
In Apache Spark™, Python User-Defined Functions (UDFs) are among the most popular features. They empower users to craft custom code tailored to their unique data processing needs. However, the current Python UDFs, which rely on cloudpickle for serialization and deserialization, encounter performance bottlenecks, particularly when dealing with large data inputs and outputs.
In Apache Spark 3.5 and Databricks Runtime 14.0, we introduce Arrow-optimized Python UDFs to significantly improve performance. At the core of this optimization lies Apache Arrow, a standardized cross-language columnar in-memory data representation. By harnessing Arrow, these UDFs bypass the traditional, slower methods of data (de)serialization, leading to swift data exchange between JVM and Python processes. With Apache Arrow’s rich type system, these optimized UDFs offer a more consistent and standardized way to handle type coercion.
Arrow optimization for Python UDFs is optional, and users can control whether or not to enable Arrow optimization for individual UDFs by using the "useArrow" boolean parameter of "functions.udf". An example is as shown below:
>>> @udf(returnType='int', useArrow=True) # An Arrow Python UDF
... def arrow_slen(s):
... return len(s)
... In addition, users can enable Arrow optimization for all UDFs of an entire SparkSession via a Spark configuration: "spark.sql.execution.pythonUDF.arrow.enabled", as shown below:
>>> spark.conf.set("spark.sql.execution.pythonUDF.arrow.enabled", True)
>>>
>>> @udf(returnType='int') # An Arrow Python UDF
... def arrow_slen(s):
... return len(s)
...Faster (De)serialization
Apache Arrow is a columnar in-memory data format that provides efficient data interchange between different systems and programming languages. Unlike Pickle, which serializes an entire Row as an object, Arrow stores data in a column-oriented format, allowing for better compression and memory locality, which is more suitable for analytical workloads.
The chart below shows the performance of an Arrow-optimized Python UDF performing a single transformation with a different-sized input dataset. The cluster consists of 3 workers and 1 driver, and each machine in the cluster has 16 vCPUs and 122 GiBs memory. The Arrow-optimized Python UDF is ~1.6 times faster than the pickled Python UDF.
Arrow-optimized Python UDF has a significant advantage in chaining UDFs. As shown below, in the same cluster, an Arrow-optimized Python UDF can execute ~1.9 times faster than a pickled Python UDF on a 32 GBs dataset.
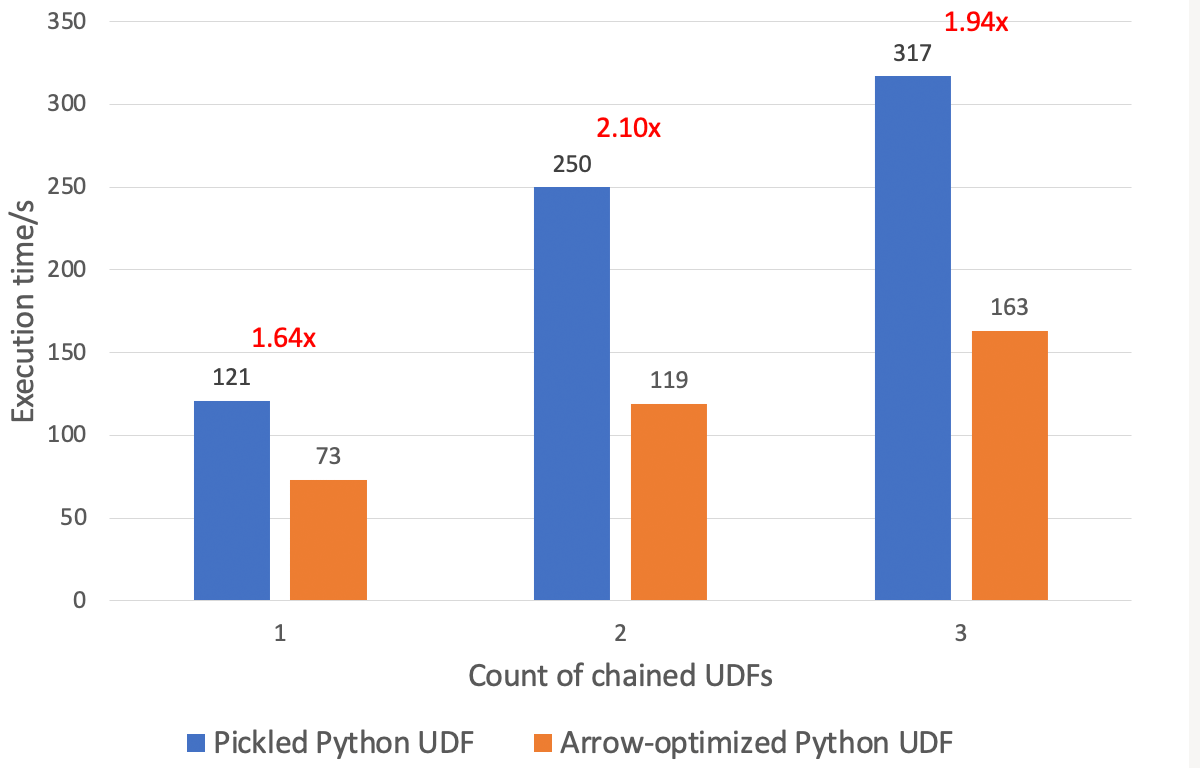
See here for a complete benchmark and results.
Standardized Type Coercion
UDF type coercion poses challenges when the Python values returned by the UDF do not align with the user-specified return type. Unfortunately, the default, pickled Python UDF’s type coercion has certain limitations, such as relying on None as a fallback for type mismatches, leading to potential ambiguity and data loss. Additionally, converting date, datetime, and tuples to strings can yield ambiguous results. Arrow-optimized Python UDFs address these issues by leveraging Arrow’s well-defined set of rules for type coercion.
As shown below, an Arrow-optimized Python UDF(useArrow=True) successfully coerces integers stored as a string back to “int” as specified, but a pickled Python UDF (useArrow=False) falls back to “NULL”.
>>> df = spark.createDataFrame(['1', '2'], schema='string')
>>> df.select(udf(lambda x: x, 'int', useArrow=True)('value').alias('str_to_int')).show()
+----------+
|str_to_int|
+----------+
| 1|
| 2|
+----------+
>>> df.select(udf(lambda x: x, 'int', useArrow=False)('value').alias('str_to_int')).show()
+----------+
|str_to_int|
+----------+
| NULL|
| NULL|
+----------+Another example is shown below, where an Arrow-optimized Python UDF (useArrow=True) coerced a date to a string correctly whereas a pickled Python UDF (useArrow=False) returns ambiguous results by exposing the underlying Java objects.
>>> df = spark.createDataFrame([datetime.date(1970, 1, 1), datetime.date(1970, 1, 2)], schema='date')
>>> df.select(udf(lambda x: x, 'string', useArrow=True)('value').alias('date_in_string')).show()
+--------------+
|date_in_string|
+--------------+
| 1970-01-01|
| 1970-01-02|
+--------------+
>>> df.select(udf(lambda x: x, 'string', useArrow=False)('value').alias('date_in_string')).show()
+-----------------------------------------------------------------------+
|date_in_string |
+-----------------------------------------------------------------------+
|java.util.GregorianCalendar[time=?,areFieldsSet=false,areAllFieldsSet..|
|java.util.GregorianCalendar[time=?,areFieldsSet=false,areAllFieldsSet..|
+-----------------------------------------------------------------------+Compared to Pickle, Arrow’s type coercion aims to maintain as much information and precision as possible during the conversion process.
See here for a comprehensive comparison between Pickled Python UDFs and Arrow-optimized Python UDFs regarding type coercion.
Conclusion
Arrow-optimized Python UDFs utilize Apache Arrow for (de)serialization of UDF input and output, resulting in significantly faster (de)serialization compared to the default, pickled Python UDF. Additionally, it standardizes type coercion rules according to the Apache Arrow specifications. Arrow-optimized Python UDFs are available starting from Spark 3.5; see SPARK-40307 for more information.


