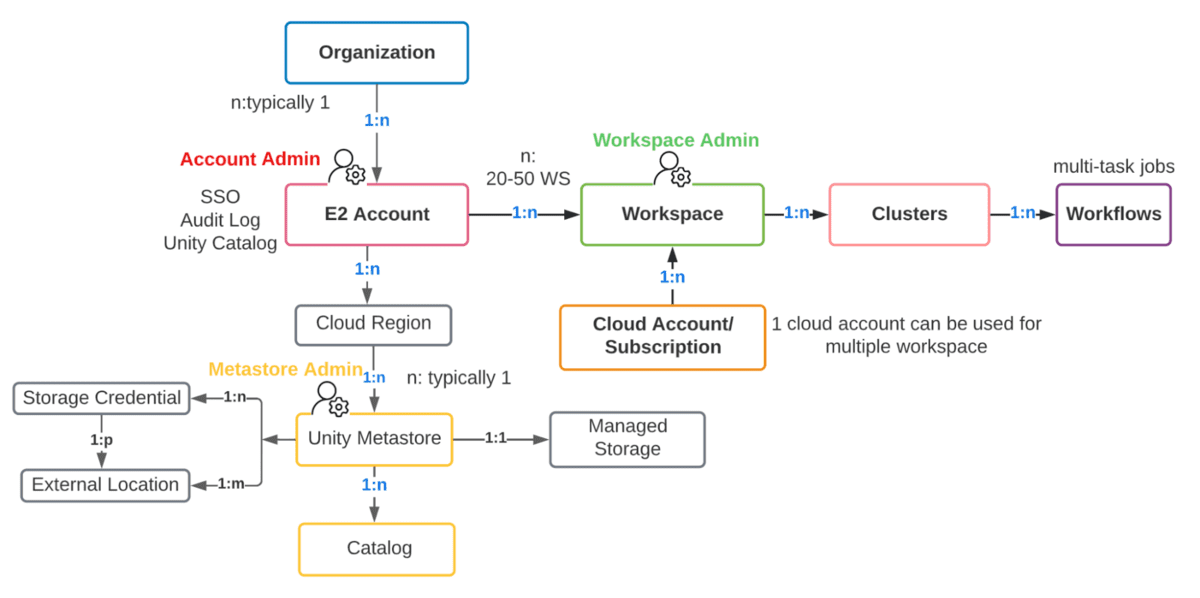
Python Dependency Management in Spark Connect
Managing the environment of an application in a distributed computing environment can be challenging. Ensuring that all nodes have the necessary environment to execute code and determining the actual location of the user’s code are complex tasks. Apache Spark™ offers various methods such as Conda, venv, and PEX; see also How to Manage Python Dependencies […]
Continue Reading