Introduction
Grab’s real-time data platform team, Coban, has been managing infrastructure resources via Infrastructure-as-code (IaC). Through the IaC approach, Terraform is used to maintain infrastructure consistency, automation, and ease of deployment of our streaming infrastructure, notably:
With Grab’s exponential growth, there needs to be a better way to scale infrastructure automatically. Moving towards GitOps processes benefits us in many ways:
- Versioned and immutable: With our source code being stored in Git repositories, the desired state of infrastructure is stored in an environment that enforces immutability, versioning, and retention of version history, which helps with auditing and traceability.
- Faster deployment: By automating the process of deploying resources after code is merged, we eliminate manual steps and improve overall engineering productivity while maintaining consistency.
- Easier rollbacks: It’s as simple as making a revert for a Git commit as compared to creating a merge request (MR) and commenting Atlantis commands, which add extra steps and contribute to a higher mean-time-to-resolve (MTTR) for incidents.
Background
Originally, Coban implemented automation on Terraform resources using Atlantis, an application that operates based on user comments on MRs.
We have come a long way with Atlantis. It has helped us to automate our workflows and enable self-service capabilities for our engineers. However, there were a few limitations in our setup, which we wanted to improve:
- Course grained: There is no way to restrict the kind of Terraform resources users can create, which introduces security issues. For example, if a user is one of the Code owners, they can create another IAM role with Admin privileges with approval from their own team anywhere in the repository.
- Limited automation: Users are still required to make comments in their MR such as atlantis apply. This requires the learning of Atlantis commands and is prone to human errors.
- Limited capability: Having to rely entirely on Terraform and Hashicorp Configuration Language (HCL) functions to validate user input comes with limitations. For example, the ability to validate an input variable based on the value of another has been a requested feature for a long time.
- Not adhering to Don’t Repeat Yourself (DRY) principle: Users need to create an entire Terraform project with boilerplate codes such as Terraform environment, local variables, and Terraform provider configurations to create a simple resource such as a Kafka topic.
Solution
We have developed an in-house GitOps solution named Khone. Its name was inspired by the Khone Phapheng Waterfall. We have evaluated some of the best and most widely used GitOps products available but chose not to go with any as the majority of them aim to support Kubernetes native or custom resources, and we needed infrastructure provisioning that is beyond Kubernetes. With our approach, we have full control of the entire user flow and its implementation, and thus we benefit from:
- Security: The ability to secure the pipeline with many customised scripts and workflows.
- Simple user experience (UX): Simplified user flow and prevents human errors with automation.
- DRY: Minimise boilerplate codes. Users only need to create a single Terraform resource and not an entire Terraform project.
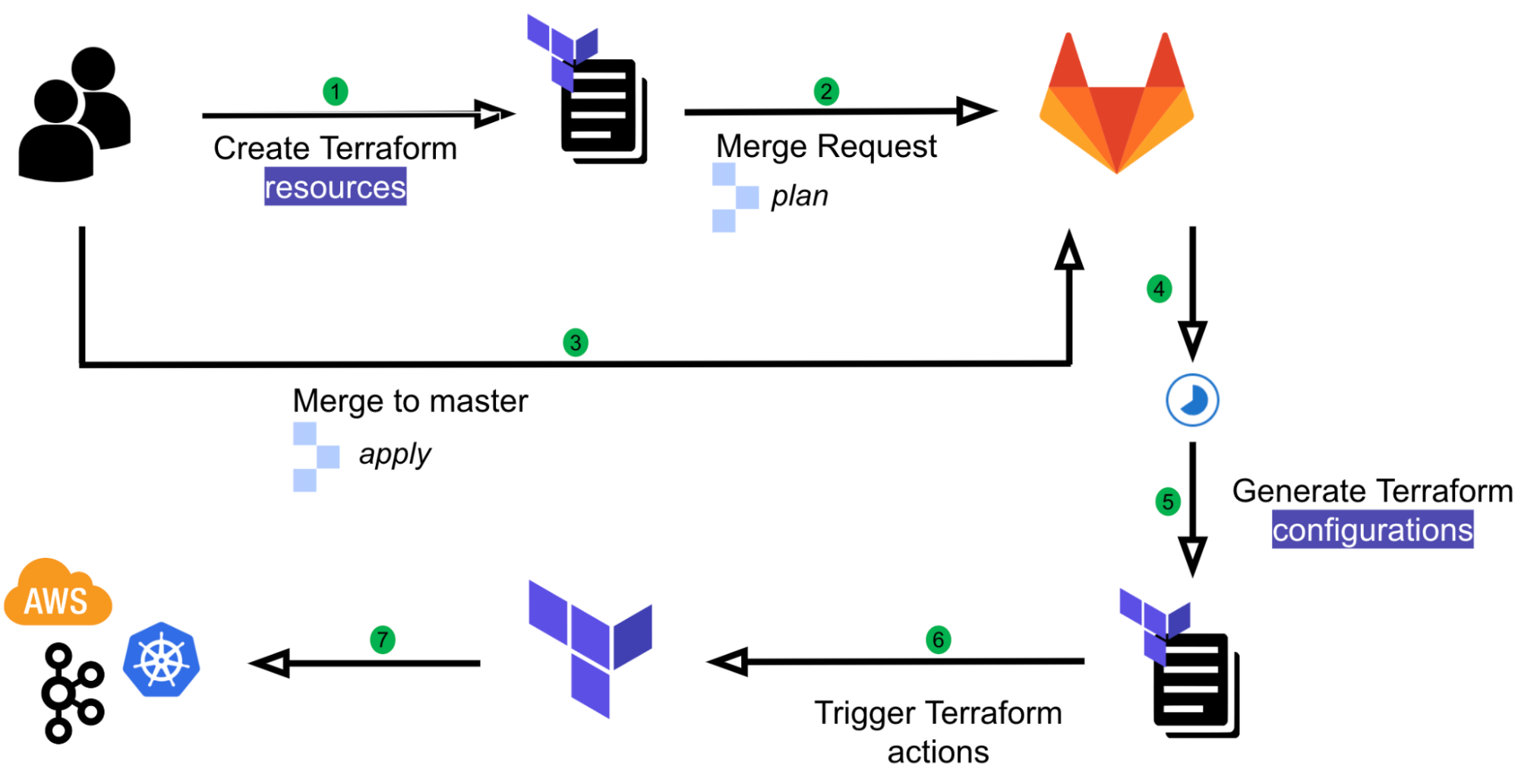
With all types of streaming infrastructure resources that we support, be it Kafka topics or Flink pipelines, we have identified they all have common properties such as namespace, environment, or cluster name such as Kafka cluster and Kubernetes cluster. As such, using those values as file paths help us to easily validate users input and de-couple them from the resource specific configuration properties in their HCL source code. Moreover, it helps to remove redundant information to maintain consistency. If the piece of information is in the file path, it won’t be elsewhere in resource definition.
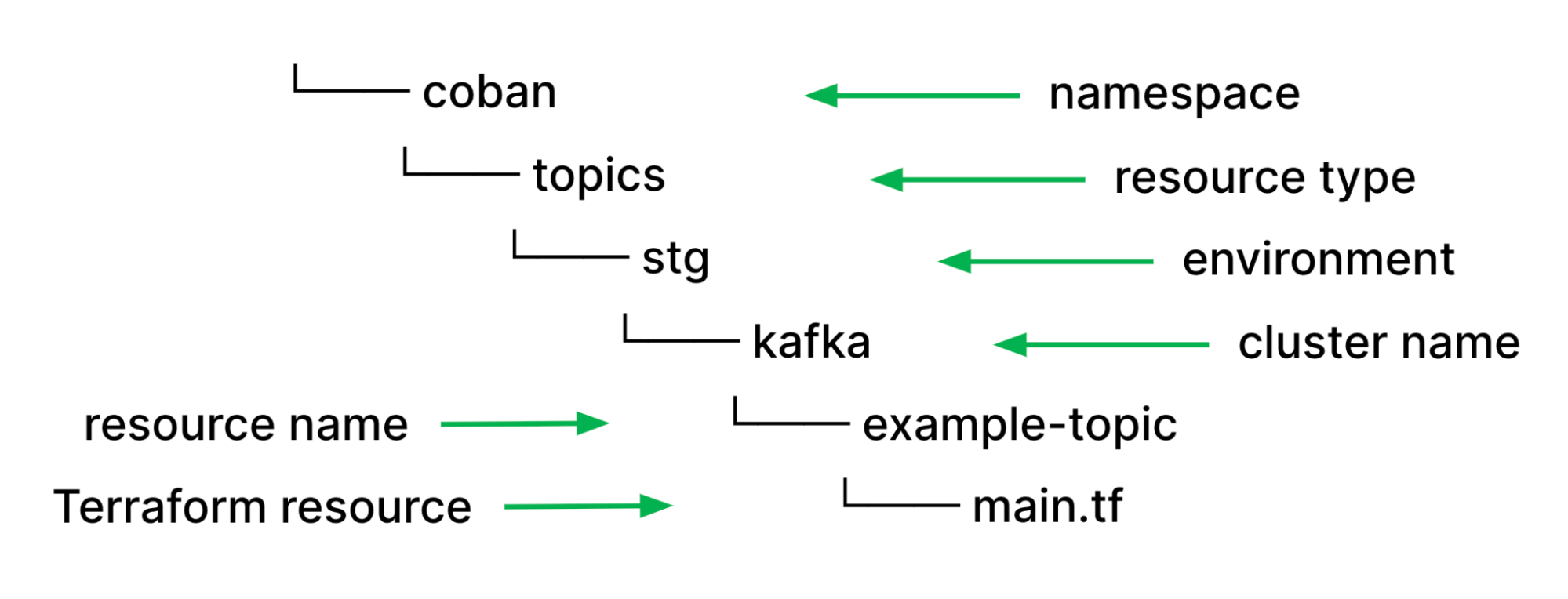
With this approach, we can utilise our pipeline scripts, which are written in Python and perform validations on the types of resources and resource names using Regular Expressions (Regex) without relying on HCL functions. Furthermore, we helped prevent human errors and improved developers’ efficiency by deriving these properties and reducing boilerplate codes by automatically parsing out other necessary configurations such as Kafka brokers endpoint from the cluster name and environment.
Pipeline stages
Khone’s pipeline implementation is designed with three stages. Each stage has different duties and responsibilities in verifying user input and securely creating the resources.
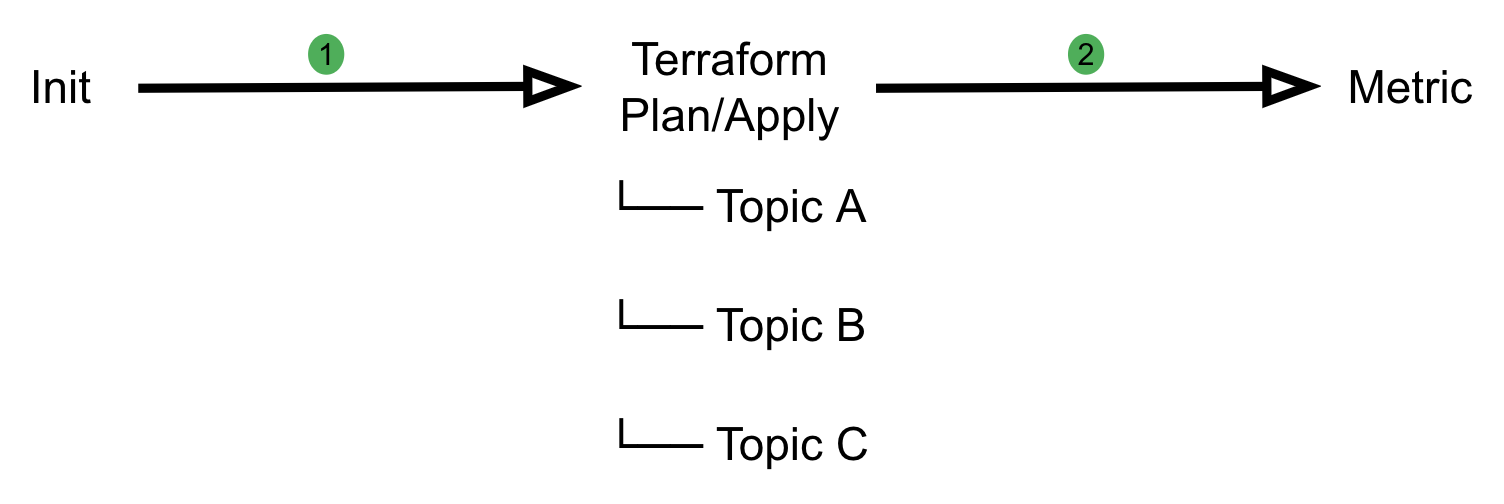
Initialisation stage
At this stage, we categorise the changes into Deleted, Created or Changed resources and filter out unsupported resource types. We also prevent users from creating unintended resources by validating them based on resource path and inspecting the HCL source code in their Terraform module. This stage also prepares artefacts for subsequent stages.
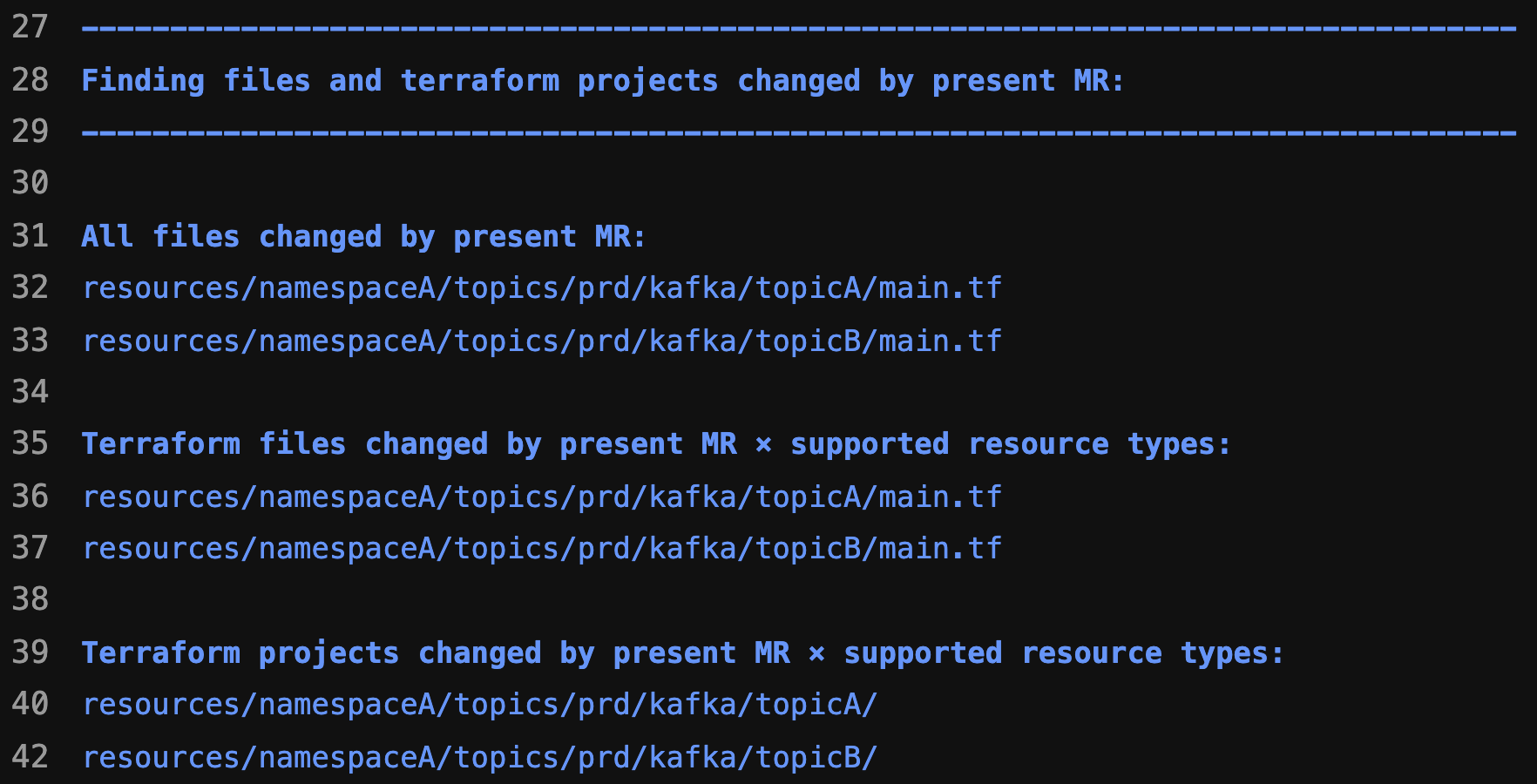
Terraform stage
This is a downstream pipeline that runs either the Terraform plan or Terraform apply command depending on the state of the MR, which can either be pending review or merged. Individual jobs run in parallel for each resource change, which helps with performance and reduces the overall pipeline run time.
For each individual job, we implemented multiple security checkpoints such as:
- Code inspection: We use the python-hcl2 library to read HCL content of Terraform resources to perform validation, restrict the types of Terraform resources users can create, and ensure that resources have the intended configurations. We also validate whitelisted Terraform module source endpoint based on the declared resource type. This enables us to inherit the flexibility of Python as a programming language and perform validations more dynamically rather than relying on HCL functions.
- Resource validation: We validate configurations based on resource path to ensure users are following the correct and intended directory structure.
- Linting and formatting: Perform HCL code linting and formatting using Terraform CLI to ensure code consistency.
Furthermore, our Terraform module independently validates parameters by verifying the working directory instead of relying on user input, acting as an additional layer of defence for validation.
path = one(regexall(join("https://engineering.grab.com/",
[
"^*",
"(?P<repository>khone|khone-dev)",
"resources",
"(?P<namespace>[^/]*)",
"(?P<resource_type>[^/]*)",
"(?P<env>[^/]*)",
"(?P<cluster_name>[^/]*)",
"(?P<resource_name>[^/]*)$"
]), path.cwd))
Metric stage
In this stage, we consolidate previous jobs’ status and publish our pipeline metrics such as success or error rate.
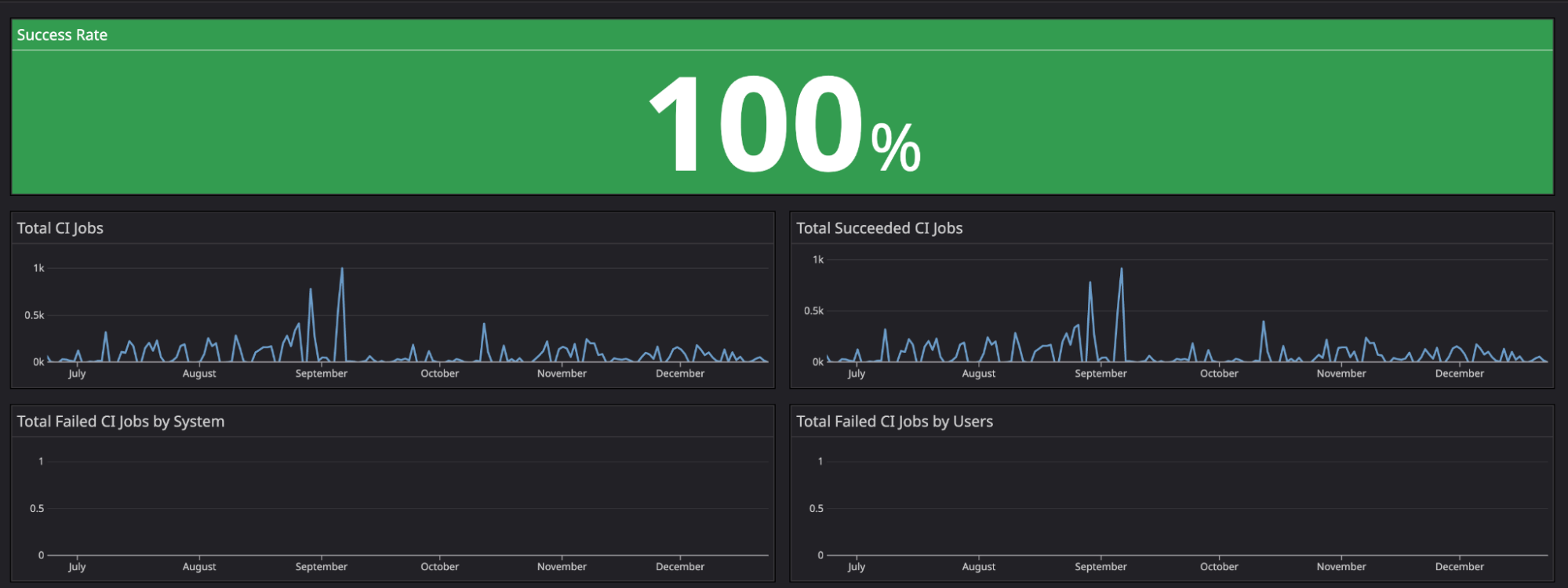
For our metrics, we identified actual users by omitting users from Coban. This helps us measure success metrics more consistently as we could isolate metrics from test continuous integration/continuous deployment (CI/CD) pipelines.
For the second half of 2022, we achieved a 100% uptime for Khone pipelines.
Preventing pipeline config tampering
By default, with each repository on GitLab that has CI/CD pipelines enabled, owners or administrators would need to have a pipeline config file at the root directory of the repository with the name .gitlab-ci.yml. Other scripts may also be stored somewhere within the repository.
With this setup, whenever a user creates an MR, if the pipeline config file is modified as part of the MR, the modified version of the config file will be immediately reflected in the pipeline’s run. Users can exploit this by running arbitrary code on the privileged GitLab runner.
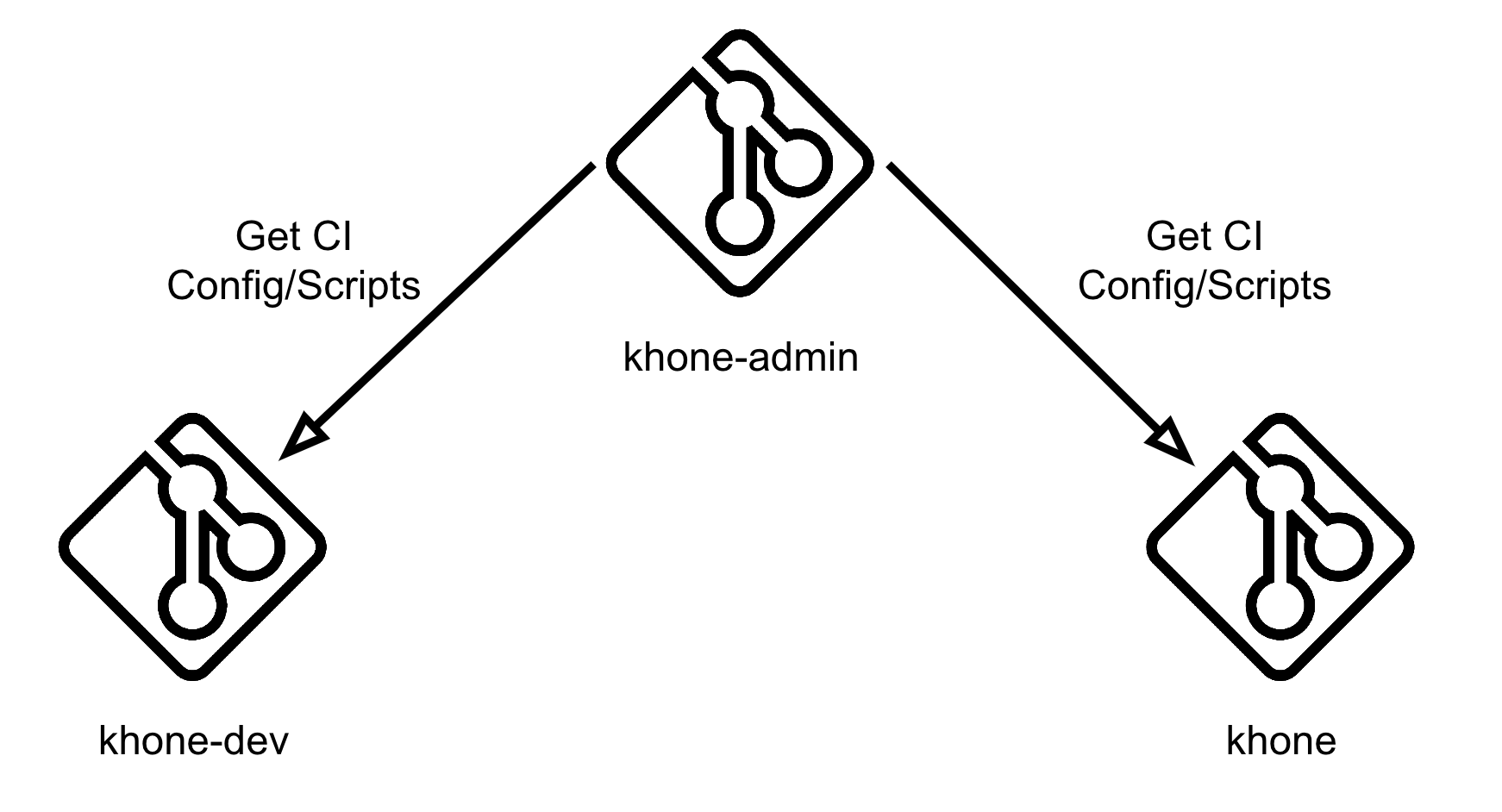
In order to prevent this, we utilise GitLab’s remote pipeline config functionality. We have created another private repository, khone-admin, and stored our pipeline config there.

In Fig. 7, our configuration is set to a file called khone-gitlab-ci.yml residing in the khone-admin repository under snd group.
Preventing pipeline scripts tampering
We had scripts that ran before the MR and they were approved and merged to perform preliminary checks or validations. They were also used to run the Terraform plan command. Users could modify these existing scripts to perform malicious actions. For example, they could bypass all validations and directly run the Terraform apply command to create unintended resources.
This can be prevented by storing all of our scripts in the khone-admin repository and cloning them in each stage of our pipeline using the before_script clause.
default:
before_script:
- rm -rf khone_admin
- git clone --depth 1 --single-branch https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.myteksi.net/snd/khone-admin.git khone_admin
Even though this adds an overhead to each of our pipeline jobs and increases run time, the amount is insignificant as we have optimised the process by using shallow cloning. The Git clone command included in the above script with depth=1 and single-branch flag has reduced the time it takes to clone the scripts down to only 0.59 seconds.
Testing our pipeline
With all the security measures implemented for Khone, this raises a question of how did we test the pipeline? We have done this by setting up an additional repository called khone-dev.
Pipeline config
Within this khone-dev repository, we have set up a remote pipeline config file following this format:
<File Name>@<Repository Ref>:<Branch Name>

In Fig. 9, our configuration is set to a file called khone-gitlab-ci.yml residing in the khone-admin repository under the snd group and under a branch named ci-test. With this approach, we can test our pipeline config without having to merge it to master branch that affects the main Khone repository. As a security measure, we only allow users within a certain GitLab group to push changes to this branch.
Pipeline scripts
Following the same method for pipeline scripts, instead of cloning from the master branch in the khone-admin repository, we have implemented a logic to clone them from the branch matching our lightweight directory access protocol (LDAP) user account if it exists. We utilised the GITLAB_USER_LOGIN environment variable that is injected by GitLab to each individual CI job to get the respective LDAP account to perform this logic.
default:
before_script:
- rm -rf khone_admin
- |
if git ls-remote --exit-code --heads "https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.myteksi.net/snd/khone-admin.git" "$GITLAB_USER_LOGIN" > /dev/null; then
echo "Cloning khone-admin from dev branch ${GITLAB_USER_LOGIN}"
git clone --depth 1 --branch "$GITLAB_USER_LOGIN" --single-branch "https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.myteksi.net/snd/khone-admin.git" khone_admin
else
echo "Dev branch ${GITLAB_USER_LOGIN} not found, cloning from master instead"
git clone --depth 1 --single-branch "https://gitlab-ci-token:${CI_JOB_TOKEN}@gitlab.myteksi.net/snd/khone-admin.git" khone_admin
fi
What’s next?
With security being our main focus for our Khone GitOps pipeline, we plan to abide by the principle of least privilege and implement separate GitLab runners for different types of resources and assign them with just enough IAM roles and policies, and minimal network security group rules to access our Kafka or Kubernetes clusters.
Furthermore, we also plan to maintain high standards and stability by including unit tests in our CI scripts to ensure that every change is well-tested before being deployed.
References
Special thanks to Fabrice Harbulot for kicking off this project and building a strong foundation for it.
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!