
Recommender systems help users browse the vast inventories found on modern ecommerce websites in a more efficient manner. A core component of many recommender systems is a ranker, which is a machine learning technique that sorts candidate items to show users the items they will like the most. Rankers are used to sort candidate items based on a particular criterion, and to provide personalized recommendations based on user preferences. By providing more relevant and accurate results, rankers help to improve user engagement and loyalty, and thus the overall buyer experience. This article takes a look at the novel approach we took to develop a ranking model for personalized recommendations at eBay. By using a deep learning based ranker model and a pairwise loss function, our approach led to significant improvements in user engagement and conversion rates.
Industrial recommender systems have been shifting towards personalized recommendations, as opposed to contextual recommendations, over the last few years. In the past, our recommender systems team has focused primarily on developing item-based contextual recommendations, which we’ve written about in several eBay Tech Blog posts. While considering an input item’s context is important for generating item recommendations, there are several settings where only a user context is present, such as on eBay’s homepage, a standalone feed, or a personalized recommendation module based on a user’s shopping behavior. To generate personalized item recommendations to the user, the algorithm first retrieves candidate items, as described previously, and then ranks the candidate items based on a business objective such as predicted click or purchase through rate, to determine the final order. We’re focusing here on the ranking portion of this process and will describe the details of our user-based ranking model.
At eBay, we take user data privacy very seriously. At any time a user can opt out of personalized recommendations using AdChoice, eBay’s global ads opt out tool.
Here is an example of contextual and personalized recommendation on the eBay site.
Figure 1: Two different input contexts: (a) item input context and (b) a user’s recently viewed items. (c) Similar item-based recommendations using information from an input item (a). (d) Personalized user-based recommendations using information from a user’s recently viewed items (b).
In order to better predict a user’s click and purchase actions, we have developed a deep learning ranker model trained on a user’s historical behavior. The model utilizes several user and item features and wide and deep architecture, and enables us to blend user-based candidate items based only on the user input context.
Model Structure
The main model structure is depicted in Figure 2. It follows the structure of a wide and deep network. We chose a deep learning based model for our ranker because it is a user-based ranker, meaning a user’s features are particularly important. Deep models can process a user’s sequential events as input by adopting Recurrent Neural Network, or RNN, -based networks, and also can share the bottom layer (feature layer) to perform multi-task learning. This enables the optimization of different user engagement signals at the same time. Besides the above, it can also leverage both user and recommended item embeddings generated by other pre-trained models, such as our previously developed embeddings, to enrich implicit knowledge about users and items.
Before the model is trained, raw input data needs to be transformed into either numeric or embedding type features. For example, for some continuous features, we project them into categorical features using bucketing operations. But first, let’s look at both the deep and wide structures at work here.
Deep Structure
The deep part is a fully connected neural network with inputs from transformed features. The features can be split into two parts (numeric features and embedding-based features) which can be fed into the model directly. The numeric features calculate the relationship between the user’s historical behaviors (views, searches, watches) and the candidate item. The embedding-based features are projected from sparse or categorical features. We then concatenate these features together and feed them into multiple hidden layers using a nonlinear activation function for training.
Wide Structure
Besides generalization provided by the deep part described above, memorization is also an important component of the architecture for model performance. Memorization – the model’s ability to learn the frequent co-occurrence of items or features – is especially important for the model when working with the information of id features like item_id or user_id. On eBay, however, there are a large number of single quantity items. In addition, users have varying visit frequency. Therefore, the model performance is not greatly improved by memorization of ID features. Moreover, the effects of some user features that strongly represent the user’s behavior sequence may be weakened by deep layer generalization. As a result, we adopt a shallow network rather than the typical wide linear part. By adding this extra shallow network, the model performance was improved significantly. We have conducted offline experiments to verify our design and details are illustrated in the sections below.
After getting the outputs from the wide and deep networks respectively, we finally concatenate them together and transform to get the final score to calculate the loss.

Figure 2: Architecture of our wide & deep based ranking model.
Feature Engineering Improvements
For better model performance, we needed to design effective user features to better represent users’ intrinsic interests. User features may determine the upper bound of model performance. We designed two special types of features to improve model performance: pretrained embedding features and derived features.
Pretrained Embedding Features
We leveraged a two-tower based personalized recall model we previously developed in order to generate both user and item embeddings as features in our user-based ranking model. The steps to generate these two embedding features are as follows:
-
Predict user embedding through the user tower, by feeding into a user’s latest eBay browsing activities, currently limited in view item clicked and search event types
-
Predict candidate item embedding through the item tower
-
Join the above embeddings with the training data by user_id and item_id, respectively
After obtaining the complete training data with these two pretrained embedding features, we feed them into the deep neural network directly, since they are already dense features. The reason why these two features are effective is that the personalized recall model has learned the implicit representation of both the user and the item according to the user’s behavior sequence and item information, so it can provide more knowledge to the ranking model. This enables it to better capture the relations between a user’s preference and the candidate item.
Derived Features
The above pretrained embedding features may be generalized, since both the user and the candidate item are projected into high-dimensional representations which are unexplainable. Besides these implicit embedding features, we continued to explore more effective user features with business explainability. For example, we added some freshness features extracted from a user’s recently viewed items to measure the decay of a user’s interest in the candidate item.
In order to improve the model performance, we utilized additional user information, including other engagement events like transactions and add-to-cart events to enrich the training data for better understanding of a user’s intrinsic preference and browsing habits. By adding these novel user features, the model performance was improved. We’ve illustrated the detailed offline experiment results regarding newly added features in the sections below.
Loss Function
Besides the model structure and features, adopting the right loss function is also important to improve model performance. Unlike the commonly used pointwise loss function which predicts the truth value given its label, we prefer the pairwise loss function to optimize click and purchase probability at the same time. For example, in the following scenario: item A (not clicked), item B (clicked) and item C (purchased) by the same user, the ideal ranking order for this user would be C > B > A. If we only optimize for click objective, the ranks for item B and C would be predicted incorrectly. Similarly, if we only optimize for conversion (purchases), the model may not learn that item B is relatively better than item A.
In our eBay recommendations scenario, pairwise approach works better in practice than pointwise approach, because predicting relative order is closer to the nature of ranking than predicting class label or relevance score. Given a pair of items, the pairwise function tries to come up with the optimal ordering for that pair and compare it to the ground truth. The goal for the ranker is to minimize the number of inversions in ranking, i.e. cases where the pair of results are in the wrong order relative to the ground truth.
In our recommendation scenario, the interaction between the user and the item is not the same every time. For example, A user who is very sensitive to price may choose dress D ($60) over dress E ($80). However, if there is another dress F ($45) the user may give up dress D while choosing dress F. By choosing the pairwise loss, the model learns a user’s preference for price. But if we select pointwise loss, dress D may be both clicked or not clicked by the same user depending on E or F recommended at the same placement. This is the main reason we adopt pairwise loss function rather than pointwise function.
The loss function is defined as:

The second part in the loss function is the predicted pairwise score, which is:
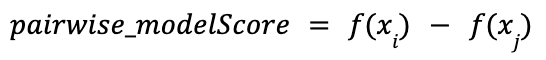
where f(x) is the model prediction score for each candidate item.
Utilizing this pairwise loss, model architecture and features, we performed several rounds of offline evaluations to validate the performance of the ranking model.
Offline Development Iterations
Before deploying to production, the user-based ranking model was evaluated offline using several ranking metrics, including NDCG. Training data was generated using implicit feedback from previous recommender system results on eBay.
As Table 1 shows, we have conducted several iterations of offline experiments before deploying to a real production setting to verify the effectiveness of the explored features and model structure. The baseline model is our previous heuristic based blending strategy. The V1 model only adopts the deep part of the model with some commonly used item and user features. The V2 model adds the novel features mentioned in the feature engineering improvement section, but lacks without the wide network. The V3 model combines both the optimized features and the upgraded model structure, described fully in the previous sections.
We can see that the NDCG@12 metric improved by 1% over the baseline in the V1 model and 1.86% over the baseline in the V2 model. This demonstrates that feature engineering is worthy of continuous iteration and exploration. Additionally, the model structure innovation contributes even more, NDCG@12 metric improved by 2.56% over the baseline in the V3 model, which adds the wide architectural structure.

Table1: Offline evaluation data of the ranking model using NDCG@k metric and % lift improvement over the baseline model. The baseline as well as V1, V2, and V3 models are described in the text.
Online Inferencing
In order to serve the model online, the model is deployed to our production environment to serve real-time traffic from users. The process is illustrated below in Figure 3.

Figure 3: Dataflow of offline training and online inferencing of the ranking model.
Here are the steps in detail:
-
The user-based ranking models were trained using eBay’s GPU cluster, called Krylov, using an Airflow based scheduler. After an acceptable model was trained, the corresponding Torchscript file was exported.
-
The file was deployed to our GPU inferencing platform which is in the production environment.
-
When a user views a page on the eBay website, the request containing the user’s context will be delivered to our Spring Boot/Java/Scala recommendations backend application. This application serves recommendation items to users in eBay’s high-volume traffic production environment.
-
The candidate recommendation items are generated along with the features the ranking model needs. These items and their features are encoded and then sent to the GPU inferencing platform where the model was pre-deployed in Step 2.
-
The backend application ranks these items by the scores.
-
Ranked personalized recommendation items are returned to the user.
A/B tests were performed on recommendation modules on several eBay pages, including the Listing page and Home page. The tests show statistically significant lift in key operational metrics and also increase in ads revenue. Table 2 shows results from testing the V1 model that we described in detail in this blog post. The ranking models were launched to production after these positive A/B test results.

Table 2: A/B tests results in CTR and PTR metrics on both Home Page and View Item Page.
Summary
We adopted a deep and wide neural network to optimize click and purchase labels at the same time by designing informative, generalized and explainable user features to boost model performance. After performing A/B tests on production traffic on the eBay site, we launched this model on the View Item Page and Home Page. We are exploring more ways to optimize the user-based ranking model, including involving additional engagement labels, not only click and purchase labels, as well as upgrading the pairwise loss by using a listwise loss function.
Acknowledgements
We would like to thank the support of Yi Sun, Sathish Veeraraghavan, Menghan Wang, Michelle Hwang, Jeff Kahn, Yuchen Guo, Marshall Wu, Shawn Zhou, and Sriganesh Madhvanath.


