript can easily suffice for such duties. Most importantly, they are fast to develop, easy to modify and eliminate the need for annoying installations or upgrades.
We investigated a large number of existing variables by studying their underlying data integration Java code. It turns out that, to our delight, more than 95 percent consist of logic that falls into a small set of common operations. They tend to:
-
query a SQL-based database
-
query a RESTful service
-
extract data fields from the query result
-
apply some common formatting or manipulations, such as datetime conversion, string processing, etc.
-
apply some arithmetic operations
-
apply conditioning, branching and looping operations
Using a feature-rich object-oriented programming language like Java to code simple logic like the above repeatedly for each variable is surely overkill, considering the heavy workflow needed for such languages, including steps like class hierarchy design, git branching and merging, peer code review, rigorous CICD, packaging, deployment & monitoring. Like web applications, adopting some dynamic script to represent such basic operation combinations would give us great yields at low cost, because we can eliminate these steps.
We started from that point, but that brings us to the next question, which is: Which scripting language should we choose? Well, before we start the hunting, there are a few criteria that must be met for our purpose, among which three are particularly important:
-
It must be JVM compatible, since our container Variable Hub is a Java application.
-
It must be a dynamic language, meaning that no compilation is needed. And it can be hot loaded or unloaded freely without leaving footprints.
-
Its functionalities must be limited to only the above operations. Users should not be able to write scripts that can affect system stability or performance. The language must not include anything like memory allocation, thread creation, process termination and the like.
These criteria filter out virtually all options and leave us with few candidates. In the end, we decided to design and implement a Domain Specific Language (DSL) by ourselves. This gives us full freedom and controllability to make the scripting language suitable. DSL, though, is a separate big topic, so we will not discuss its details in this article.
With this new approach, our architecture changes (Fig. 5):

Fig. 5 Adopting DSL for variable logic
Variable Hub will not need frequent upgrades, as long as we make sure the in-house DSL engine is stable. Of course, variable logic scripts must be correctly written and thus validation is needed before being loaded. But we could offer separate tools for users to do such validation in non-runtime environments.
Performance Optimizations
As we mentioned in the beginning of this article, performance is vital. A typical risk evaluation, which can involve 100-plus variables, needs to be completed within a few hundred milliseconds. Most variables will incur network round trip latency in order to fetch data from various data sources. Depending on the nature of the source, such latency can range from ~20ms to ~100ms.
If variables are fetched sequentially, 100 variables times 20ms/variable will give us 2,000ms of total latency for the rules to get all needed data. This is, unfortunately, unacceptably slow. Of course, there is some, although not full, degree of parallelism in the decision engine so that multiple variables are fetched simultaneously. Also some variables share the same data source, so the real situation is not that bad. But still, the longest thread can involve 10 to 20 network fetching operations, which means 200 to 400ms of total processing time. This barely meets the “a few hundred milliseconds” evaluation response latency requirement, and we do not have much time left for rule execution and downstream data source processing.
The challenge lies in the fact that, by sitting between the Decision Engine and data sources, Variable Hub introduces an extra network hop and thus some extra latency overhead. This overhead will be further amplified by roughly 10 to 20 times (the longest thread). So if we cannot make this overhead sufficiently small, we will not be able to secure the overall latency performance we’re looking for.
Since network hop is inevitable, our focus is to minimize network protocol stack overhead, especially the application layer. RESTful API is based on HTTP 1.x which uses plaintext for session establishment and data transmission. Additional overhead is incurred for payload serialization and deserialization.
Fast Connection Through gRPC
gRPC is a popular high performance Remote Procedure Call (RPC) framework, open-sourced from Google. It uses HTTP/2 as its transport protocol and Protobuf as its payload encapsulation format. HTTP/2 is binary, fully multiplexed, and uses header compression. Protobuf also uses binary encoding as opposed to textual. The combination makes gRPC a great framework for performance oriented inter-microservice connections.
This suits our need perfectly, since the connection between the Decision Engine and Variable Hub is similar to microservices: request/response pairs are dense but small, just containing variable names, keys and results.
Another advantage is that HTTP/2 is not supported by many hardware load balancers (LB), which are commonly used in many data centers. So we had to design and implement a software load balancing mechanism. But why is it an advantage? Wouldn’t that incur more work for the software LB? Well, let’s take a look at the architecture first:

Fig. 6 REST hardware LB vs gRPC software LB
As you can see, we adopt a distributed config registry for reliable service discovery. The end-point selection and switching happens on the client side. The open source gRPC client keeps an internal name resolver that can be customized to synchronize with the registry.
But the gRPC connection is direct, whereas the hardware LB is essentially another network hop. For this reason, using gRPC, we can achieve even better latency performance. In our case, as we tested, an intra-datacenter request/response takes 2 to 5ms using gRPC, compared to 10 to 20ms using REST via LB.
With this, the overall latency overhead can be reduced to only 20 to 30ms. Given the multiple hundred millisecond budget, the overhead becomes negligible and negates our concern over latency performance.
Yet another challenge arises: As we briefly mentioned above, many variables share the same data source, so in the old days before the refactoring, such data sources’ responses were cached inside the Decision Engine so that only one query was performed to avoid unnecessary overhead and downstream load. Since variable logic scripts now live in Variable Hub, naturally we would like to have an in-memory caching mechanism as well, to bring the performance up to par.
However, since Variable Hub is parallelized for scalability, the source-sharing variables may not be directed to the same instance. Let’s take a hypothetical. Variable A is directed to Variable Hub instance 1, which in turn queries the data source, caches the response on instance 1, then does some massaging and returns the result back to the Decision Engine. Moments later, variable B, which shares the same data source, is directed to instance 5 (due to load balancing). Unfortunately, instance 5 does not have the data source response cached. This means we will have to make another redundant query to the data source.
One may propose using a distributed cache such as Redis to solve this. Sadly, though, this again means another network hop for cache writing/reading, and its overhead may offset the data source latency we are trying to save.
Another idea we considered was cache synchronization between Variable Hub instances. Contrary to our hopes, caching writing is also another network hop which causes delay. This makes it very difficult to know the precise timing of cache availability across a large number of instances, let alone the daunting complexity of implementation.
Sticky Session Based on gRPC
The best approach to solve this problem is to direct variables sharing the same data sources to the same instance. Since variables only share something within the same risk evaluation request and not across, we could simplify the approach: Direct variables associated with the same risk evaluation request (identified by a request ID) to the same instance. For scalability and fault tolerance, variables from different risk evaluation requests should still be directed to different instances. We call such a mechanism “sticky session.”
In the HTTP 1.x / REST world, this is difficult to achieve, because hardware LB is in charge of the routing and we have little control over it.
Once again, gRPC comes to save us. The nice customizability of the open source gRPC client gives us an opportunity to swap in an endpoint selection mechanism for our needs. Fig. 7 illustrates our routing algorithm.
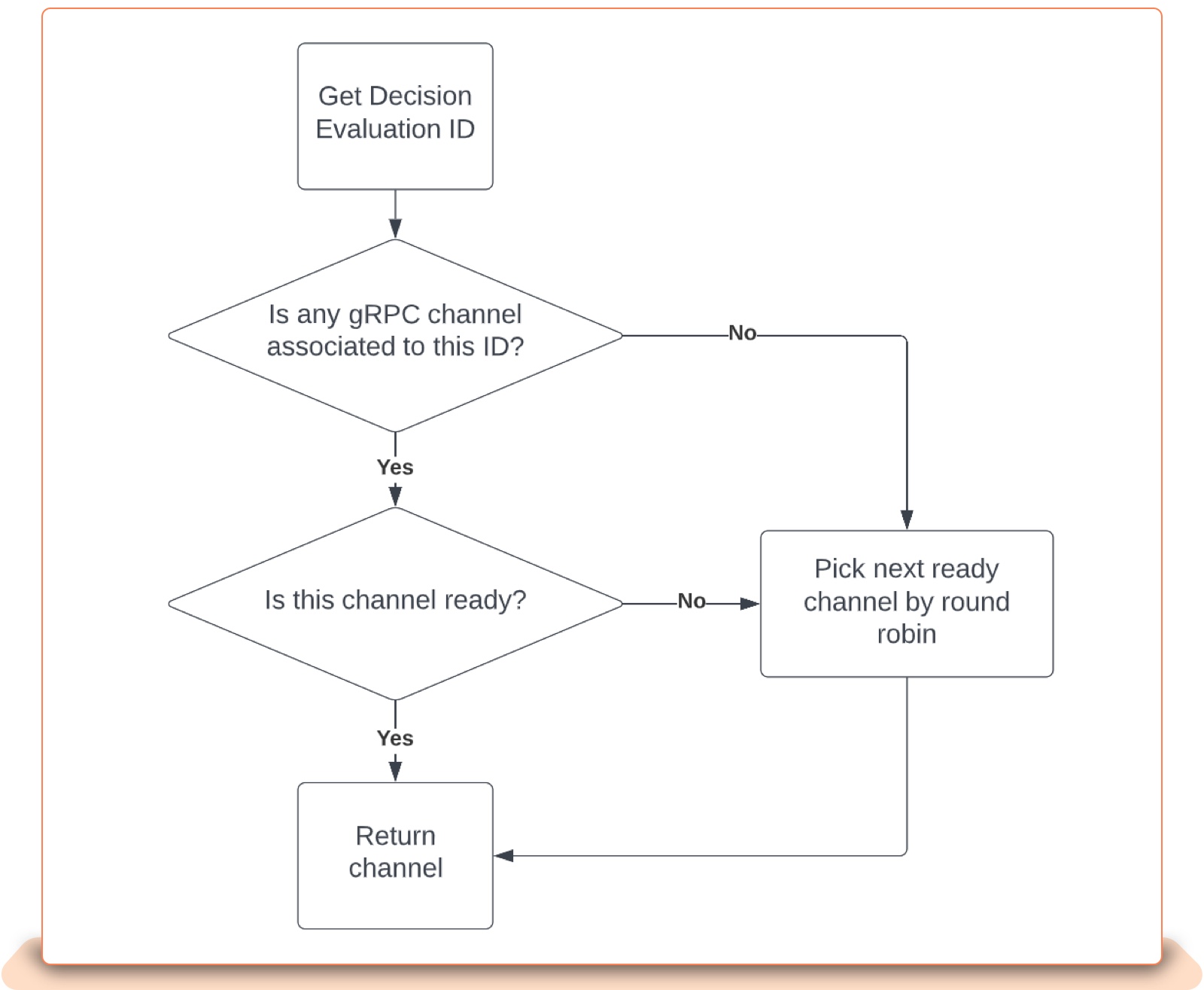
Fig. 7 Sticky round-robin routing algorithm
A nice part of this algorithm is that it does not break the stateless pattern of the client-server communication, despite how it initially appears. Whenever an instance is down, the client will sense it immediately and the algorithm will select a new instance, just as any other stateless LB would achieve. The only difference is that the new instance does not have data cached, so performance will be a bit degraded for that particular unfortunate risk evaluation request. This is completely acceptable, though, since any failover mechanism will introduce some additional delay.
The combination of gRPC connection with sticky session, together with various other tunings, solves the largest of our performance challenges.
Conclusion
The number of issues we encountered and then solved goes far beyond what’s in this article; after all, this refactoring endeavor is a fundamental architectural shift in the risk decisioning regime. As far as we know, although some other companies in the industry are also faced with productivity and performance challenges, it is still a common architecture for decision engines to be coupled with data access. We found little prior experience in the industry that we could readily leverage for our endeavor to build a dedicated data access middleware in order to fundamentally improve the situation. We have already completed the majority of the work mentioned above, and we are currently running hundreds of script based variables, serving billions of requests every day, without major issues. We are working hard to further improve the infrastructure in many aspects.
We hope our experience we are sharing here could be of help to whoever facing similar challenges or considering similar initiatives. We also welcome those who are interested in this area to join us, join eBay, and make an impact with us together.


