
Promoted Listings Standard (PLS) helps sellers’ items stand out among billions of listings on eBay. eBay offers several ways to surface PLS listings. One way is placing those items on the search result page at a higher rank, with a “sponsored” badge; another way is recommended by our PLS item recommendation engines on View Item Page. Such PLS items’ high surface rate costs the seller an additional ad rate fee.This helps to increase the likelihood of a sale while staying seller-friendly, as the seller pays only upon sale of the item.
This essay focuses on the latter surface way of PLS items, that is the recommendation engines which help users engage with our PLS content, and help us optimally display the items in our uniquely vast and diverse marketplace. One of the recommendations is to recommend similar sponsored items, which is called Promoted Listing SIM (i.e. PLSIM1). The typical user journey for the PLSIM consists of the following steps:
- The user searches for an item.
- Clicks on a result in the search result page, landing on a View Item (VI) page for a listed item, which we refer to as the seed item.
- Scrolls down the VI page, and sees recommended items in PLSIM.
- Subsequently clicks on an item recommendation and arrives at a new VI page to see the main listing details to either take action (watch, add to cart, buy it now, and more) or check out another, new set of recommended items.
In turn, from a machine-learning perspective, our PLSIM engine2 has three stages:
- It retrieves a subset of candidate Promoted Listings Standard (the “recall set”) that are most relevant to the seed item.
- Applies a trained machine learning ranker to rank the listings in the recall set according to the likelihood of purchase.
- Re-ranks the listings by incorporating seller ad-rate, in order to balance seller velocity enabled through promotion3 with the relevance of recommendations.
This article discusses in detail and focuses on enhancements taken towards the label generation process in Stage 2 of the PLSIM engine, the machine learning ranker, which we found helps significantly with model performance (e.g. purchases).
Ranking Model
Our ranking model is trained offline on historical data. The features of the ranking model tend to be based on the following type of data:
- Recommended item historical data
- Recommended item to seed item similarity
- Context (country, product category)
- User personalization features
We iteratively train versions of the model as we innovate new features. We use a gradient boosted tree, which, for a given seed item, ranks items according to items’ relative purchase probabilities.
From Binary Feedback to Multi-Relevancy Feedback
The Promoted Listing Standard product is a CPA (cost-per-acquisition) product, where the acquisition in this case is the sale of the item being promoted. Thus our mission is to help our sellers convert views to sales. Consequently, the models in the past have predominantly focused on optimizing purchase probabilities and have relied on binary purchase data. A recommended item in historical data would have been considered “relevant” if it had been purchased with a given seed item, and “irrelevant” if it had not been purchased.
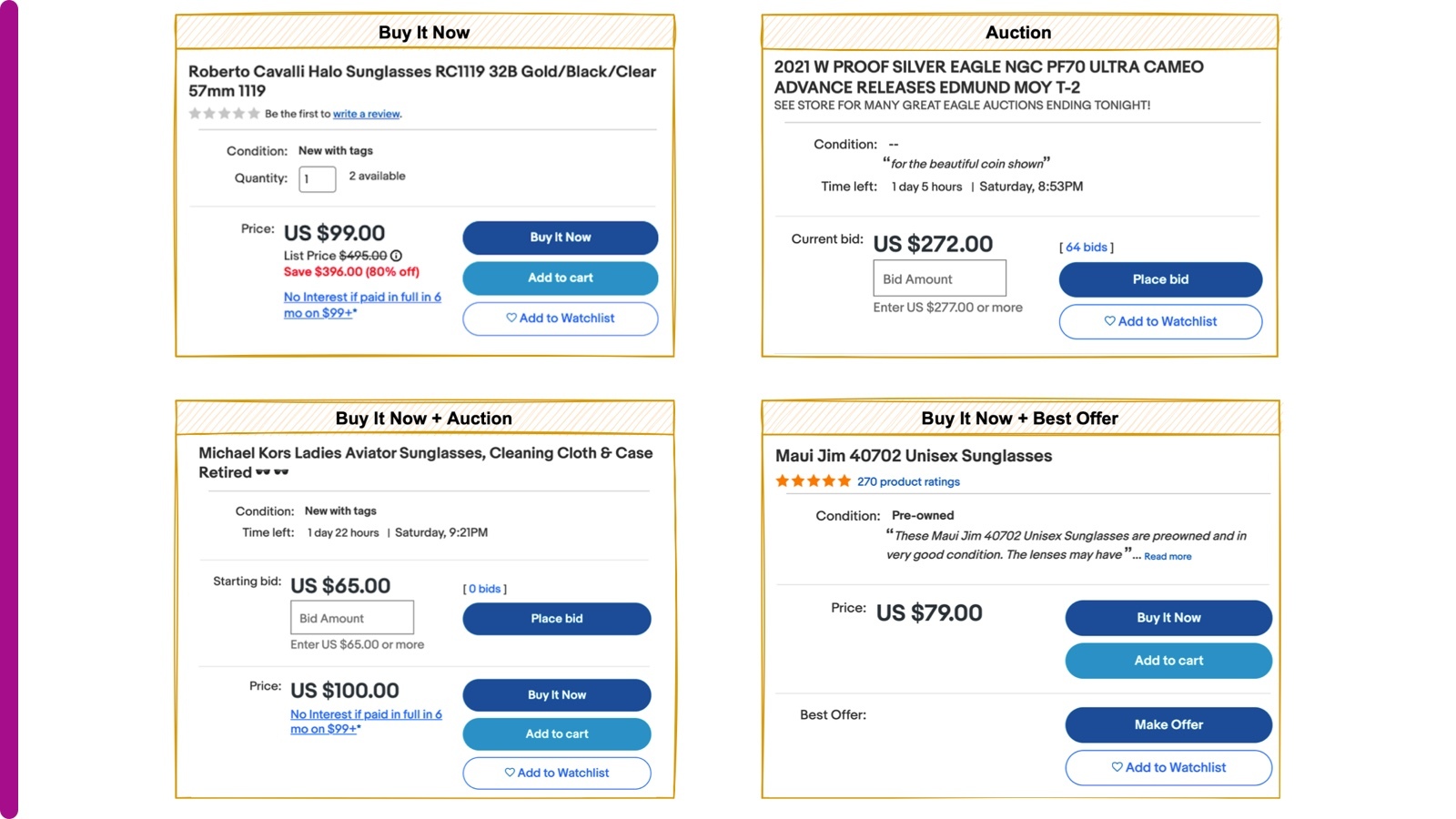
Although the binary purchase labeling approach proved to be a successful first step, we still saw significant opportunities for improvement. First, users tend to buy just one item from a given list of recommended items, but the other items could still be good recommendations; such a situation amounts to false negatives in labeling. Second, purchases are extremely rare events compared to other user actions like a click, and oversampling techniques notwithstanding, it is always difficult to train a model with sufficient volume and diversity in the purchases to be predictive of the positive class. Finally, users reveal a whole range of behaviors and interests when they browse our pages. For example, clicks express a relatively weak purchase intent, since users can simply browse the site and comparison-shop. Nevertheless, a click still reveals some information about relevance, at least compared with the alternative of a non-click. Besides a click, a variety of user actions may also capture conversion intent, such as when users do one of the following actions to a recommended item of certain format on its VI page:
- Buy It Now (only applied to (Buy-It-Now) BIN listing4)
- Add to cart (only applied to BIN listing)
- Make offer (only applied to Best Offer listing)
- Place bid5 (only applied to Auction listing)
- Add to Watchlist (applied to BIN, Best Offer, or Auction listing)
Here are some UI examples of button options for different listing formats shown as below.
We decided to incorporate these additional purchase intent signals by casting them on a scale of relevance, where the purchase is considered the most relevant label in the training of the model.
Relevance Levels of Multi-Relevance Feedback
Once we understood that user actions should be encoded as labels, the question became: if purchased items are considered the most relevant, how do the other forms of user engagement compare in relevance?
A user journey that leads to a purchase from a PLSIM recommended item must start from a selection of (in other words, a click on) the recommended item, followed by a direction to the VI page of the recommended item, where one or more action buttons are applicable depending on the listing format. Thus, naturally, a lack of a selection is the least relevant action that leads to a purchase, a selection is the second least relevant action to a purchase, and the rest of the possible actions — “Make Offer,” “Buy It Now,” “Add to Watchlist” and “Add to cart” — are more relevant to a purchase.
We determined that the best way of ranking “Make offer,” “Buy It Now,” “Add to Watchlist” and “Add to cart” actions was to do so according to what proportion of items were purchased following the action, which is captured in the independent pie charts below:
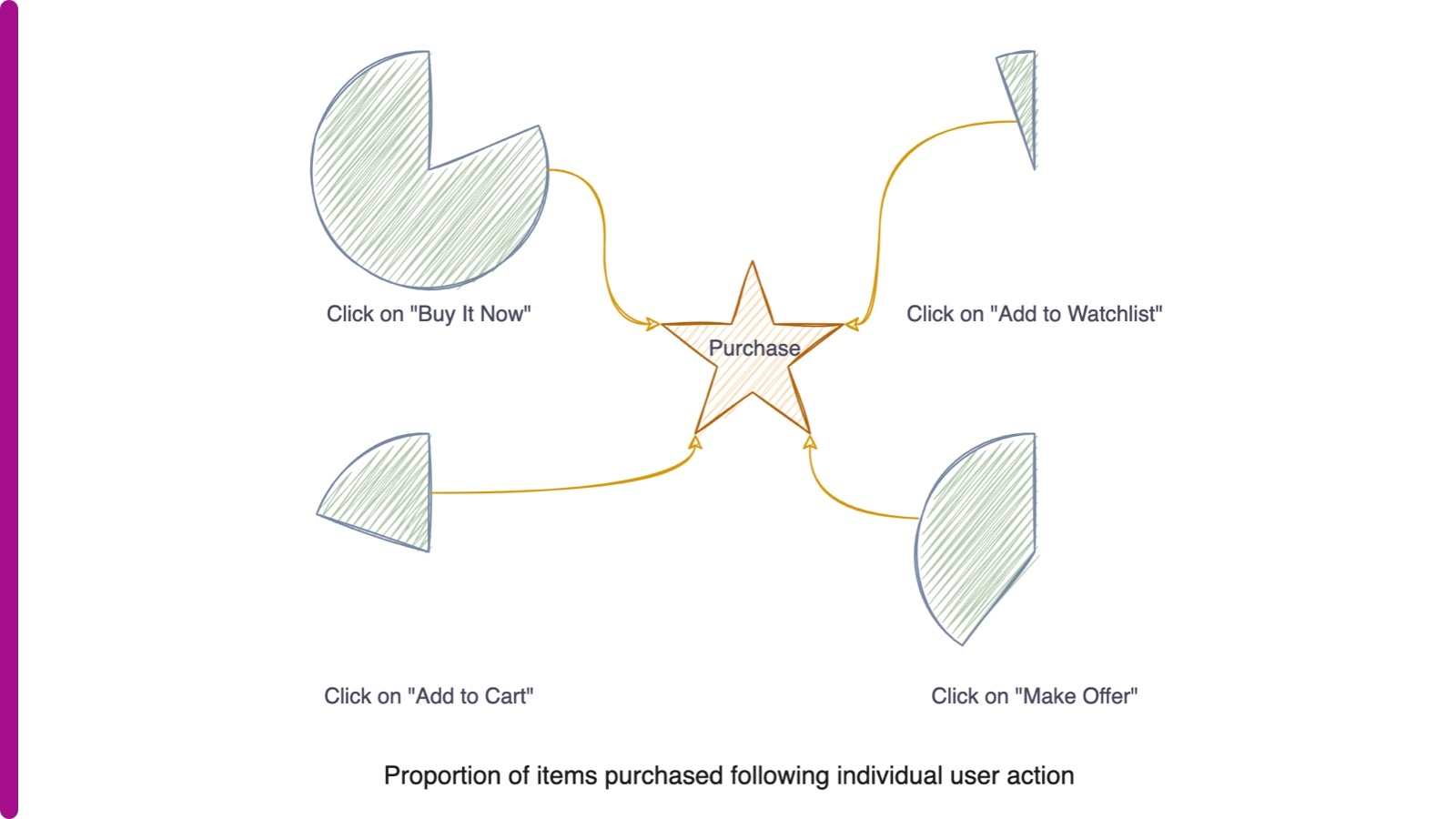
Thus in historical training data, for a seed item, each of the potential items were labeled on the following scale as the relevance level:

The consequence of the labeling was that during training, the ranker penalized misranked purchases more heavily than it penalized misranked Buy-It-Now’s, and so on, down the list.
Sample Weights of Multi-Relevance Feedback
There was an additional nuance that was key to successful offline performance. Although the gradient-boosted tree supported multiple labels to capture a range of relevance, there was no direct way of implementing the magnitude of the relevance. That is, we know that “Add to Watchlist” events are more relevant than a click in predicting purchase intent, but for a well-tuned ranker, we also need to understand how much more relevant they are.
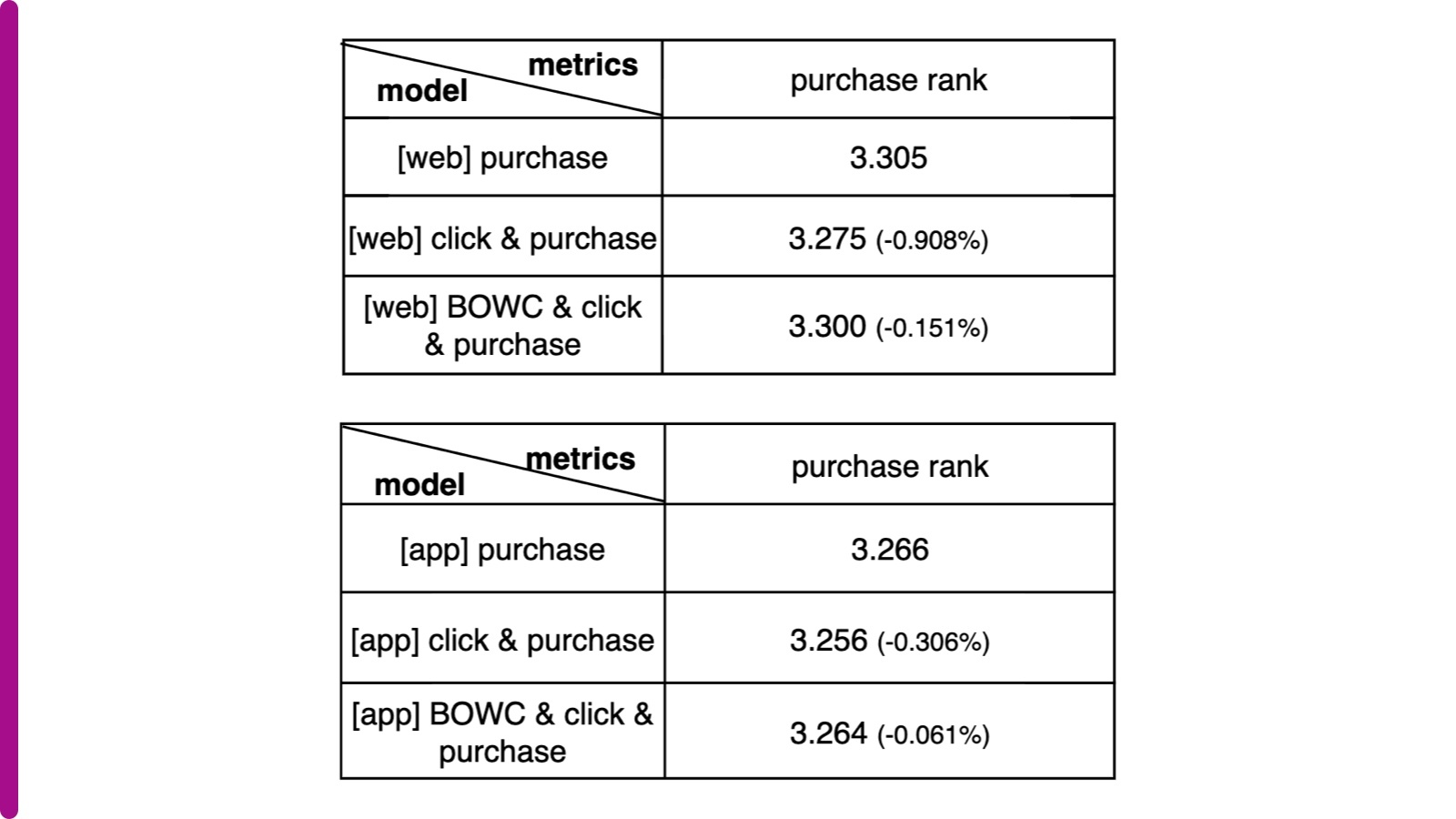
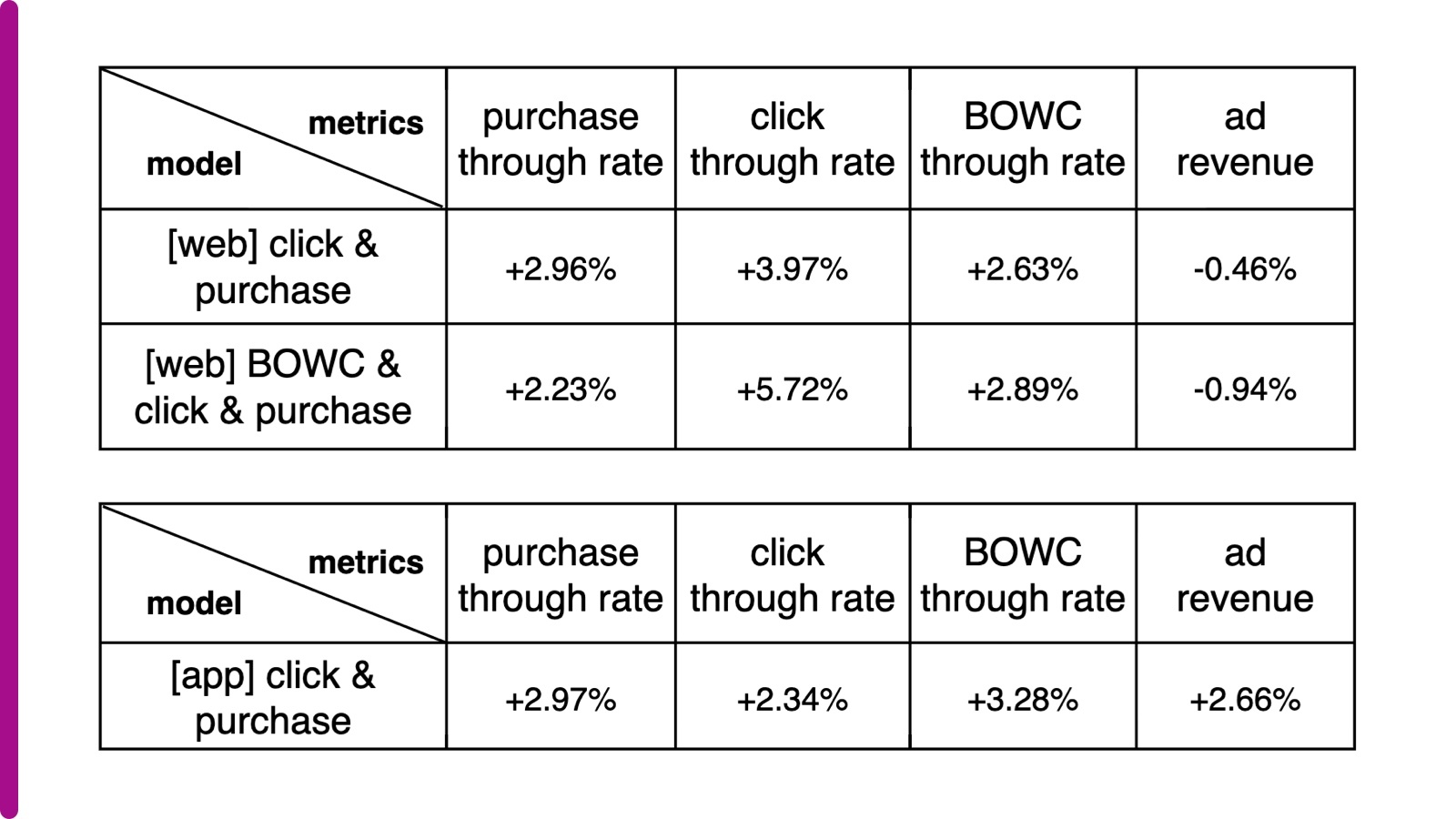
To capture the exact degree of comparative relevance, we incorporated additional weights on different labels (called “sample weights”), which were fed to the pairwise loss function. We optimized the hyperparameter tuning job and ran over 25 iterations to select the best sample weights, which are “Add to Watchlist” (6), “Add to cart” (15), “Make Offer” (38), “Buy It Now” (8), and “Purchase” (15). Without applying sample weights in the loss function, the new model performed worse than the model in production that only considers purchases, but with the tuned weights, the new model showed comparative improvement in offline evaluation as below regardless of platform (eBay mobile app or web). We also experimented with only adding a click as additional relevance feedback and applied tuned hyperparameter “Purchase” sample weight 150. The offline results are also shown below, where “BOWC” stands for the actions “Buy It Now,” “Make Offer,” “Add to Watchlist” and “Add to cart.” Purchase rank reflects the average rank of the purchased item. The smaller, the better.
Experiments and Results
Overall, as is often the case with applied machine learning, success was the result of many rounds of training and experimentation. With the experiments in various labeling schemes and hyperparameters, in total there were over 2000 instances of models trained.
The A/B tests were run into two phases. In the first phase, in which the new model only included additional selection labels, the A/B test showed a 2.97% increase in purchase count and a 2.66% lift in ad revenue on eBay mobile App, and as a result of its success has been launched into production worldwide. In the second phase, we included more actions such as “Add to Watchlist,” “Add to cart,” “Make offer” and “Buy It Now” into the model, and the A/B test showed even better engagement (e.g. more clicks and BOWCs).
The A/B test results validate that incorporating certain additional purchase intent signals as multi-relevance feedback in the model improves buyer shopping experience, balances seller velocity, and drives better conversion.
1 PLSIM surfaces both Promoted Listings Standard and Promoted Listings Express. We trained ranking models for each product separately and mixed them based on heuristic rules. This essay only focuses on improving Promoted Listings Standard ranking.
2 Optimizing Similar Item Recommendations in a Semi-structured Marketplace to Maximize Conversion: https://dl.acm.org/doi/10.1145/2959100.2959166
3 Promoted Listing Standard in eBay is Cost Per Acquisition (CPA) based, which means we don’t charge ads fee until conversions happen. Ads fee is determined by ad rate that sellers set w.r.t listing price.
4 eBay listing has three formats: Buy-It-Now (BIN) format, Auction format, and Best-Offer format. A listing could be in single format, or in more than one format.
5 Here, we ignored the “Place Bid” action on Auction listing due to data collection issues.


